Glibc堆管理机制基础
最近正在学习linux下堆的管理机制,收集了书籍和网络上的资料,以自己的理解做了整理,做个记录。如果有什么不对的地方欢迎指出!
Memory Allocator
常见的内存管理机制
- dlmalloc:通用分配器
- ptmalloc2:glibc分配器,继承自dlmalloc,并提供了多线程支持,主要研究对象。
- jemalloc:Firefox
- tcmalloc:Chrome
- 其他:编程语言内存分配及回收,比如python
- ......
malloc工作机制
第一次调用malloc
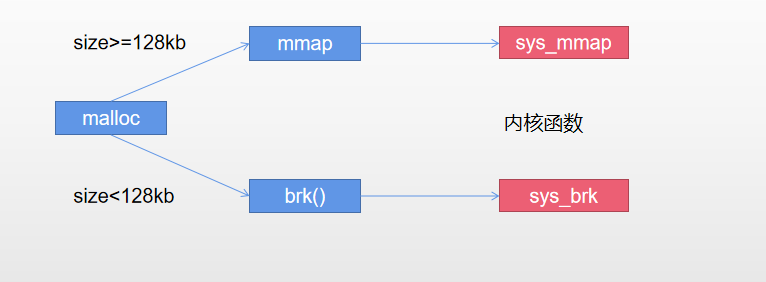
内存分配机制
头文件:#include<unistd.h>
- brk()
- 函数原型:int brk(void* end_data_segment)
- 功能和作用:用于设置program_break指向的位置。
- sbrk()
- 函数原型:void* sbrk(intptr_t increment)
- 功能和作用:同brk(),参数可以是负数。执行成功返回上一次program_break的值,可以设置参数为0返回当前的program_break.
- mmap()
- 功能和作用:当用户申请空间大于等于128kb,也就是0x20000字节时,不再使用brk()进行分配,改为使用mmap()。
- unmmap()
- 功能和作用:堆mmap()申请的空间进行回收。
内存分配图
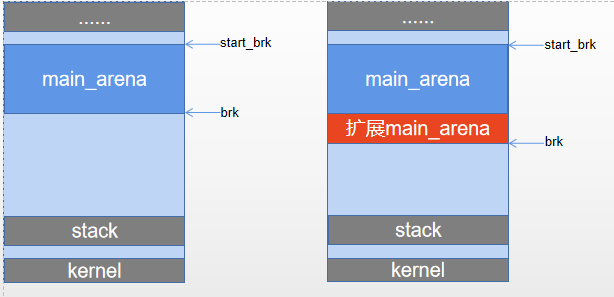
- 主线程的arena就是main_arena,包含start_brk和brk中间的连续内存,当main_arena不够分配时,会使用brk()进行扩展。
- 子线程arena可以有多片连续内存,但是大小是固定的,不可以扩展,如果不够用的话需要再次调用mmap()来分配。
第二次调用malloc
- 只要分配的空间不超过128kb,则不会再次向system申请空间,超过时才会调用brk()进行扩展。
- 即使将main_arena全部free,也不会立即把内存还给操作系统,此时内存由glib进行管理。
chunk
chunk是glibc管理内存的基本单元。主要分为以下几类:
- alloced chunk:已分配正在使用中的chunk。
- free chunk:已经free的chunk。
- top chunk:可以理解为地址的最高处,还没有分配的chunk。
- last remainder chunk:是为了提高内存分配的局部性。
chunk = chunk header + user data,malloc返回给用户的其实是user data指针,具体如下图:

alloced chunk结构
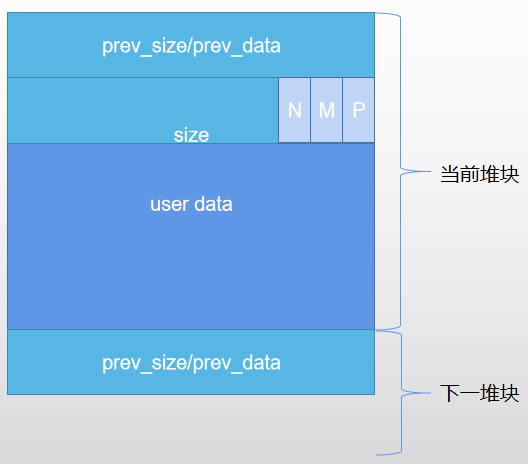
- size:本chunk的大小,包括prev,大小为8的整数倍。32位以8字节对齐,最小为0x10。64位以16字节对齐,最小为0x20。其中低三位有特殊含义,分别为N、M、P
- N位:是否属于主进程。
- M位:是否由mmap()分配。
- P位:前一堆块占用标志,1为占用,0为空闲。
- 当P位为0时,表示前一堆块释放,prev表示前一堆块的大小。当P位为1,表示前一堆块使用,prev表示前一堆块的数据。
- userdata为输入的数据。
- 将下一堆块的P位设置为1。
free chunk
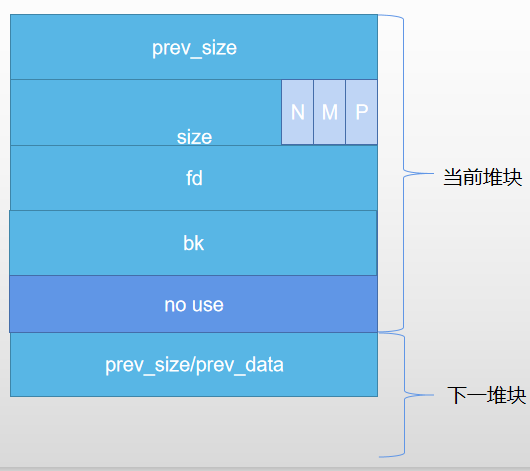
- 其中fd、bk属于链表指针,有特殊用途,后面会讲到。
- prev_size为当前释放块的大小(包含chunk header)
- 下一堆块P位通常被设置为0(fastbin除外)。
top chcunk

- 该堆块位于前两种堆块之后,头部结构与alloced相似
- size:top chunk还有多少空间可以分配。
- 重要的是P位:0表示上一堆块处于空闲,1表示上一堆块处于使用状态。主要用于判断free时是否能与上一堆块进行合并(fastbin除外)。
last remainder chunk
- 在malloc时,如果有比较大的chunk可以分配,会把这个chunk分成两部分,一部分返回给用户,另一部分称为remainder,加入到 unsorted bin,last remainder会记录最近拆分的remainder。这个remainder大小至少要为MINSIZE,否则不能拆分。
- 当下次malloc时,如果last remainder chunk够大,则重复上一过程。
- 拆分的情况:fast bin 和 small bin 都没有合适的chunk,同时unsorted bin有且只有一个可拆分的chunk,并且这个chunk 是last remainder。
堆空闲块管理结构bin
当alloced chunk被释放后,会根据大小放入bin或者合并到top chunk 中去。bin的主要作用时加快分配速度,通过链表方式(chunk中的fd和bk指针)进行管理。主要有以下几种,顾名思义:
- fast bin
- unsorted bin
- small bin
- large bin
fastbinsY:这是一个bin数组,里面有NFASTBINS个fast bin
bins:也是一个bin数组,一共有126个bin,按顺序分别是:
- bin 1 为unsorted bin
- bin 2 到 bin 63 为small bin
- bin 64 到 bin 126 为 large bin
fast bin
- 这类bin通常申请和释放的堆块都比较小,所以使用单链表结构,LIFO(后进先出)分配策略。
- 为了速度,fast bin不会进行合并,下一个chunk始终处于使用状态。
- 在fastbinsY数组里按照从小到大的顺序排列。
- 以64位为例,fast bin结构如下(大小区间0x200x80,32位为0x100x40):

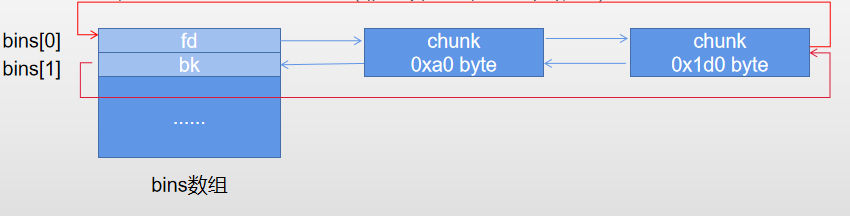
unsorted bin
- 一定大小堆块被释放时,在加入small bin 和large bin 之前,会首先加入此bin,可以加快分配速度。使用双链表结构,FIFO(先进先出)分配策略。
- unsorted bin大小可能是不相同的。
- 由于使用双链表,一个bin会占用bins的两个元素。fd指向上一个chunk,bk指向下一个。
- 以64位为例,unsorted bin结构如下(非连续内存,大小无限制):
small bin
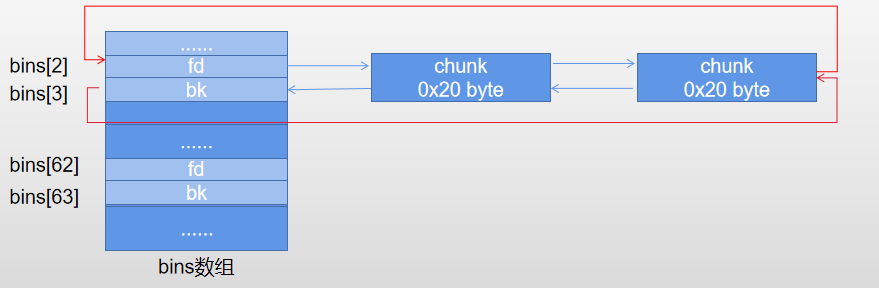
- 同一个small bin里的chunk大小相同,使用双链表结构,FIFO(先进先出)分配策略。
- 由于fast bin和small bin 有重合部分,在某些情况下会加入到small bin
- 根据大小分成62个不同的bin,0x20,0x30,0x40...0x80,0x90...1008
- 以64位为例,small bin结构如下(大小区间:size<0x400byte):
large bin
- 使用双链表结构,FIFO(先进先出)分配策略。
- free时bk后面多两个此参数:fd_nextsize、bk_nextsize。分别指向前一个和后一个large chunk。
- 根据大小分成63个不同的bin,大小不再固定。前32个bin为 0x400+64i,32-48 bin为 0x1380+512j,依此类推。并且会将大的chunk放在前面,小的放在后面,以加快速度。
- 以64位为例,large bin大小区间:size>=1024byte。32位为:size>=512byte。
- fd_nextsize和bk_nextsize指针用于指向第一个与自己大小不同的chunk,所以也只有在加入了大小不同的chunk时,这两个指针才会被修改。
随后附上glibc内存管理流程图
看不清楚可以保存下来放大。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号