http协议
简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW : World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。
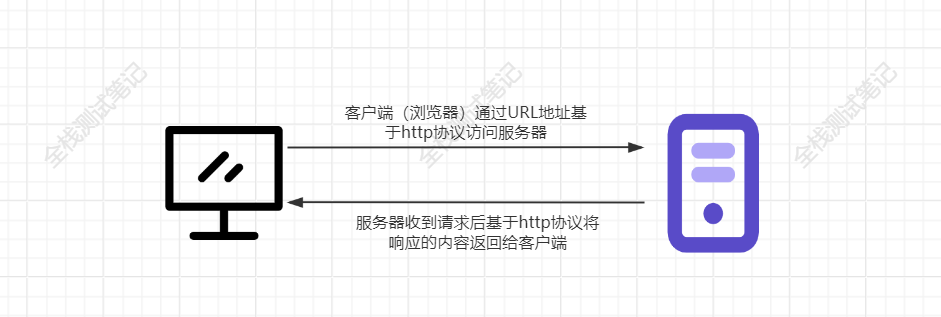
HTTP是应用层的协议之一,它是一种简单、灵活的通信协议,客户端(浏览器)通过URL地址基于http协议访问服务器,服务器收到请求后基于http协议将响应的内容返回给客户端。
(1) 基于TCP/IP协议
HTTP协议是基于TCP/IP协议之上的应用层协议。
HTTP是通过 Socket 来使用 TCP 的,Socket 做为套接层 API,它本身不是协议,只规定了 API。
(2) 基于请求(request)-响应(response)模式
HTTP协议规定,请求从客户端发出,最后服务器端处理请求并返回,就是说,有请求,就要有应答。另外,服务端在接收到请求之后才会发送响应。
(3) 无状态保存
HTTP是一种不保存状态,即无状态(stateless)协议。
HTTP协议自身不对请求和响应之间的通信状态进行保存。协议本身并不保留之前每次的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成 如此简单的。
为了弥补这个缺陷,后续引进了cookie、session、token等相关技术手段(业务相关)。
(4) 短连接
HTTP1.0默认使用的是短连接(有的资料也说是无连接的协议)。浏览器和服务器每进行一次HTTP通信,就建立一次tcp连接,通信结束就断开tcp连接;
HTTP/1.1起,默认使用长连接。要使用长连接,客户端和服务器的HTTP首部的Connection都要设置为keep-alive才能支持长连接。HTTP长连接,指的是复用TCP连接。多个HTTP请求可以复用同一个TCP连接(一个http请求在完成时,标注是keep-alive的,底层的tcp连接不需要断开,可以供多个http连接使用),这就节省了TCP连接建立和断开的消耗;
HTTP/2.0,多路复用。
http协议包含(两个部分):
http request:由浏览器发送数据到服务器需要遵循的请求协议,http请求包含三个部分:request line、 request header、 request body;已经由浏览器或者其它客户端工具帮我们封装好了
http response:服务器发送数据到浏览器需要遵循的请求协议,http响应包含三个部分:response line、 response header、 response body。
演示代码
server.py
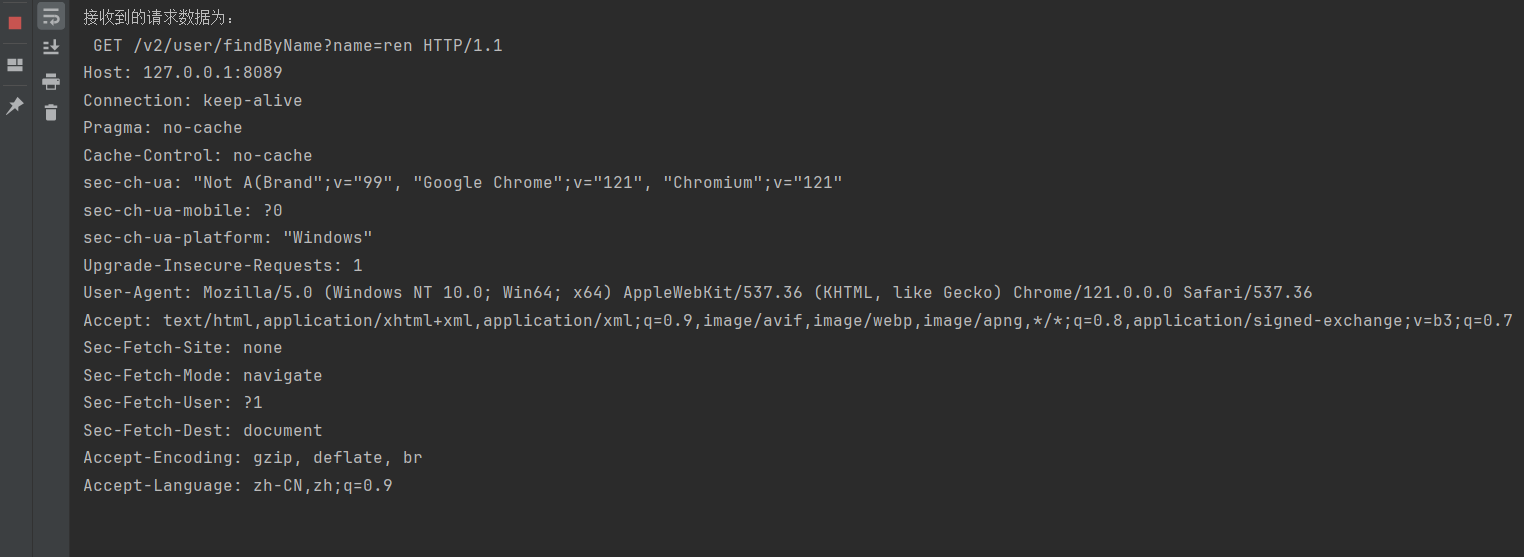
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | import socket# 创建TCP Socket对象;括号中的实参是默认值,可以简写为:sock = socket.socket()sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 绑定IP地址和端口号host = '127.0.0.1'port = 8089sock.bind((host, port))# 开始监听连接sock.listen(5)print('等待客户端连接...')while True: # 接受客户端连接并返回新的Socket对象 conn, addr = sock.accept() # 阻塞等待客户端连接 # print('与客户端', addr[0], '建立了连接!') # 接收客户端发送的请求数据,接收最多4096字节大小的请求数据,然后将其转换成UTF-8编码格式的字符串 data = conn.recv(4096) # data = conn.recv(4096).decode("utf-8") print('接收到的请求数据为:', data) # 服务端返回数据 conn.send('HTTP/1.1 200 ok\r\nserver:qzcsbj\r\ncontent-type:application/json\r\n\r\n{"code":0,"message":"success","data":{"id":"1","name":"韧"}}'.encode("utf-8")) print('返回数据给客户端完成') # 关闭当前客户端连接 conn.close() |
HTTP请求协议
用jmeter发送请求
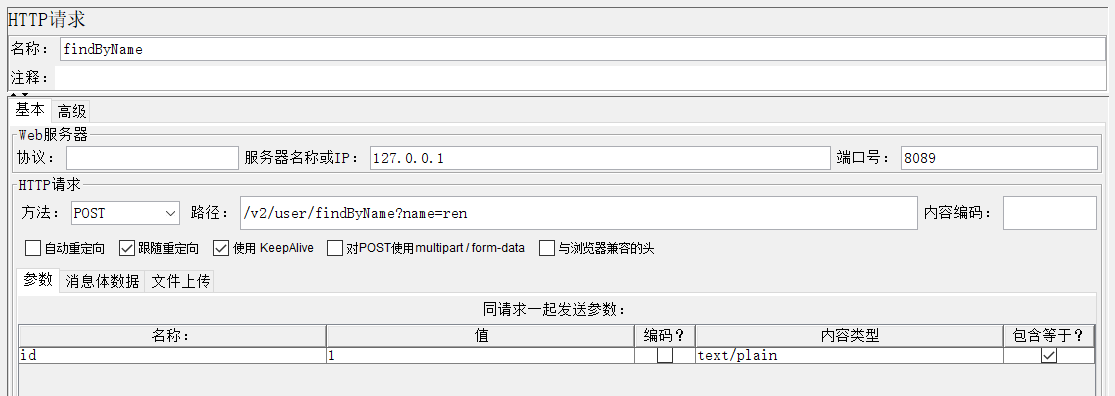
server端打印内容

接收到的请求信息decode后打印
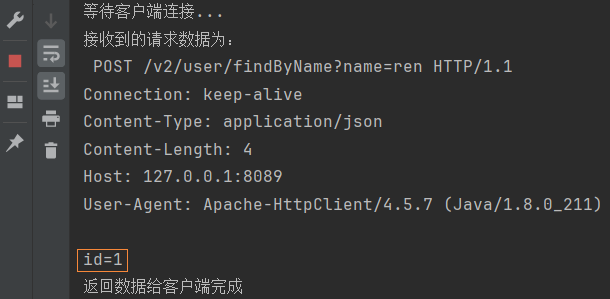
HTTP请求协议:request line、 request header、 request body
请求首行、请求头、请求体
POST /v2/user/findByName?name=ren HTTP/1.1
Connection: keep-alive
Content-Type: application/json
Content-Length: 4
Host: 127.0.0.1:8089
User-Agent: Apache-HttpClient/4.5.7 (Java/1.8.0_211)
空行
id=1
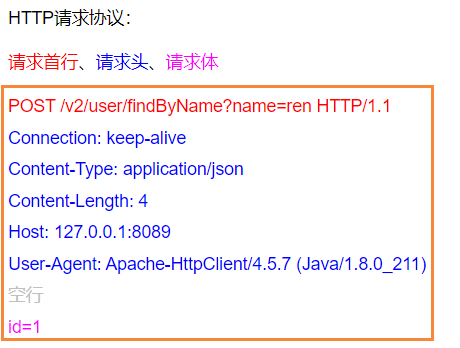
HTTP响应协议
用浏览器发送请求
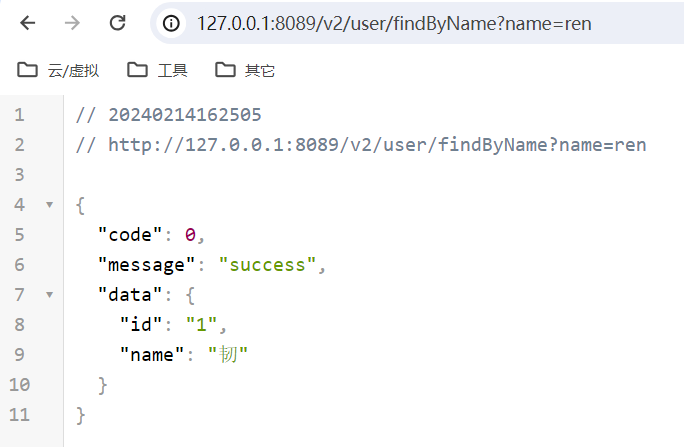
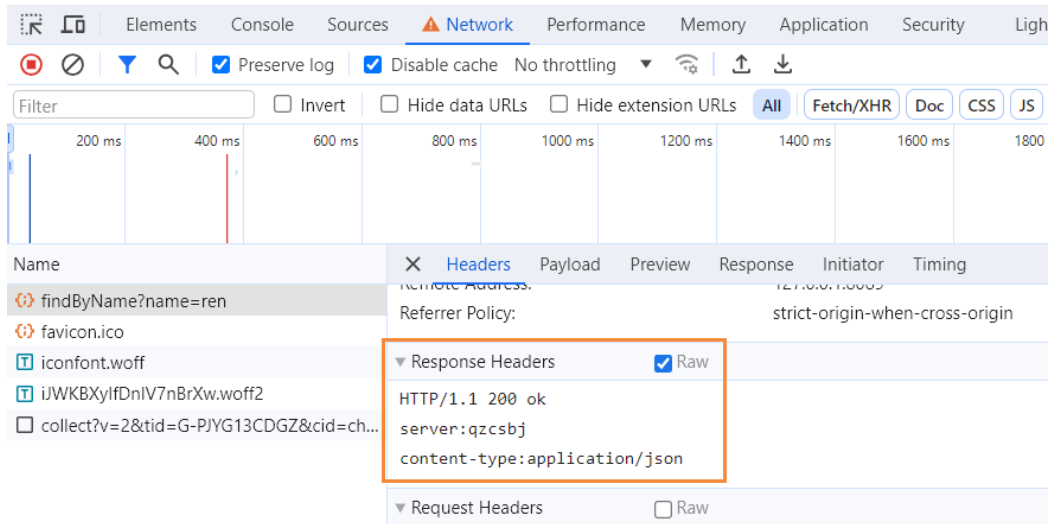
HTTP响应协议:response line、 response header、 response body
响应首行、响应头、响应体
HTTP/1.1 200 ok
server:qzcsbj
content-type:application/json
空行
{"code":0,"message":"success","data":{"id":"1","name":"韧"}

另外,下面是浏览器给我们封装的请求协议:
\r\n\r\n表示空行,后面内容,因为get请求没有请求体,参数在路径后面

decode后打印结果
补充:response code
响应代码,又叫状态码。是服务器用来告知客户端,对于请求的处理状态的。响应代码通常是三位长度的数字,一般来说根据首位字母进行的大致分类。
1xx:通常表示通信连接过程中的交互信息
2xx:典型的就是200,表示处理成功;200只是表示http协议层面的成功,不一定表示业务成功
3xx:通常表示重定向
4xx:客户端错误。400 就是客户端发送的数据有误;403 客户端的权限问题;404 资源未找到。
5xx:服务器错误
其它参考:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | 1xx(临时响应),并需要请求者继续执行操作的状态代码100:客户端应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。101:(切换协议) 客户端要求服务器切换协议,服务器已确认并准备进行切换。102:由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。2xx(成功),处理了请求的状态代码200:正确的请求返回正确的结果,如果不想细分正确的请求结果都可以直接返回200。201:表示资源被正确的创建。比如说,我们 POST 用户名、密码正确创建了一个用户就可以返回 201。202:请求是正确的,但是结果正在处理中,这时候客户端可以通过轮询等机制继续请求。203:请求的代理服务器修改了源服务器返回的 200 中的内容,我们通过代理服务器向服务器 A 请求用户信息,服务器 A 正常响应,但代理服务器命中了缓存并返回了自己的缓存内容,这时候它返回 203 告诉我们这部分信息不一定是最新的,我们可以自行判断并处理。204:服务器成功处理了请求,但是不需要返回任何实体内容。如果客户端为浏览器,则浏览器不发生跳转,停留当前页面,但是页面中的文档信息更新。205:服务器成功处理了请求,且没有返回任何内容,与204不同点为,文档信息清空。206:服务器已成功处理了部分get请求。请求里必须包含Range头信息来只是客户端希望得到的内容范围,并且可能包含if-Range来作为请求条件。207:由WebDAV(RFC 2518)扩展的状态码,代表之后的消息体将是一个XML消息,并且可能依照之前子请求数量的不同,包含一系列独立的响应代码。3xx(已重定向),表示要完成请求,需要进一步操作300:请求成功,但结果有多种选择。301:请求成功,但是资源被永久转移。比如说,我们下载的东西不在这个地址需要去到新的地址。302:在其他地址发现了请求数据。303:使用 GET 来访问新的地址来获取资源。304:请求的资源并没有被修改过。305:请求的资源必须从服务器指定的地址得到。306:在最新的规范中,306状态码已不被使用。307:请求的资源现在临时从不同的URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。308:使用原有的地址请求方式来通过新地址获取资源。4xx(请求错误)400(错误请求)表示客户端请求的语法错误,服务器无法理解,例如 url 含有非法字符、json 格式有问题。401(未授权)请求要求身份验证。对于需要登录的网页,服务器可能返回此响应。402表示保留,将来使用。403(禁止)表示服务器理解请求客户端的请求,但是拒绝请求。404(未找到)服务器无法根据客户端的请求找到资源(网页)。405(方法禁用)禁用请求中指定的方法。406(不接受)无法使用请求的内容特性响应请求的网页。407(需要代理授权)此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。408(请求超时)服务器等候请求时发生超时。409(冲突)服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。410(已删除)如果请求的资源已永久删除,服务器就会返回此响应。411(需要有效长度)服务器不接受不含有效内容长度标头字段的请求。412(未满足前提条件)服务器未满足请求者在请求中设置的其中一个前提条件。413(请求实体过大)表示响应实在太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值。414(请求的 URI 过长)请求的 URI(通常为网址)过长,服务器无法处理。415(不支持的媒体类型)请求的格式不受请求页面的支持。416(请求范围不符合要求)如果页面无法提供请求的范围,则服务器会返回此状态代码。417(未满足期望值)在请求头 Expect 指定的预期内容无法被服务器满足(力不从心)。418表示我是一个茶壶。超文本咖啡馆控制协议,但是并没有被实际的 HTTP 服务器实现。420表示方法失效422表示不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应。5xx(服务器错误)500(服务器内部错误)服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。501(尚未实施)服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。502(错误网关)服务器作为网关或代理,从上游服务器收到无效响应。503(服务不可用)服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。504(网关超时)服务器作为网关或代理,但是没有及时从上游服务器收到请求。505(HTTP 版本不受支持)服务器不支持请求中所用的 HTTP 版本。 |
补充:URL的构成
URL包含:协议、域名、端口、path(URI)、URL地址参数
URL(uniform resource locator,统一资源定位器)是URI的一种实现,URI是URL的一部分
URI(uniform resource identifier,统一资源标识符)是抽象概念
比如:http://www.qzcsbj.com:8089/v2/user/findByName?name=ren
协议是:http
域名是:www.qzcsbj.com,域名解析为ip,通过ip找到接入到网络中的硬件服务器
端口是:8089,通过端口号找到运行在硬件服务器中的软件服务
路径是:/v2/user/findByName
参数是:name=ren
__EOF__

关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下