软工实践-结对作业二
软工实践结对第二次作业
具体分工
- 陈晓彬
负责从CVPR网站爬取论文数据 - 陈璟
负责对论文数据进行分析
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | 40 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 230 | 290 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 20 |
| • Design Spec | • 生成设计文档 | 0 | 0 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| • Design | • 具体设计 | 30 | 30 |
| • Coding | • 具体编码 | 120 | 150 |
| • Code Review | • 代码复审 | 20 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 15 | 20 |
| • Test Repor | • 测试报告 | 0 | 0 |
| • Size Measurement | • 计算工作量 | 5 | 5 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 15 |
| 合计 | 275 | 350 |
解题思路描述与设计实现说明
-
爬虫使用
我们访问某一个网页的时候,在地址栏输入网址,按回车,该网站的服务器就会返回一个HTML文件给我们,浏览器解析返回的数据,展示在UI上。同样爬虫程序也是模仿人的操作,给网站发送一个请求,网站会给爬虫程序返回一个HTML文件,爬虫程序再根据返回的数据进行抓取分析 。
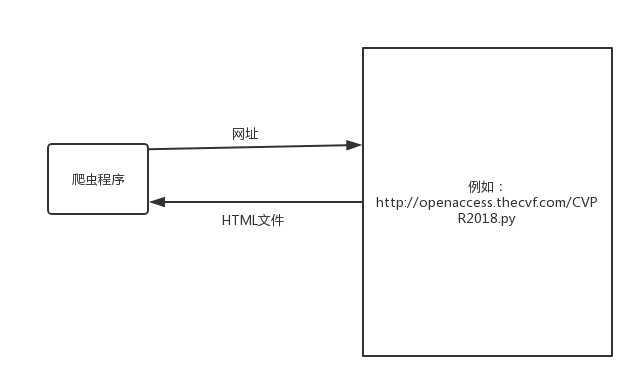
Jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。首先Jsoup从一个URL,文件或字符串解析HTML,然后使用DOM或者CSS选择器来查找,取出数据。
-
代码组织与内部实现设计(类图)
代码分为两块,一块为Main,这里是存放主函数的地方,负责对参数进行分析,对另一个类进行调用来分析文本以及输出结果,另一个是文本分析类FileParser,这个类按照Main给出的参数对文本进行分析,将分析出的词组或单词存放在一个map中,之后输出就可以用这个map中的数据进行输出

-
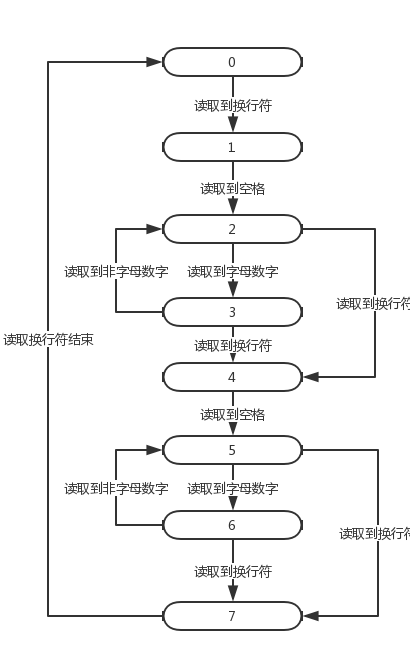
说明算法的关键与关键实现部分流程图
算法的关键在于对文本的分析,将其分为若干的词组。算法的关键在于状态的改变,可以吧本次作业理解成一个自动机,显而易见的是本次作业的输入文件是由论文编号和Title和Abstract组成的,其中Title和Abstract内容为一行字符串(这是观察发现的,如果不是就GG了),其中每行字符串可以理解为若干个字母数字组成的串以及若干个非字母数字组成的串交叉构成的,因此我设置了以下状态。
- 0
读取论文编号阶段 - 1
读取"Title: "阶段 - 2
读取Title中非字母数字串阶段 - 3
读取Title中字母数字串阶段 - 4
读取"Abstract: "阶段 - 5
读取Abstract中非字母数字串阶段 - 6
读取Abstract中字母数字串阶段 - 7
读取论文间两空格阶段
流程图如下所示
附加题设计与展示
-
设计的创意独到之处
-
实现思路
-
实现成果展示
关键代码解释
while((ch=br.read())!=-1) {
if(ch>255)continue;
//编号
if(state==0) {
if(isDigit(ch)) {
temp.append((char)ch);
}
else {
int no=Integer.parseInt(temp.toString());
//System.out.println(no);
line=(no+1)*2;
state=1;
temp.setLength(0);
}
}
//读取Title:
else if(state==1) {
if(ch==' ') {
cizu.setLength(0);
del.clear();
state=2;
start=false;
temp.setLength(0);
}
}
//非字母数字
else if(state==2) {
charNum++;
if(ch=='\n') {
//under windows , delete the '\t'
charNum--;
state=4;
}
if(isLetter(ch)||isDigit(ch)) {
if(m>1&&start) {
cizu.append(temp.toString());
del.offer(temp.length());
}
temp.setLength(0);
isWord=true;
pos=0;
state=3;
if(isDigit(ch)) {
isWord=false;
}
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
}
temp.append((char)ch);
}
//字母数字
else if(state==3) {
charNum++;
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
if(ch=='\n') {
charNum--;
state=4;
}
if((!isLetter(ch)&&!isDigit(ch))) {
//not a word ,clear the cizu and del
if(!isWord||temp.length()<4) {
cizu.setLength(0);
del.clear();
}
//add word,if the queue is reach m,then add to map
else {
wordNum++;
start=true;
//add this word
cizu.append(temp.toString());
//add this size
del.offer(temp.length());
if(del.size()==m*2-1) {
if(mp.containsKey(cizu.toString())) {
int val=mp.get(cizu.toString())+val1;
mp.put(cizu.toString(), val);
}
else {
mp.put(cizu.toString(), val1);
}
int size=del.poll();
if(m>1) {
size+=del.poll();
}
cizu.delete(0, size);
}
}
if(state==4) {
}
else {
temp.setLength(0);
state=2;
}
}
temp.append((char)ch);
if(pos<4&&isDigit(ch)) {
isWord=false;
}
pos++;
}
//读取Abstract:
else if(state==4) {
if(ch==' ') {
cizu.setLength(0);
del.clear();
temp.setLength(0);
state=5;
start=false;
space=0;
}
}
//非字母数字
else if(state==5) {
charNum++;
if(ch=='\n') {
//under windows , delete the '\t'
charNum--;
state=7;
}
if(isLetter(ch)||isDigit(ch)) {
if(m>1&&start) {
cizu.append(temp.toString());
del.offer(temp.length());
}
temp.setLength(0);;
isWord=true;
pos=0;
state=6;
if(isDigit(ch)) {
isWord=false;
}
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
}
temp.append((char)ch);
}
//字母数字
else if(state==6) {
charNum++;
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
if(ch=='\n') {
charNum--;
state=7;
}
if((!isLetter(ch)&&!isDigit(ch))) {
//not a word ,clear the cizu and del
if(!isWord||temp.length()<4) {
cizu.setLength(0);
del.clear();
}
//add word,if the queue is reach m,then add to map
else {
wordNum++;
start=true;
//add this word
cizu.append(temp.toString());
//add this size
del.offer(temp.length());
if(del.size()==m*2-1) {
if(mp.containsKey(cizu.toString())) {
int val=mp.get(cizu.toString())+val2;
mp.put(cizu.toString(), val);
}
else {
mp.put(cizu.toString(), val2);
}
int size=del.poll();
if(m>1) {
size+=del.poll();
}
cizu.delete(0, size);
}
}
if(state==7) {
}
else {
temp.setLength(0);
state=5;
}
}
temp.append((char)ch);
if(pos<4&&isDigit(ch)) {
isWord=false;
}
pos++;
}
//行间两空行
else if(state==7) {
if(ch=='\n') {
space++;
}
if(space==2) {
state=0;
temp.setLength(0);
}
}
}
性能分析与改进
在本次作业中基本上没有在整体完成之后的大幅度性能改进,在编码过程中就有做一些性能上的调优,我是使用Java来实现本次作业的,比如说文件读入时我用的通过BufferedReader包装的FileReader而不是使用InputFIleStream,是因为使用具有缓冲区的BufferedReadder读取更快,在本次得到的论文列表测试中有肉眼可以见的进步,其次是将map的实现由TreeMap改为HashMap,TreeMap的内部实现为二叉树,而HashMap 的内部实现为哈希表,显而易见HashMap 的插入和查询的时间复杂度是要比TreeMap更优的。
本次程序的耗费时间较短,暂不需要性能优化
单元测试
public class FileParserTest {
public FileParser fp=new FileParser();
@Test
public void testParser() {
File file=new File("d://1.txt");
FileReader fr;
try {
fr = new FileReader(file);
fp.Parser(fr, 1, 1);
assertEquals(fp.getCharNum(),39);
assertEquals(fp.getLine(), 6);
assertEquals(fp.getWordNum(), 10);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
因为在一个函数中就把所有事都做了,所以构造了一个测试文本简单测试了一下
Github代码签入记录

本人代码是一次写完的,所以并没有很多的签入记录
遇到的代码模块异常及解决方法
虽然是一次写完的,但其实还是有遇到一些错误,由于很久没有用java来写东西所以放了一个比较低级的错误,那就是在输出文件时,不管我怎么调用write方法,但输出文件虽然被新建了,里面却没有任何内容,后来才发现FileWriter在输出时是先输出到缓冲区的,而我没有执行File的close方法,所以缓冲区的内容没有被刷新到文件中,后来在全部输出完成后加了fflush方法就解决了
评价你的队友
队友还是非常牢靠的
学习进度条
| 第n周 | 新增代码行 | 本周学习耗时 | 重要成长 |
| 6 | 200 | 5 | Java使用 |

