性能测试:jmeter中通过beanshell把关联转变成参数化(关联转参数化)
在用jmeter做性能测试的时候,可能会因为依赖请求导致一些问题。
问题
问题一:参数化数据量不足,比如:我要压测的某个接口依赖登录,先通过登录获取到tokenId(每个账号登录一次),然后把tokenId作为被压测接口的入参,如果账号不足,当我并发的线程数多于登录账号数量,就会出现账号二次登录,而前一次登录获取到tokenId值将失效,导致用老tokenId的请求失败;
问题二:依赖请求的存在,导致被压测的接口性能不准确;
为了解决上面的问题,我们可以不用关联,先单独操作依赖的请求,把需要获取的关联值存到文件中,被压测的请求就用文件参数化获取关联值,
有人可能会问,被关联的值可能是有有效时间的,没关系,我们可以找开发帮忙把有效时间设置长点,比如24h,这样就不用频繁重新获取关联值保存到文件中,毕竟我们是压测,不需要关注关联值的有效期限。
下面,对问题一的场景来演示一下。
删除已存在的参数化文件tokenId.txt
注意:因为后面要生成tokenId.txt这个文件,如果这个文件存在,我们先删除。
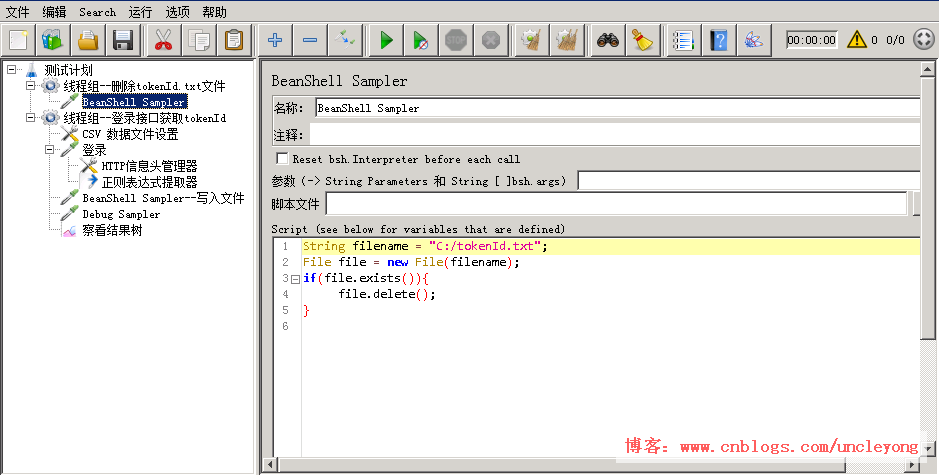
beanshell脚本
String filename = "C:/tokenId.txt";
File file = new File(filename);
if(file. exists()){
file.delete();
}
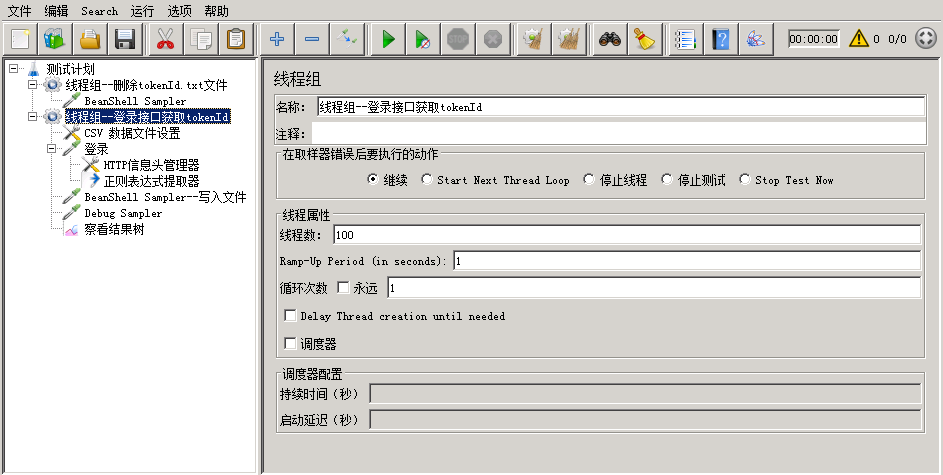
生成参数化的文件tokenId.txt
因为只有100个账号,所以线程数设置为100,循环次数设置为1,即每个线程运行一次
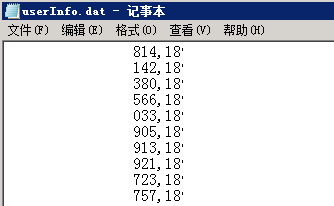
a.登录接口需要的csv参数化文件userInfo.dat
注意,此参数化文件中有两列,第一列是卡号,第二列是登录账号,下图抹掉了敏感数据
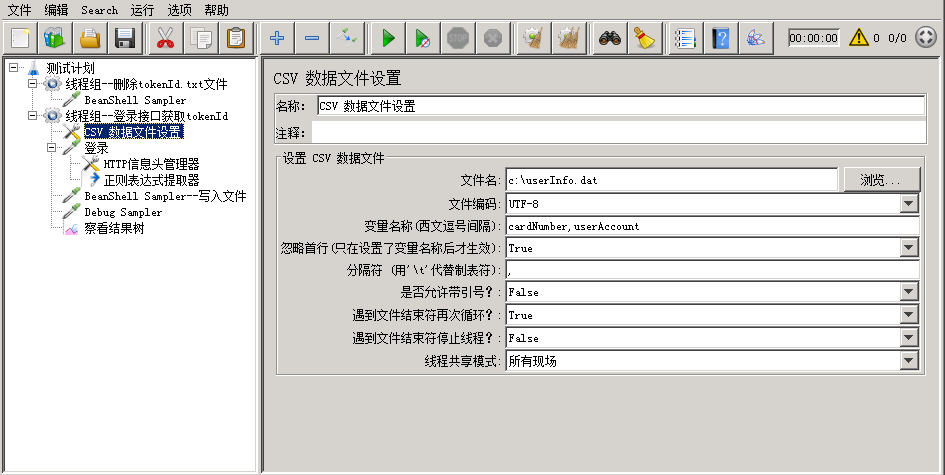
登录获取参数化文件中的登陆账号userAccount,而卡号cardNumber是被压测接口需要的参数
b.登录请求
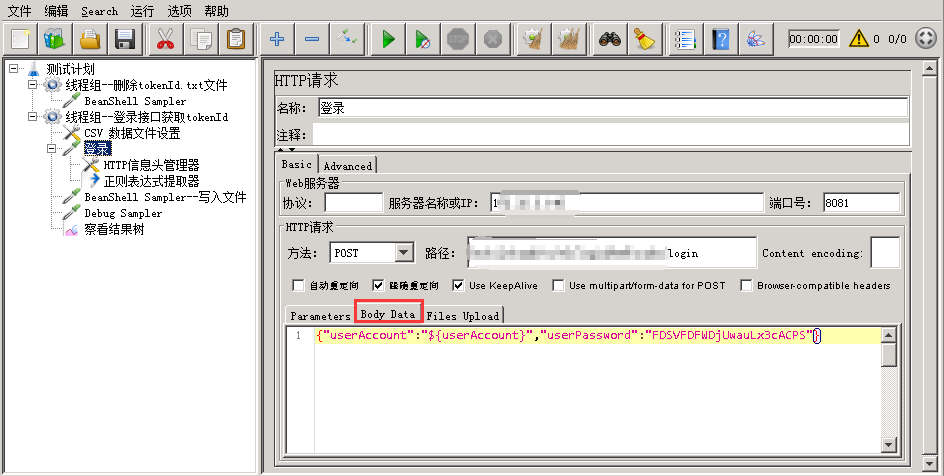
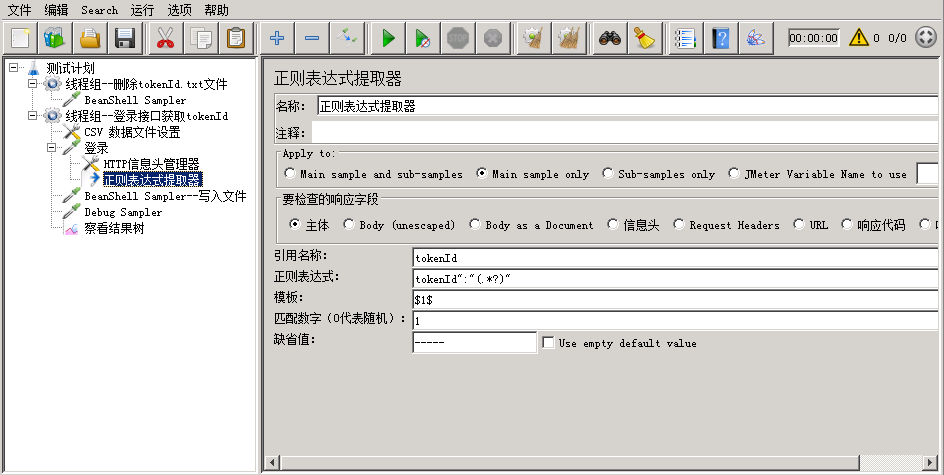
正则提取tokenId
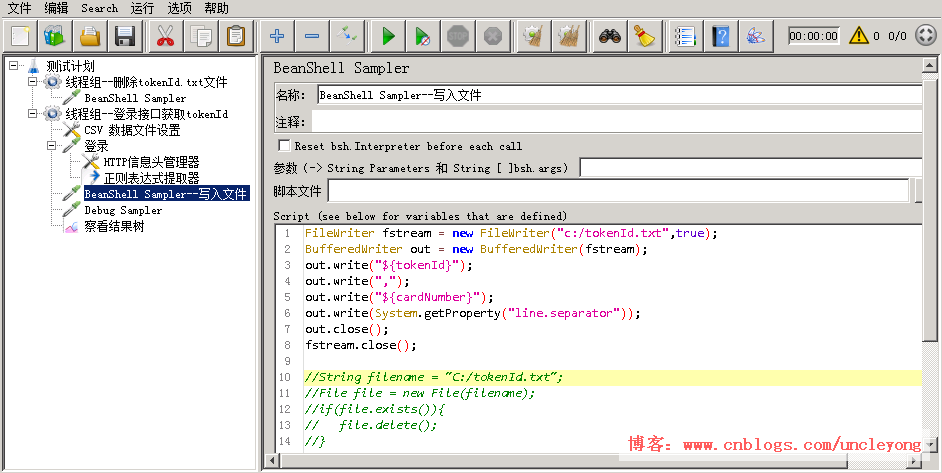
c.把关联获取到的值写入文件,因为被压测的接口需要用到tokenId和卡号cardNumber,所以需要把tokenId和卡号配对写在一行上,第一列是tokenId,第二列是卡号cardNumber
用包装流(BufferedReader)将字符输入流(FileReader)包装为缓冲字符输入流(BufferedReader)
生成的tokenId.txt文件,逗号分隔同一行的tokenId和卡号cardNumber两列数据,抹掉了敏感数据

被压测接口脚本
被压测接口脚本略,这里只演示参数化文件
这样,被压测接口就可以用上面生成的关联参数文件tokenId.txt了,下面变量名称和生成的tokenId.txt文件中变量顺序要一致
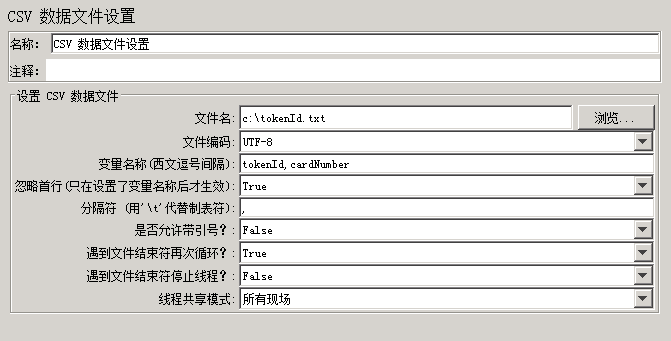
最终,我们就可以把脚本的重心完全放到被压测接口,而排除依赖接口的影响。
当然,读取参数化文件也会耗费性能,但是影响远低于先请求依赖接口获取到关联数据再请求被测接口。
更多参考:
https://www.cnblogs.com/uncleyong/p/12154065.html
__EOF__

关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号