Kruskal算法(~详细整理,简单易懂,附最全注释代码实现)
Kruskal算法
1、简介
Kruskal算法是一种用来查找最小生成树( M S T MST MST)的算法,由Joseph Kruskal在1956年发表。求最小生成树的算法常用有两种:Kruskal算法和Prim算法。这里指路一篇Prim算法的详解blog:https://blog.csdn.net/hzf0701/article/details/107927858。与Prim算法不同的是,该算法的核心思想是归并边,而Prim算法的核心思想是归并点。这里我们会在后面的实现过程中看到。
2、构造过程
假设连通网
N
=
(
V
,
E
)
N=(V,E)
N=(V,E),将
N
N
N中的边按权值从小到大的顺序排列。
①初始状态为只有
n
n
n个顶点而无边的非连通图
T
=
(
V
,
{
}
)
T=(V,\{\})
T=(V,{}),图中每个顶点自成一个连通分量。
②在
E
E
E中选择权值最小的边,若该边依附的顶点落在
T
T
T中不同的连通分量上(即不形成回路),则将此边将入到
T
T
T中,否则舍去此边而选择下一条权值最小的边。
③重复②,直到
T
T
T中所有的顶点都在同一连通分量上为止。
这个算法的构造过程十分简洁明了,那么为什么这样的构造过程能否形成最小生成树呢?我们来看第二个步骤,因为我们选取的边的顶点是不同的连通分量,且边权值是最小的,所以我们保证加入的边都不使得 T T T有回路,且权值也最小。这样最后当所有的连通分量都相同时,即所有的顶点都在生成树中被连接成功了,我们构造成的树也就是最小生成树了。
3、示例
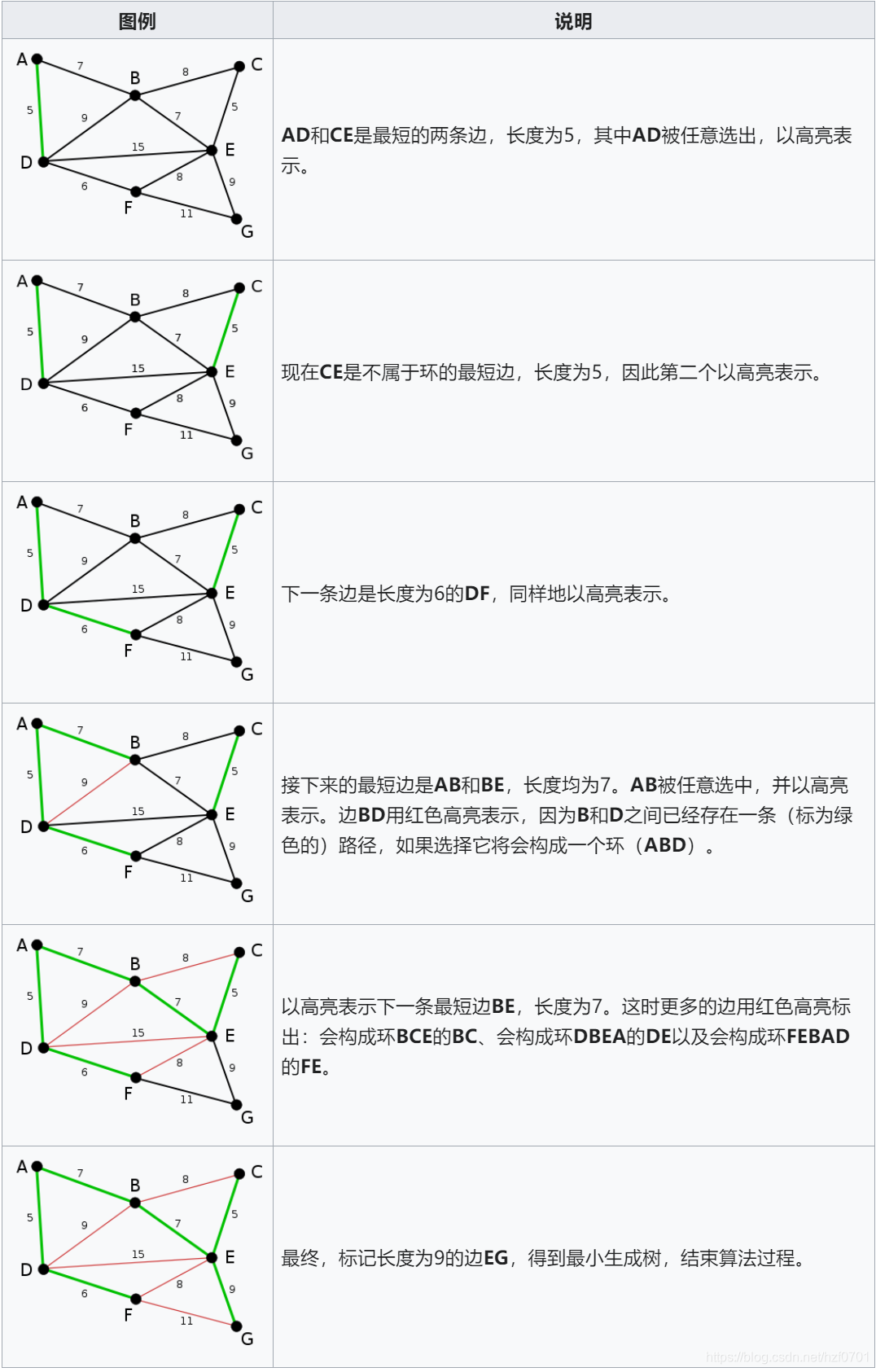
4、算法实现
步骤:
①将存储边的数组temp按权值从小到大排序,注意进行运算符重载。
②初始化连通分量数组
v
e
r
x
verx
verx。
③依次查看数组temp的边,循环执行以下操作。
- 依次从排好序的数组temp中选出一条边 ( u , v ) (u,v) (u,v);
- 在
v
e
r
x
verx
verx中分别查找
u
u
u和
v
v
v所在的连通分量
v
1
和
v
2
v_1和v_2
v1和v2,进行判断。
- 如果 v 1 v_1 v1和 v 2 v_2 v2不等,说明所选的两个顶点分别属于不同的连通分量,则将此边存入最小生成树 t r e e tree tree,并合并 v 1 v_1 v1和 v 2 v_2 v2这个两个连通分量。
- 如果 v 1 v_1 v1和 v 2 v_2 v2相等,则说明所选的两个顶点属于同一个连通分量,舍去此边而选择下一条权值最小的边。
/*
*邮箱:unique_powerhouse@qq.com
*blog:https://me.csdn.net/hzf0701
*注:文章若有任何问题请私信我或评论区留言,谢谢支持。
*
*/
#include<bits/stdc++.h> //POJ不支持
#define rep(i,a,n) for (int i=a;i<=n;i++)//i为循环变量,a为初始值,n为界限值,递增
#define per(i,a,n) for (int i=a;i>=n;i--)//i为循环变量, a为初始值,n为界限值,递减。
#define pb push_back
#define IOS ios::sync_with_stdio(false);cin.tie(0); cout.tie(0)
#define fi first
#define se second
#define mp make_pair
using namespace std;
const int inf = 0x3f3f3f3f;//无穷大
const int maxn = 1e5;//最大值。
typedef long long ll;
typedef long double ld;
typedef pair<ll, ll> pll;
typedef pair<int, int> pii;
//*******************************分割线,以上为自定义代码模板***************************************//
struct edge{
int s;//边的起始顶点。
int e;//边的终端顶点。
int w;//边权值。
bool operator < (const edge &a){
return w<a.w;
}
};
edge temp[maxn];//临时数组存储边。
int verx[maxn];//辅助数组,判断是否连通。
edge tree[maxn];//最小生成树。
int n,m;//n*n的图,m条边。
int cnt;//统计生成结点个数,若不满足n个,则生成失败。
int sum;//最小生成树权值总和。
void print(){
//打印最小生成树函数。
cout<<"最小生成树的权值总和为:"<<sum<<endl;
rep(i,0,cnt-1){
cout<<tree[i].s<<" "<<tree[i].e<<"边权值为"<<tree[i].w<<endl;
}
}
void Kruskal(){
rep(i,1,n)
verx[i]=i;//这里表示各顶点自成一个连通分量。
cnt=0;sum=0;
sort(temp,temp+m);//将边按权值排列。
int v1,v2;
rep(i,0,m-1){
v1=verx[temp[i].s];
v2=verx[temp[i].e];
if(v1!=v2){
tree[cnt].s=temp[i].s;tree[cnt].e=temp[i].e;tree[cnt].w=temp[i].w;//并入最小生成树。
rep(j,1,n){
//合并v1和v2的两个分量,即两个集合统一编号。
if(verx[j]==v2)verx[j]=v1; //默认集合编号为v2的改为v1.
}
sum+=tree[cnt].w;
cnt++;
}
}
//结束双层for循环之后得到tree即是最小生成树。
print();
}
int main(){
//freopen("in.txt", "r", stdin);//提交的时候要注释掉
IOS;
while(cin>>n>>m){
int u,v,w;
rep(i,0,m-1){
cin>>u>>v>>w;
temp[i].s=u;temp[i].e=v;temp[i].w=w;
}
Kruskal();
}
return 0;
}
5、算法分析
对于有 m m m条边和 n n n个顶点的图。在 f o r for for循环中最耗时的操作就是合并两个不同的连通分量,第一个循环语句的频度为 m m m,第二个循环由于存在 i f if if语句,所以平均频度是 l o g 2 n log_2n log2n,所以该算法的平均时间复杂度为 O ( m l o g 2 n ) O(mlog_2n) O(mlog2n),故和Prim算法相比,此算法适合用于稀疏图。
6、测试
以示例数据为测试样例:
7 11
1 2 7
1 4 5
2 4 9
2 3 8
2 5 7
4 5 15
4 6 6
6 7 11
5 6 8
5 7 9
3 5 5
测试结果如图:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!