Python【第五篇】模块、包、常用模块
一、模块(Module)
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块的好处
- 最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
- 使用模块还可以避免函数名和变量名冲突。每个模块有独立的命名空间,因此相同名字的函数和变量完全可以分别存在不同的模块中,所以,我们自己在编写模块时,不必考虑名字会与其他模块冲突
模块分类
模块分为三种:
- 内置标准模块(又称标准库)执行help('modules')查看所有python自带模块列表
- 第三方开源模块,可通过pip install 模块名 联网安装
- 自定义模块
模块调用
import module from module import xx from module.xx.xx import xx
注意:模块一旦被调用,即相当于执行了另外一个py文件里的代码
模块安装
最常用的模块安装方式就是pip安装了,python3 -m pip install 模块名
模块被安装在python安装目录下的Lib\site-packages,比如我的安装在这个目录:C:\Python36\Lib\site-packages
如果是因为网速问题,超时了,可以加大pip安装时候的超时时间,设置为1000秒,pip --default-timeout=1000 install selenium==2.53.6
当然,我们也可以更换模块安装源:
pip3 install --index-url https://pypi.douban.com/simple selenium==2.53.6
python3 -m pip install --index-url https://pypi.doubanio.com/simple/ flask --trusted-host pypi.douban.com
python3 -m pip install -i https://pypi.doubanio.com/simple/ flask --trusted-host pypi.douban.com
二、包(Package)
当你的模块文件越来越多,就需要对模块文件进行划分,比如把负责跟数据库交互的都放一个文件夹,把与页面交互相关的放一个文件夹
.
└── my_project
├── mobileBank #代码目录
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── my_proj #配置文件目录
├── settings.py
├── urls.py
└── wsgi.py
像上面这样,一个文件夹管理多个模块文件,这个文件夹就被称为包;
注意,在python3里,即使目录下没__int__.py文件也能创建成功,猜应该是解释器优化所致,但创建包还是要记得加上这个文件吧。
根据上面的结构,如何实现在crm/views.py里导入proj/settings.py模块?直接导入的话,会报错,说找到不模块。
添加环境变量,把父亲级的路径添加到sys.path中,就可以了,这样导入 就相当于从父亲级开始找模块了。
import sys ,os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #__file__的是打印当前被执行的模块.py文件相对路径,注意是相对路径 print(BASE_DIR) sys.path.append(BASE_DIR)
三、常用模块
os
os 模块提供了很多允许你的程序与操作系统直接交互的功能
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径(其实是py解释器启动的目录)
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.'),注意,os.curdir后面没有括号
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录,os.makedirs('dirname1\dirname2') 也可以,但是最好前面加上r
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.walk和os.listdir的结果一样(目录在只有文件,包含目录的情况待测试)
os.walk() 通过在目录树种游走输出在目录中的文件名,向上或者向下。产生一个三个元素的元组 (dirpath, dirnames, filenames),分别是文件夹路径, 文件夹名字, 文件名,
os.remove() 删除一个文件,参数写上文件路径
os.rename("oldname","newname") 重命名文件/目录,和os.renames("oldname","newname")、os.replace("oldname","newname")功能相同,相当于可以实现文件的重命名,文件的移动,文件的移动并重命名,
os.rename(r'F:\practice\m2\123-2.txt', r'F:\practice\m1\123.txt')
os.stat('path/filename') 获取文件/目录信息,返回一个类,其中文件大小属性是filesize,和getsize一样,得到的是文件的字节数
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符(换行),win下为"\r\n",Linux和MAC下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为分号;,Linux下为冒号:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示,如os.system('dir'),命令执行成功,在结果下还会返回0,命令执行不成功,返回非0
os.getenv('HOME') 读取操作系统环境变量HOME的值
os.environ 获取系统环境变量
os.environ.setdefault('HOME','/home/wgy') 设置系统环境变量,仅程序运行时有效
os.chmod(file) 修改文件权限与时间戳
os.get_terminal_size() 获取当前终端的大小,调整终端窗口大小,行列值跟着变化
os.kill(10884,signal.SIGKILL) 杀死进程10884
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.isabs(path) 如果path是绝对路径,返回True,windows有多个根,比如c:\,d:\,linux只有一个根/
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isfile(path) 如果path是一个存在的文件,返回True,否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间,返回时间戳
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间,返回时间戳
os.path.getsize(path) 返回path的大小(返回的是文件中字节个数,数字和英文是1个字节,中文是3个字节)
sys
sys.exit(n) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解释程序的版本信息
sys.maxint # 最大的Int值(py2),py3中为sys.maxsize
sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform # 返回操作系统平台名称
sys.stdout.write('please:') # 标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
sys.stdin.read() # 会一直等待用户输入,哪怕用户输入了,只能ctrl+c结束
sys.getrecursionlimit() # 获取最大递归层数
sys.setrecursionlimit(1200) # 设置最大递归层数
sys.getdefaultencoding() # 获取解释器默认编码
sys.getfilesystemencoding # 获取内存数据存到文件里的默认编码
sys.modules # 是一个dictionary,表示系统中所有可用的module,面向对象中, 反射会用到
time
在Python中,通常有这几种方式来表示时间:时间戳、格式化的时间字符串、元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。
几个定义:
UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8。DST(Daylight Saving Time)即夏令时。
时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
元组(struct_time)方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
索引(Index) 属性(Attribute) 值(Values) 0 tm_year(年) 比如2011 1 tm_mon(月) 1 - 12 2 tm_mday(日) 1 - 31 3 tm_hour(时) 0 - 23 4 tm_min(分) 0 - 59 5 tm_sec(秒) 0 - 61 6 tm_wday(weekday) 0 - 6(0表示周日) 7 tm_yday(一年中的第几天) 1 - 366 8 tm_isdst(是否是夏令时) 默认为-1

常用方法
time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 time.time():返回当前时间的时间戳。 time.mktime(t):将一个struct_time转化为时间戳。 time.sleep(secs):线程推迟指定的时间运行。单位为秒。 time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:'Wed Jun 14 12:36:17 2017'。如果没有参数,将会将time.localtime()作为参数传入。 time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。 time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
示例:
import time
print(time.time())
print(time.ctime())
print(time.localtime())
print(time.strftime('%Y_%m_%d %H:%M:%S'))
1497414977.1362307
Wed Jun 14 12:36:17 2017
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=14, tm_hour=12, tm_min=36, tm_sec=17, tm_wday=2, tm_yday=165, tm_isdst=0)
2017_06_14 12:36:17
datetime
相比于time模块,datetime模块的接口则更直观、更容易调用
datetime.date:表示日期的类。常用的属性有year, month, day; datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond; datetime.datetime:表示日期时间。 datetime.timedelta:表示时间间隔,即两个时间点之间的长度。 datetime.tzinfo:与时区有关的相关信息。
random
程序中有很多地方需要用到随机字符,比如登录网站的随机验证码,通过random模块可以很容易生成随机字符串。
import random
print(random.random()) # (0,1)----float 大于0且小于1之间的小数
print(random.randint(1, 3)) # [1,3] 大于等于1且小于等于3之间的整数,包含3
print(random.randrange(1, 3)) # [1,3) 大于等于1且小于3之间的整数,不包含3
print(random.choice([1, '23', [4, 5]])) # 1或者23或者[4,5],返回一个给定数据集合中的随机元素
print(random.choice('abcde'))
print(random.sample([1, '23', [4, 5]], 2)) # 列表元素任意2个组合,返回一个列表
print(random.sample('python', 3)) # 返回一个列表
'''
0.8069726390185565
2
1
1
d
[[4, 5], '23']
['y', 'p', 'o']
'''
hashlib
hashlib是一个加密模块,提供了常见的加密算法,比如MD5,SHA1,SHA256等,它通过一个函数,把任意长度的数据转换为一个长度固定的数据串,常用来保存密码等,比如将用户的密码用MD5加密后,保存到数据库,用户登录时先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明密码输入正确,如果不一致,密码肯定错误。
import hashlib
passwd = hashlib.sha256()
passwd.update('123456'.encode('utf-8')) # 假设密码是123456 将其转换为字节,传入函数
print(passwd.hexdigest()) # 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
passwd = hashlib.sha256('UncleYong'.encode('utf-8')) # 对原始密码加一个复杂字符串来提高安全性,俗称“加盐”
print(passwd.hexdigest()) # 66d184cfeedb54b8f0e7819e01a2ab28ec7038ff7677716740c7e0d1962f84b1
passwd.update('123456'.encode('utf-8')) # d217b3c0f274dbaf8fe145df567a9f53df056527d01b541bb1a6997373485f26
print(passwd.hexdigest())
re
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是re
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾, 若指定flags MULTILINE ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1
'*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa'
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次 ,re.search('b?','jack').group() 匹配b 0次
'{m}' 匹配前一个字符m次 ,re.search('b{3}','jackxbbbs').group() 匹配到'bbb'
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45'
'\A' 只从字符开头匹配,re.search("\Aabc","jackabc") 是匹配不到的,相当于re.match('abc',"jackabc") 或^
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
json
如果要在不同的平台间传递信息的话,就可以用到Json模块,json用于字符串 和 python数据类型间进行转换,只能支持int\str\list\tuple\dict
json提供了四个功能:dumps、dump、loads、load
json:dumps & loads
import json
data = {'k1':123,'k2':'Hello'}
# json.dumps 将数据通过特殊的形式转换为所有程序语言都认识的字符串
j_str = json.dumps(data)
print(j_str, type(j_str))
res = json.loads(j_str)
print(res, type(res))
'''
{"k1": 123, "k2": "Hello"} <class 'str'>
{'k1': 123, 'k2': 'Hello'} <class 'dict'>
'''
json:dump
import json
data = {'k1':123,'k2':'Hello'}
# json.dump 将数据通过特殊的形式转换为所有程序语言都认识的字符串,并写入文件
json.dump(data,open('D:/result.json','w'))
json:load
import json
res = json.load(open('D:/result.json', 'r'))
print(res,type(res))
'''
{'k1': 123, 'k2': 'Hello'} <class 'dict'>
'''
logging
logging是用来纪录日志的模块,可以自动帮我们纪录程序运行中出现的错误,出了问题可以方便我们后来去日志中查找原因,在实际开发中非常好用。
日志级别

日志格式
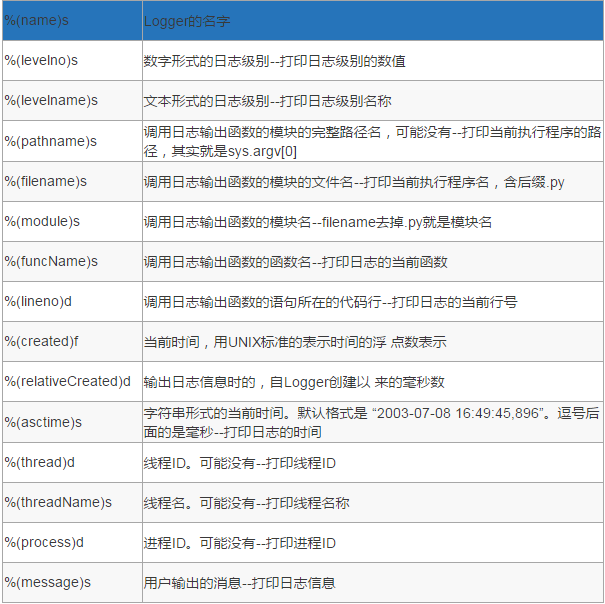
import logging
class IgnoreBackupLogFilter(logging.Filter):
def filter(self, record): # 固定写法
return "db backup" not in record.getMessage()
logger = logging.getLogger('my_log')
logger.addFilter(IgnoreBackupLogFilter())
sh = logging.StreamHandler()
sh.setLevel(logging.INFO)
fh = logging.FileHandler('test.log', mode='a', encoding='utf-8')
fh.setLevel(logging.INFO)
logger.addHandler(sh)
logger.addHandler(fh)
formater = logging.Formatter('%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
sh.setFormatter(formater)
fh.setFormatter(formater)
logger.debug('debug级别,最低级别,http://www.cnblogs.com/uncleyong/')
logger.info('info级别,正常输出信息,http://www.cnblogs.com/uncleyong/')
logger.warning('waring级别,http://www.cnblogs.com/uncleyong/')
logger.error('error级别,http://www.cnblogs.com/uncleyong/')
logger.critical('critical级别,http://www.cnblogs.com/uncleyong/,db backup')
四、练习题
笔试题汇总(linux、shell、mysql、java、python、性能、自动化、docker、k8s等):
https://www.cnblogs.com/uncleyong/p/11119489.html
__EOF__

关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号