
[排错] VO对象和POJO对象的关系
这或许是一个很蠢的笔记吧......
这次项目中, 作为一个新人, 没少被这两个概念虐得死去活来的, 现在特别做一次记录, 关于它们二者之间在项目中的应用.
在这里呢, 就不再赘述 VO(view object) 对象 和 POJO 是什么了, 这两个网上是有很多介绍的了, 好的, 话不多说, 直奔主题.
背景: 从数据库中查询出某一天中24个小时的数据, 也就是 日期的查询参数是 yyyy-MM-dd ,可以查询到 [0--23] 24个小时的数据
一开始博主的想法是, 在数据中, 将 yyyy-MM-dd HH-mm-ss 拆分成 yyyy-MM-dd 和 HH-mm-ss 两个部分, 但是这会造成一个问题, 因为项目需要, 日期是作为主键存在的, 这样的话会出现问题,
那么就只能换一种方法来自解决问题, 那就是时间的格式不变的情况下, 才采用 MySQL 数据库自带的 DATE_FORMAT 函数,
假设有这样的三条数据:[ id yyyy-MM-dd HH-mm-ss info ]
[ id yyyy-MM-dd HH-mm-ss info ]
[ id yyyy-MM-dd HH-mm-ss info ]
然后我们在 mapper.xml 中这样查询 SELECT * FROM tbaleName WHERE DATE_FORMAT(record_date) = #{date}
对应的数据映射接口中 mapper.java 这样设计接口 List<POJO> query (PojoKey pojoKey); 因为我们是一次性查询出3条数据, 或者是 24条数据
然后就开始精彩的部分了, 因为我们要直接在页面上展示的格式为 : 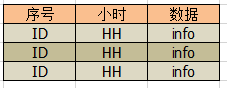
POJO 是作为对应数据源对象而存在的, 博主之前一直以为数据从数据库中查询出来以后, 是保存到 POJO 里面的, 但是, POJO 里的属性只是对应着数据库的数据字段的别名[这里, 还是很可疑, 不是很确定],
所有数据库表中有哪些字段, POJO 里就要有哪些数据类型对应, 且命名一致的属性, 并且添加对应的 get/set 方法, 但是仅仅是这样是不够的, 看看表里的数据和页面上所需要展示的数据是不一样的, 所以, 我们需要在 VO 中做一些操作.
但是在操作之前, 我们需要先有一个 service 层的类 Service.java 别忘了加上 @Service, 在 service 中添加一个方法, 用于向 controller 层返回数据, 返回值的格式根据项目需求自己定义 ( 这里我们定义方法的签名为 public List(VO) getInfo (Type param), 然后调用数据映射接口的 bean , 遍历 Liset<POJO> 中的每一条数据, 由于 POJO 作为数据源的对象, 所以在 service 层可以使用
List<POJO> getMapperInfo = mapperBean.query(param); // 调用执行SQL语句, 获取DB中的数据,
List<VO> viewInfoList = new ArrayList<>(0); //创建一个 VO 类型的集合, 用于保存多条计算加工后的 POJO 对象的数据
 ( 其中 changeDataFunction 就是 VO 对象中的静态方法, 这里有一个疑问就是, 如果去掉修饰 changeDataFunction 的 static 关键字, 那么方法所 set 的数据, 将 无法修改 VO 类中的属性值? 为什么?)
( 其中 changeDataFunction 就是 VO 对象中的静态方法, 这里有一个疑问就是, 如果去掉修饰 changeDataFunction 的 static 关键字, 那么方法所 set 的数据, 将 无法修改 VO 类中的属性值? 为什么?)
这样, 再 return viewInfoList; 就大功告成了, controller 层的代码几乎可以忽略.
大致思路已经讲完, 那么相信对 POJO 和 VO 对象的用法和区别已经有了已经初步的认识了吧.
简单来说, POJO 对象就是对应着数据表的字段类, 由于在查询的时候我们要使用到查询参数 , 所以对于主键字段, 博主还是建议单独抽出来建一个 PojoKey 对象要友好一些, 毕竟对于多主键同时查询的时候, 也会方便代码的维护.
而 VO 对象, 就是为页面数据服务的对象, 它存在的意义就是帮助 controller 层将从 DataSource 里拿到数据经过 POJO 的整理后 进一步的 按照页面展示的数据需求对数据进行加工, 最后经由 service 返回给 controller 层, 最后填充到页面表格中.
所以说 POJO 是面对 mapper 映射层 和 service 服务层的, 而 VO 是面对 service 服务层和 controller 控制层, 博主之前犯的最大的一个错误就是将 VO 和 POJO 的位置和定位搞混, 一直想着怎么直接在 POJO 中操作完数据然后传入 VO 中, 最后返回给 controller, 这其实就是因为博主将目光只停留在了数据层, 而没有通过需求从整体上来看代码.
所以说在一开始接到一个项目的时候, 正确的操作流程应该是:
[1] 确定需求, 理解需求, 保证开发和QA的思路是大致在一条线上的, 也要保证自己真的明白了需求的目的;
[2] 确定技术选型, 设计数据源(这一步其实挺关键), 在理解需求的前提下降数据库表设计完成(包括数据类型, 还有对 增删改查 操作时的友好度);
[3] 简单的画一个 UML流程图, 再配上简单的几行伪码, 大致考虑一下整个需求的运行情况, 要可以预想到哪里容易出BUG, 哪里可以继续优化, 哪里可以应对更多的需求变化,,等等;
[4] 这里就可以开始一脸自信的写BUG了(滑稽),
[5] 工作日常  哈哈,其实前期的准备和设计是非常重要的, 就在博主做的这个需求中, 一个星期的时间, 其实真正花在 coding 上的时间并不多, 而这宝贵的时间都浪费在由于前期设计不足而导致的种种纠结
哈哈,其实前期的准备和设计是非常重要的, 就在博主做的这个需求中, 一个星期的时间, 其实真正花在 coding 上的时间并不多, 而这宝贵的时间都浪费在由于前期设计不足而导致的种种纠结
嘤嘤嘤,,,,,其实我有想过贴代码啦, 不过,, 我认为编程中最重要的思路, 代码,其实真的不难的好伐, 只要思路确定了, 剩下的就只是变态的性能优化了, 这一点只能靠自己的努力或者说经验了, 第一篇博文,,,,哇,满满 的成就感
如果有小伙伴看到这里,,非常感谢,,也欢迎各位大佬提出建议和意见 ~~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号