

Jenkins maven 构建乱码,修改file.encoding系统变量编码为UTF-8
一切都是windows的控制台默认编码GBK问题
情景:
使用jenkins构建,console 输出的中文乱码。代码编码格式是utf-8,因为Jenkins会默认读取当前系统的编码格式,导致构建日志乱码和selenium自动化测试输入的中文乱码。
控制台输出乱码
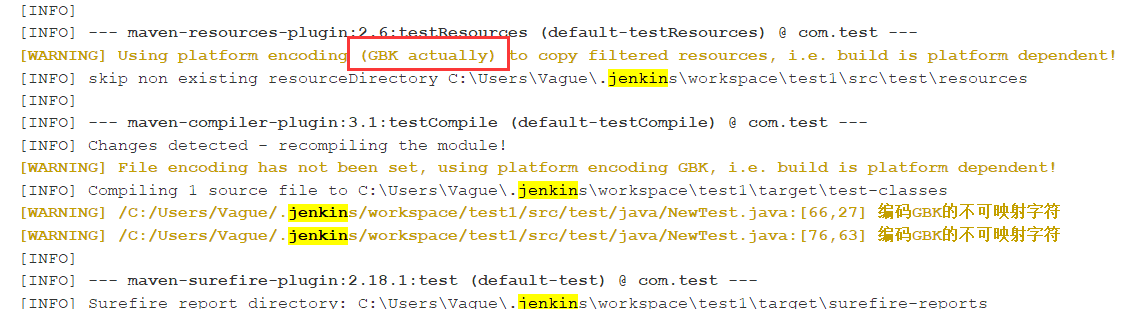
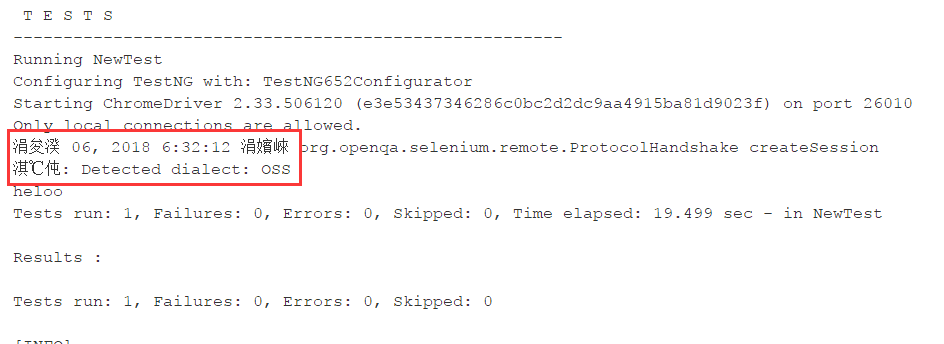
摸索
不能忍,果断百度一下,按照设置全局配置那里设置LANG :zn_CH.utf-8 无效。
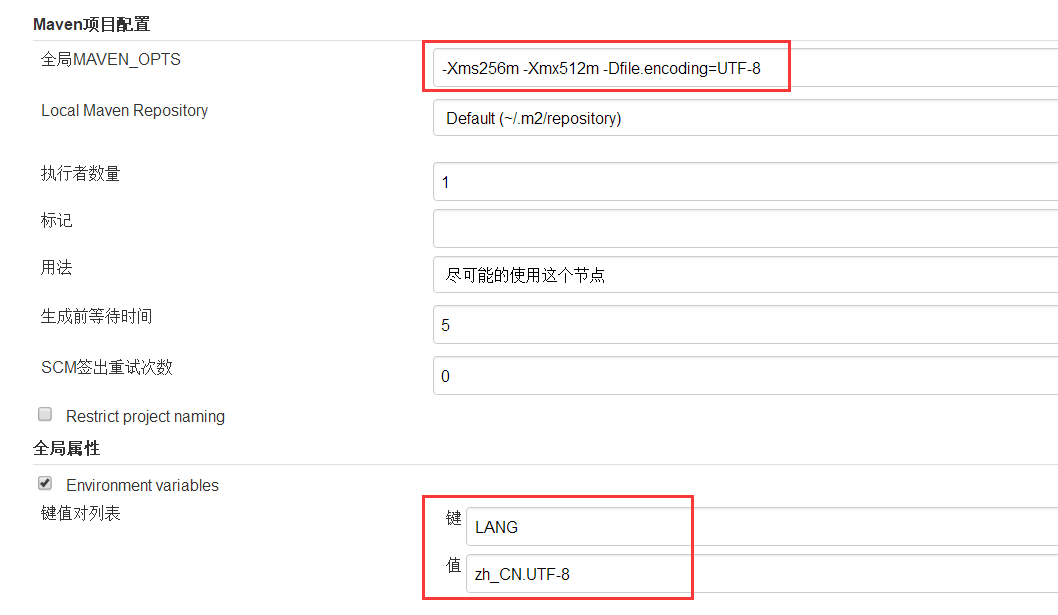
在jenkins下的jenkins.xml设置什么启动为utf-8也是无效。
但是查找资料期间发现,jenkins系统管理的系统信息
想到另一台linux下,未发现该问题,上去看看,里面有一个(大约是第三行)file.encoding UTF-8,而我本地的windows则是file.encoding GBK.
再往下拉,仔细看还有一个sun.jnu.encoding UTF-8
而我本地也是sun.jnu.encoding GBK
我觉得就是这里的问题啊。
这个是java层面的编码问题,所以在jenkins 里设置半天并没效果。
查了下java修改file.enciding UTF-8的方法。
在系统变量里添加启动参数:
1.打开环境变量设置
2.注意是新建,不是在什么path中新加,
直接新建一个变量名为JAVA_TOOL_OPTIONS
变量值为-Dfile.encoding=UTF-8
保存并重启jenkins。
再次查看我们的“系统管理”-->“系统信息”发现已经是UTF-8 了。
等等,你可能说,那个sun.jnu.encoding还没改呢。
那这俩有什么区别呢
file.encoding主要管理的是文件中的编码
sun.jnu.encoding 主要负责文件名类的编码
PS:所以这里也提示我们,如果依赖java或者其他一些环境的软件,命名及其安装路径尽量国际化一点,毕竟中文很多时候出现错误十分的恼火。
sun.jnu.encoding 的修改还没找到方法,如知道,请告知我。
重新构建一下,一半喜乐,一半忧伤。我程序中输出的中文字符正常显示了。但是,系统提示的那个“错误,该进程没有找到”的已经变成了乱码。WTF,其实不难理解,因为那个信息是windows反馈给我们的,不在我们代码中,那编码模式必然是默认的GBK,这里实在是不知道怎么去控制了。尴尬,难道就不能两全吗?!
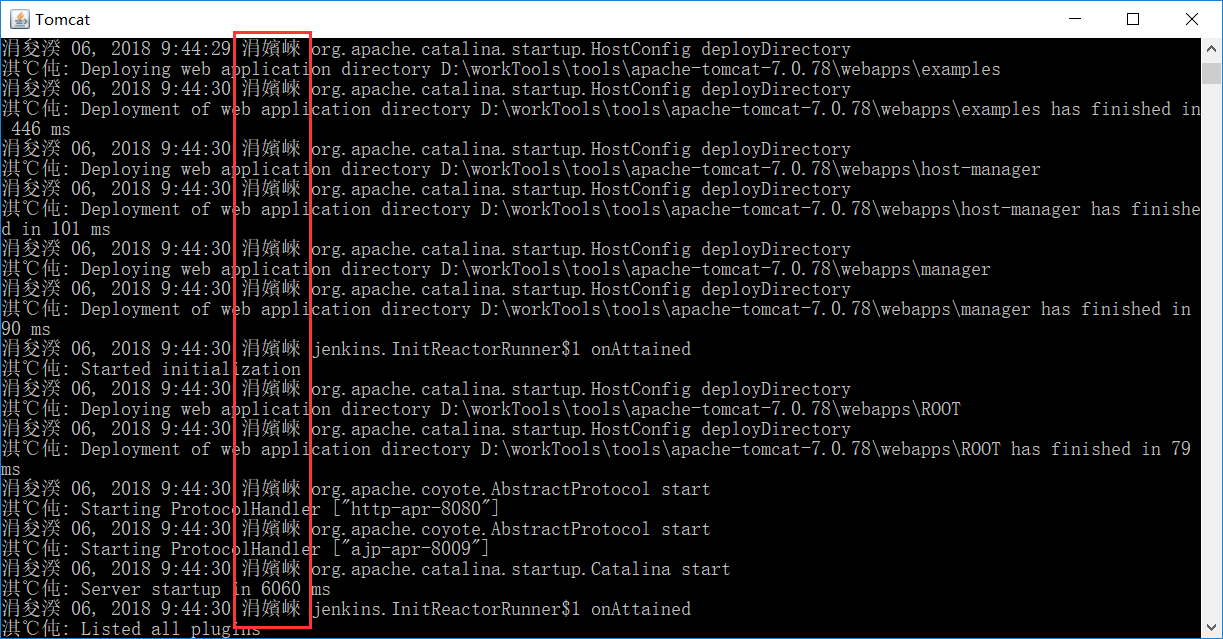
搞不动了,linux下就没这么妖了,因为默认的就都是utf-8。
参考:http://blog.csdn.net/sinat_21302587/article/details/68061204

 浙公网安备 33010602011771号
浙公网安备 33010602011771号