JMeter【第四篇】参数化
概念
参数化的原因,并不是网上说的真实模拟不同用户,真实反应服务器性能,而是:
数据唯一性(比如注册名不能一样)
避免数据库查询缓存
如何避免参数化:
去掉唯一性校验的约束
关闭数据库的查询缓存,mysql关闭方式,set global query_cache_type=0
同时,也可以参考loadrunner参数化:https://www.cnblogs.com/uncleyong/p/10702700.html
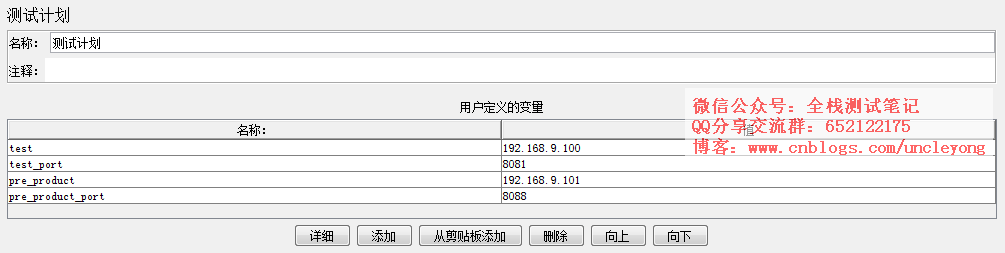
用户定义的变量
最主要的应用是参数化环境的ip和端口,这样,在“HTTP请求默认值”配置元件中填写参数就可以了,这样方便在不同的环境中切换测试

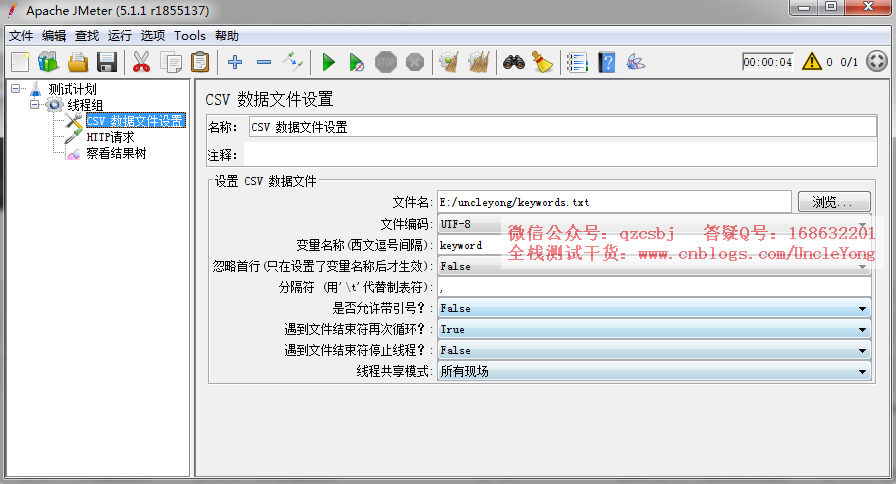
csv数据文件设置
在jmeter中做参数化,用得最多的就是CSV文件参数化

解释:

提醒:分隔符不能是参数化的值中的符号,否则会被截断,比如,你参数化整个json,逗号作为分隔符,而json中就有逗号,所以,发送请求的时候,会被截断。
线程共享模式:

所有现场:所有的线程共享一个数据文件
当前线程组:每个线程复制一份文件自己独用
当前线程:一个线程组一份文件,线程组内是所有现场
这里我就不演示上面各种模式的取值方式了,大家最好自己实践一下,这样印象更深刻
一个简单的应用(传k-v)
百度搜索,对搜索的关键字参数化
创建参数文件,因为只有一列,我可以很清楚的知道这一列是什么含义,所以没有在首行加变量名;另外,文件内容中,最后只能一个空行

循环4次

csv数据文件设置,设置为循环取值
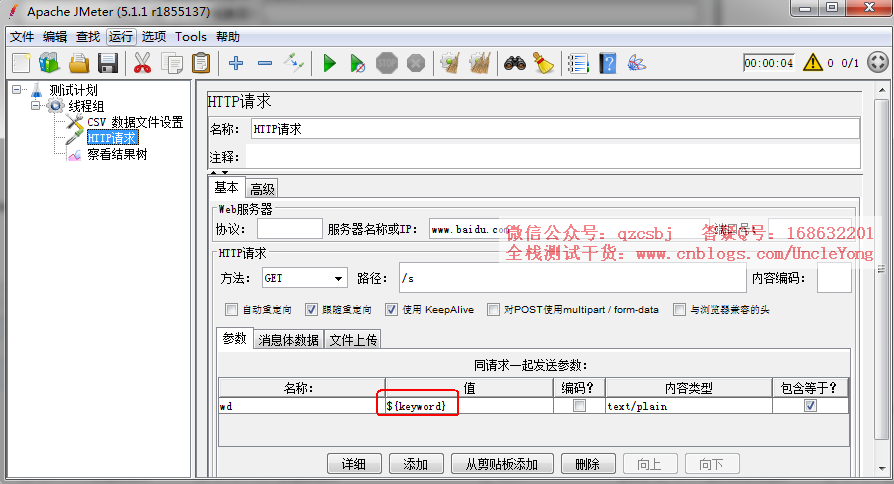
名称是参数名,值是参数值
引用参数${参数名}
运行
第一次循环取第一个值
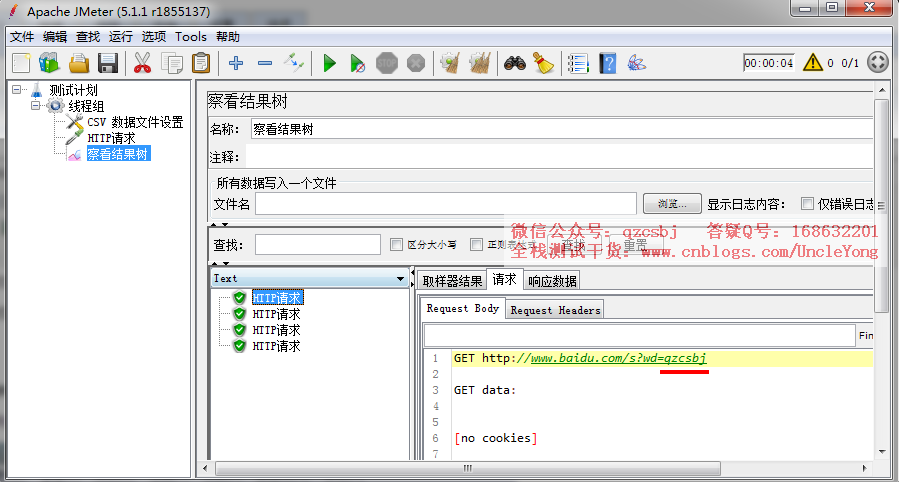
第二次循环取第二个值
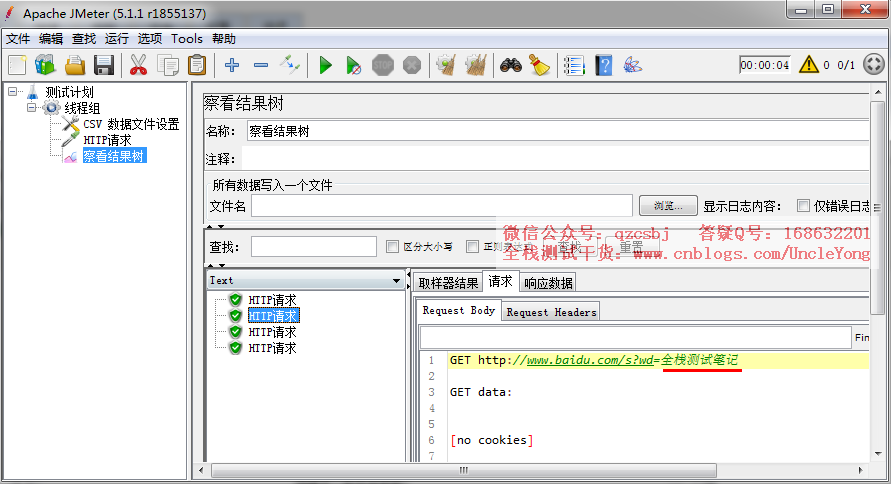
第三次循环取第三个值
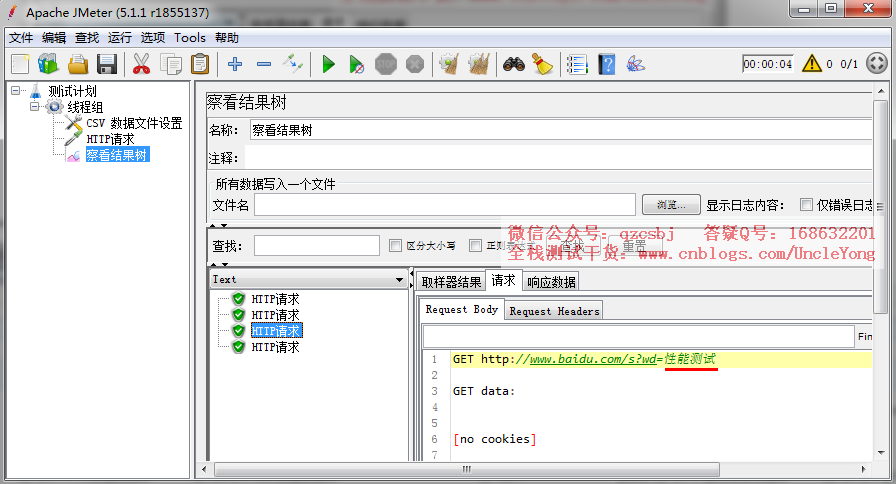
第四次循环取第一个值
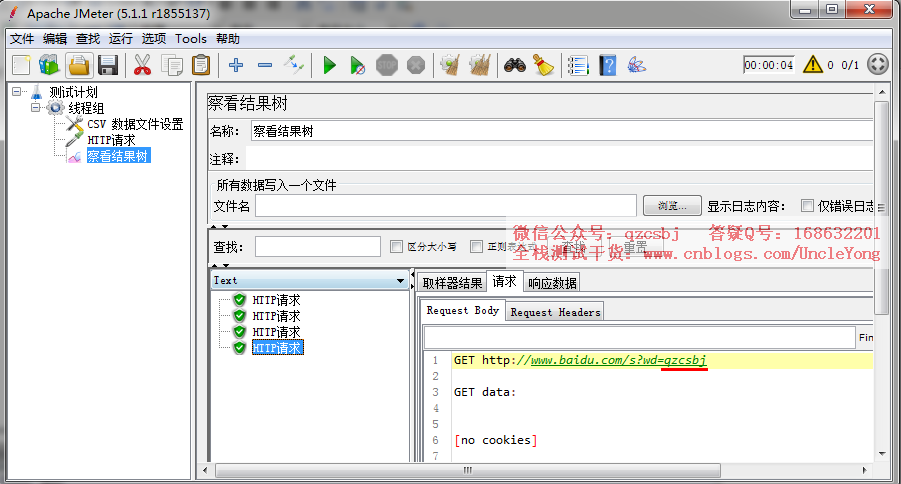
设置不循环取值
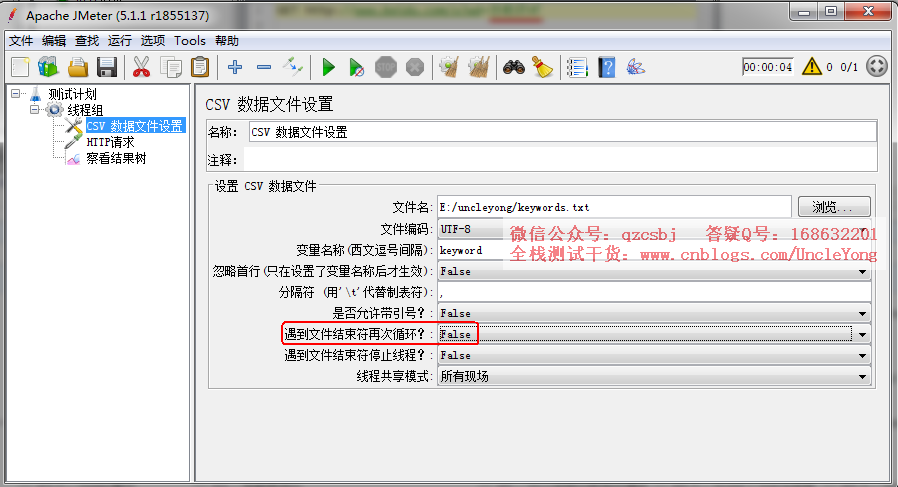
第四次循环取EOF

__EOF__

本文作者:持之以恒(韧)
关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!
关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号