

代数表达式的四则运算
代数表达式的四则运算
前面我们讨论了四则运算的相关情形,对于给定的中缀表达式,我们对其进行词法分析、中缀转后缀、后缀计算等过程,最终得到中缀表达式的值。
在我们输入的中缀表达式中,我们对于每个操作数都是已知的值,不存在未知量。
而在本文中,我们是重点讨论有关中缀表达式中存在未知量的情形,我们将含有未知量的表达式称作为代数表达式。
比如给定一代数表达式:
a+b-c/d*xyz
该表达式中存在5个未知量:a、b、c、d以及xyz。我们的处理过程还是按照以前处理四则运算的情形那样,首先对输入的代数表达式进行词法分析,得到想要的操作符、已知量、未知量等。然后将中缀表达式转换为后缀表达式,最后在进行后缀表达式计算的时候,我们需要知道未知量实际的值是多少,这就需要我们对未知量指定特定的数值,最终得到代数表达式的结果。
从上面可以看出,我们的计算过程还是分为三个步骤,只是在第三个步骤计算后缀表达式的时候,我们需要对未知量指定特定的值。
一、词法分析
代数表达式中的token可以分为三种:
1.操作符:+、-、*、/、(、)
2.已知量:常数
3.未知量:开头为字母,后面可以为字母或数字
我们对token检测并存放到相应的中缀表达式中,这里没有必要对token设置其对应的种类码。
二、中缀转后缀
具体算法流程可以参照以前的,关键是要设置一个操作符栈。
三、后缀的计算
设置一个操作数栈,对于未知量需要指定其特定数值。
多说无益,下面我们给出代数表达式四则运算的程序:

// 代数表达式的四则运算 #include <iostream> #include <vector> #include <map> #include <stack> #include <string> #include <cctype> #include <cassert> using namespace std; bool is_blank(char ch) { return ch == ' ' || ch == ' ' || ch == '\n'; } void lexer(const string& algexp, vector<string>& infix) { infix.clear(); char ch; for (auto i = 0; i < algexp.size(); /*++i*/) { if (is_blank(algexp[i])) { ++i; continue; } string token; ch = algexp[i]; if (isalpha(ch)) // 未知量 { token += ch; ++i; if (i >= algexp.size()) // 扫描结束 { infix.push_back(token); return; } ch = algexp[i]; while (isalnum(ch)) { token += ch; ++i; if (i >= algexp.size()) // 扫描结束 { infix.push_back(token); return; } ch = algexp[i]; } infix.push_back(token); } else if (isdigit(ch)) { token += ch; ++i; if (i >= algexp.size()) // 扫描结束 { infix.push_back(token); return; } ch = algexp[i]; while (isdigit(ch)) { token += ch; ++i; if (i >= algexp.size()) // 扫描结束 { infix.push_back(token); return; } ch = algexp[i]; } infix.push_back(token); } else { switch (ch) { case '+': case '-': case '*': case '/': case '(': case ')': token += ch; infix.push_back(token); ++i; break; default: ++i; break; } } } } bool is_operator(const string& str, const map<string, int>& optors) { auto cit = optors.find(str); if (cit != optors.end()) { return true; } else { return false; } } bool is_uncertain(const string& str) { assert(!str.empty()); if (isalpha(str[0])) { return true; } else { return false; } } void in_to_post(const vector<string>& infix, vector<string>& postfix, map<string, double>& unk_num, map<string, int>& optors) { postfix.clear(); unk_num.clear(); stack<string> op_st; for (auto i = 0; i < infix.size(); ++i) { if (!is_operator(infix[i], optors)) { postfix.push_back(infix[i]); if (is_uncertain(infix[i])) { unk_num[infix[i]] = 0.0; } } else { if (infix[i] == "(") { op_st.push(infix[i]); } else if (infix[i] == ")") { while (!op_st.empty()) { string tmp = op_st.top(); if (tmp == "(") { op_st.pop(); break; } else { postfix.push_back(tmp); op_st.pop(); } } } else // 加减乘除运算符 { if (op_st.empty()) { op_st.push(infix[i]); } else { string tmp = op_st.top(); if (optors[infix[i]] > optors[tmp]) { op_st.push(infix[i]); } else { while (!op_st.empty()) { tmp = op_st.top(); if (tmp == "(") { break; } else if (optors[tmp] >= optors[infix[i]]) { postfix.push_back(tmp); op_st.pop(); } else { break; } } op_st.push(infix[i]); } } } } } while (!op_st.empty()) { postfix.push_back(op_st.top()); op_st.pop(); } } bool is_unknown(const string& str, const map<string, double>& unk_num) { auto cit = unk_num.find(str); if (cit != unk_num.end()) { return true; } else { return false; } } double cal_postfix(const vector<string>& postfix, const map<string, int>& optors, map<string, double>& unk_num) { double ret = 0.0; stack<double> oe_st; for (auto i = 0; i < postfix.size(); ++i) { if (!is_operator(postfix[i], optors)) { if (is_uncertain(postfix[i])) { oe_st.push(unk_num[postfix[i]]); } else { oe_st.push(static_cast<double>(atof(postfix[i].c_str()))); } } else { double a(0.0), b(0.0), c(0.0); switch (postfix[i][0]) // 需要虚拟机技术啊 { case '+': b = oe_st.top(); oe_st.pop(); a = oe_st.top(); oe_st.pop(); c = a + b; oe_st.push(c); break; case '-': b = oe_st.top(); oe_st.pop(); a = oe_st.top(); oe_st.pop(); c = a - b; oe_st.push(c); break; case '*': b = oe_st.top(); oe_st.pop(); a = oe_st.top(); oe_st.pop(); c = a * b; oe_st.push(c); break; case '/': b = oe_st.top(); oe_st.pop(); a = oe_st.top(); oe_st.pop(); c = a / b; oe_st.push(c); break; default: break; } } } ret = oe_st.top(); oe_st.pop(); return ret; } void display(const vector<string>& fix) { for (auto i = 0; i != fix.size(); ++i) { cout << fix[i] << ' '; } cout << endl; } void init_operators(map<string, int>& optors) { optors.clear(); optors["+"] = 100; optors["-"] = 100; optors["*"] = 200; optors["/"] = 200; optors["("] = 500; optors[")"] = 000; } void input_unknown(map<string, double>& unk_num) { cout << "Unknowns:" << endl; for (auto cit = unk_num.begin(); cit != unk_num.end(); ++cit) { cout << cit->first << ' '; } cout << endl; cout << "Input unknowns:" << endl; for (auto cit = unk_num.begin(); cit != unk_num.end(); ++cit) { double tmp; cout << cit->first << ':'; cin >> tmp; cit->second = tmp; } } void display_known(const vector<string>& infix, map<string, double>& unk_num) { for (auto i = 0; i < infix.size(); ++i) { if (is_uncertain(infix[i])) { cout << unk_num[infix[i]] << ' '; } else { cout << infix[i] << ' '; } } cout << endl; } void get_infix(string& algexp) { cin.sync(); // 清空缓冲 // fflush(stdin); algexp.clear(); getline(cin, algexp); } int main() { map<string, int> optors; init_operators(optors); while (true) { string algexp; get_infix(algexp); vector<string> infix; lexer(algexp, infix); display(infix); vector<string> postfix; map<string, double> unk_num; in_to_post(infix, postfix, unk_num, optors); display(postfix); if (!unk_num.empty()) { input_unknown(unk_num); display_known(infix, unk_num); } double ret = cal_postfix(postfix, optors, unk_num); cout << ret << endl << endl; } return 0; }
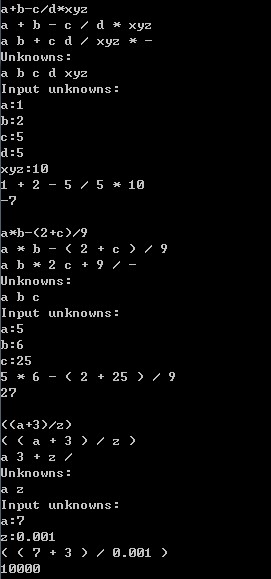
在程序的处理过程中,我们只是默认对正确的代数表达式进行处理,针对三个阶段的异常并未作出相关的处理。
有关异常情况的处理,我们可以用笨的方法进行硬分析,但是这种方法就是添加标识、考虑更可能多的情况。这种方法并不是最好的办法,只是说白了是苦力活。更好的方法是设计良好的数据结构,利用更有的算法,记住编译原理方面的技术进行分析。对于第一个方法我们不再做了,第二个方法有待我们进一步了解编译原理相关方面的内容。
另外,在程序中关于根据加减乘除四种运算符的运算,我们是直接判断运算符,用的switch-case语句来进行的。更好的方法应该利用虚拟机技术,来完成运算符的运算操作。
整体上,上面的程序就是分为三个部分:
1.代数式的词法分析:lexer
2.中缀转后缀:in_to_post
3.后缀的计算:cal_post
在中缀转后缀的过程中,我们记录了代数式中的未知量,并在转换后,对未知量进行赋值。在后缀的计算过程中,我们根据未知量复制后的值进行运算操作,最终得到代数式的运算结果。
(完)
文档信息
·版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0
·博客地址:http://www.cnblogs.com/unixfy
·博客作者:unixfy
·作者邮箱:goonyangxiaofang(AT)163.com
·如果你觉得本博文的内容对你有价值,欢迎对博主 小额赞助支持



【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· dotnet 源代码生成器分析器入门
· ASP.NET Core 模型验证消息的本地化新姿势
· 对象命名为何需要避免'-er'和'-or'后缀
· SQL Server如何跟踪自动统计信息更新?
· AI与.NET技术实操系列:使用Catalyst进行自然语言处理
· dotnet 源代码生成器分析器入门
· 官方的 MCP C# SDK:csharp-sdk
· 一款 .NET 开源、功能强大的远程连接管理工具,支持 RDP、VNC、SSH 等多种主流协议!
· 提示词工程师自白:我如何用一个技巧解放自己的生产力
· 一文搞懂MCP协议与Function Call的区别