hive 学习系列六 hive 去重办法的思考
方法1,建立临时表,利用hive的collect_set 进行去重。
create table if not exists tubutest (
name1 string,
name2 string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
select * from ods.wdtest;
1 1
1 1
1 2
1 2
1 3
2 3
2 3
2 4
select name1,collect_set(name2) from tubutest group by name1;
name1 _c1
1 ["2","3"]
2 ["2","4"]
create view ods.wdtestView as
select name1,collect_set(name2) as name2 from ods.wdtest group by name1;
select * from ods.wdtestview;
name1 name2
1 ["2","3"]
2 ["2","4"]
select name1, name2 from tubuview LATERAL VIEW explode(name2) tubuview as name2;
A,collect_set 完成把多行转化成一行的功能。
B,explode 完成把一行转化成多列的功能。 而 lateral view 主要是辅助 explode 进行使用,来完成类似去重的功能。
2,方法2, 利用row_number 去重
比如,我有一大堆的表格,

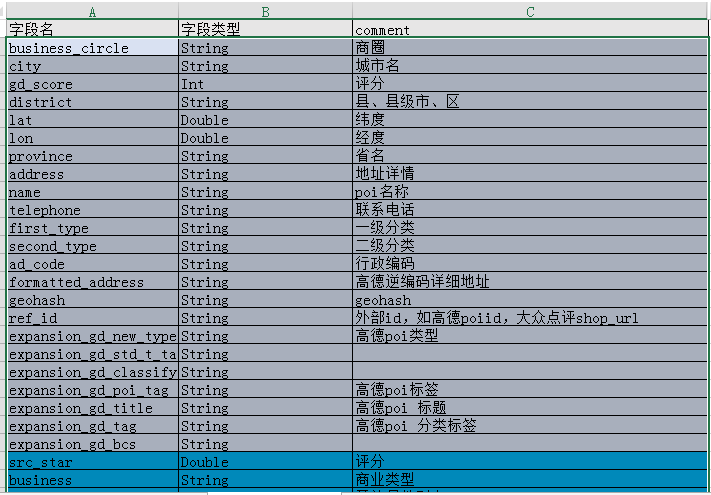
表格内容大多类似,只是有些许差别。
现在的需求是把我要统计所有的表格中,都有哪些字段,也就是把所有的表格整合成一张大表
则可以利用row_number 进行去重
最终的表格如下:
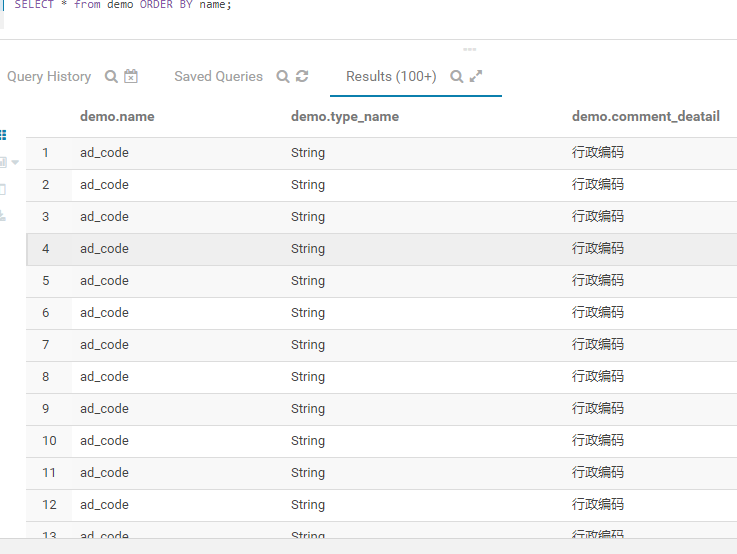
需要进行去重,
则可以利用row_number 进行去重(去虫),方法如下
SELECT
name,
type_name,
comment_deatail
from
(SELECT
name,type_name,comment_deatail,
row_number() OVER(PARTITION BY name ORDER BY type_name) as row_count
from demo) t
where row_count=1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号