基于两阶段提交的分布式事务实现(UP-2PC)
引言:分布式事务是分布式数据库的基础性功能,在2017年上海MySQL嘉年华(IMG)和中国数据库大会(DTCC2018)中作者都对银联UPSQL Proxy的分布式事务做了简要介绍,受限于交流形式难以做全面细致的探讨,借由本文进一步展开。
UP-2PC是面向分布式数据库的由中国银联自主研发的针对MySQL的2PC分布式事务实现,以UPSQL Proxy(分布式式数据库代理)作为事务管理器,UPSQL(MySQL银联定制版本)为资源管理器。
由于MySQL在5.7中彻底解决了xa prepare的高可用问题以及连接关闭自动回滚等问题,使得MySQL的xa真正可用。
分布式事务
如果了解分布式事务与2PC,并考虑过如下议题(不必认可),可略过本节内容:
• TCC是应用层的2PC实现
• 2PC的实现难点在于事务管理器(TM)的异常处理
• 2PC与Paxos:Paxos用于相同数据的分布式高可用存储,2PC更擅长不同数据分布式存储的事务一致性
2PC协议(Prepare,Commit, Rollback)
首先我们要提到分布式事务模型:X/Open DTP(Distributed Transaction Processing) Reference Model。
• X/Open组织定义的一套分布式事务的标准,定义了规范和API接口,由厂商进行具体的实现
• X/Open DTP定义了三个组件: AP,TM,RM
• AP(Application Program):使用分布式事务的应用
• RM(Resource Manager):资源管理器,这里可以是一个DBMS系统,或者消息服务器管理系统,资源管理器必须实现XA定义的接口
• TM(Transaction Manager):事务管理器,负责协调和管理事务
通常把TM管理的分布式事务称为全局事务,把RM管理的事务称为本地事务。
两阶段提交,是X/Open DTP的一个实现,主要在事务结束动作前加入了一个Prepare阶段:
• Prepare阶段:Prepare成功的数据,后续Commit一定会成功。
• Commit/Rollback阶段:提交或回滚数据
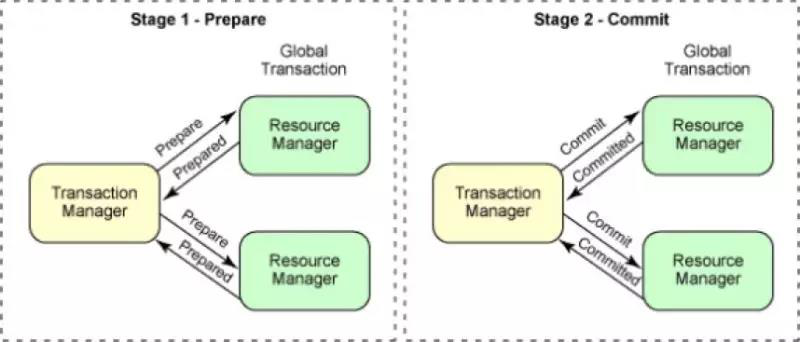
图例:2PC协议
DTP很早就指出资源管理器的类型不单单是数据库,还可以是消息服务。
TCC协议(Try, Confirm, Cancel)
TCC编程: 将业务逻辑拆解为Try、Confirm和Cancel三个阶段,实际上两阶段提交的变种。业务场景如:锁单、下单和取消。
TCC编程需要保证幂等性,即:可以被不断调用接口(直至符合预期),因而需要保证多次调用不会导致异常影响(如重复扣款等)。2PC的主要问题
2PC协议,主要是在如下场景的处理较为复杂:
• 同步阻塞、应答超时
• TM宕机恢复
2PC比较:数据库VS应用
比较容易取得共识的结论:不同业务系统之间使用2PC。
那剩下的问题就简单了, 相同业务系统之间是使用数据访问层2PC还是TCC?一般而言,基于研发成本考虑,会建议:新系统由数据库层来实现统一的分布式事务。
但对热点数据,例如商品(票券等)库存,建议使用TCC方案,因为TCC的主要优势正是可以避免长时间锁定数据库资源进而提高并发性。
2PC与Paxos
有一种广为流传的观点:"2PC到3PC到Paxos到Raft",即认为:
• 2PC是Paxos的残次版本
• 3PC是2PC的改进
上述2个观点都是我所不认同的,更倾向于如下认知:
• 2PC与Paxos解决的问题不同:2PC是用于解决数据分片后,不同数据之间的分布式事务问题;而Paxos是解决相同数据多副本下的数据一致性问题。例如,UP-2PC的数据存储节点可以使用MGR来管理统一数据分片的高可用
• 3PC只是2PC的一个实践方法:一方面并没有完整解决事务管理器宕机和资源管理器宕机等异常,反而因为增加了一个处理阶段让问题更加复杂
MySQL的2PC语法(XA)
MySQL提供的2PC语法(MySQL XA)如下:
XA {START|BEGIN} xid [JOIN|RESUME]
XA END xid [SUSPEND [FOR MIGRATE]]
XA PREPARE xid
XA COMMIT xid [ONE PHASE]
XA ROLLBACK xid
XA RECOVER [CONVERT XID]
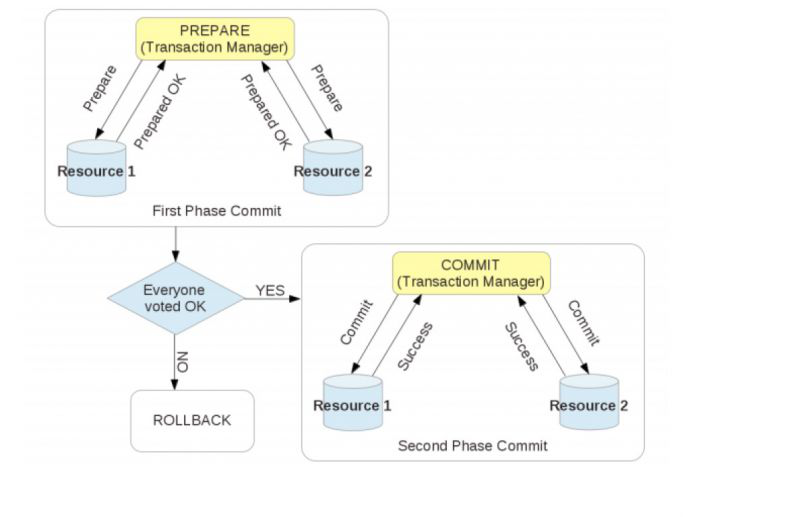
图例:MySQL XA语法
我们针对语法组合方式略微展开。
2PC的事务提交流程
2PC提交流程为:
XA {START|BEGIN} xid [JOIN|RESUME]
/*事务操作*/
XA END xid [SUSPEND [FOR MIGRATE]]
XA PREPARE xid
XA COMMIT xid
2PC的事务回滚流程
2PC回滚流程为:
XA {START|BEGIN} xid [JOIN|RESUME]
/*事务操作*/
XA END xid [SUSPEND [FOR MIGRATE]]
XA PREPARE xid /*可选*/
XA ROLLBACK xid
注意回滚时Prepare阶段不是必须的,所以可以在如下场景中可以省略Prepare阶段,减少网络交互:
• 本地事务未发生写操作
• 本地事务需要回滚
当然没有Prepare阶段也就意味着,其从两阶段退化为一阶段了。
2PC退化为一阶段提交
XA语法下退化为一阶段提交的流程为:
XA {START|BEGIN} xid [JOIN|RESUME]
/*事务操作*/
XA END xid [SUSPEND [FOR MIGRATE]]
XA COMMIT xid ONE PHASE
使用XA的一阶段提交(XA COMMIT xid ONE PHASE)的一个典型场景为在全局事务中只有该本地事务有写操作,在UP-2PC因为使用"最后参与者"方案,所以最后参与者也会使用XA一阶段提交。
2PC恢复处理
这里指当与MySQL的交互出现异常,例如与MySQL的会话断开、MySQL宕机等,如何获取并恢复处于Prepare状态下的2PC事务,并进行提交或回滚处理。
mysql> XA RECOVER;

UP-2PC技术实现
UP-2PC要解决的核心问题正是如何处理:事务管理器、资源管理器异常,以及可能的网络。
• 事务管理器(TM)突然宕机以及网络异常,导致协调信息丢失。典型的:异常发生后,处于Prepare状态的RM,正确进行后续处理(rollback和commit)
• 部分资源管理器(RM)突然宕机以及网络异常,导致的信息协调。典型的:全局事务内多个Prepare状态,此时若部分RM发生本异常,则TM如何处理,可选方案:
1.全局事务向请求者应答成功,由事务事务管理器后续提交异常RM
2.回滚所有RM,并向前端应答事务提交失败
通过上述探讨,可以发现2PC的主要难点在于:
• 事务状态信息维护:全局事务状态(TM)、本地事务状态(RM)
• 根据事务状态信息的异常处理策略
毫无疑问事务状态信息不丢失,是实现安全2PC的基础,由于本地事务状态信息可以通过MySQL高可用集群解决,所以我们仅需要:保证全局事务状态(TM)不丢失。
分布式事务的工程实践
在给出UP-2PC的方案之前,我们可以先了解下已有的分布式事务工程实践经验,“Distributed transactions in Spring, with and without XA”(Spring的分布式事务,使用或不用XA;Spring分布式事务的7种实现)是一篇不错的文章,很好总结了既有实践经验,这里仅对其中涉及XA的两种优化方案进行说明:
• 一阶段提交优化:如果全局事务只涉及一个RM,则不使用两阶段
• 最后参与者优化(Last Participant Support):选择一个RM(最后参与者)不使用两阶段提交,全局事务提交时,先对”最后参与者”进行(一阶段)提交.该策略又被称为:最后资源提交优化(Last Resource Commit Optimization)。
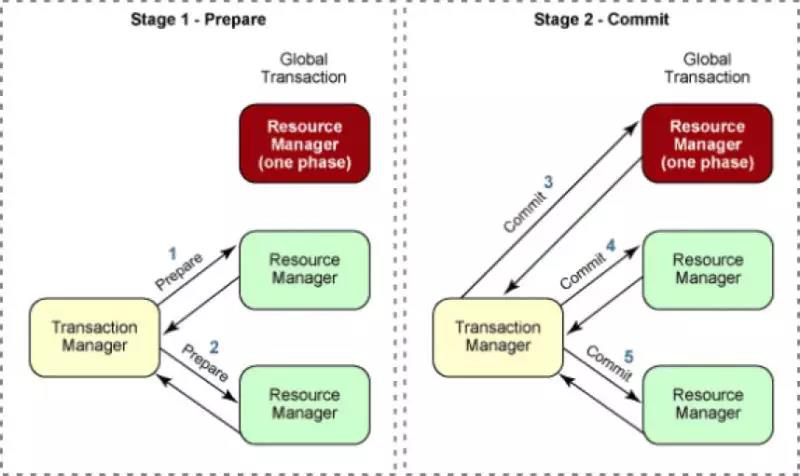
图例:最后参与者优化
乍看起来“最后参与者优化”方案效果有限,但事实上该方案直接指明了UP-2PC的实现路径,因为:
1.“一阶段提交优化”可以视为“最后参与者优化”的特例,即只全局事务只包含一个RM时两者等效
2.“最后参与者优化”指出了最后参与者在所有RM中最为重要,其事务提交结果决定着全局事务的结果,而前面也提到了全局事务状态是最重要的,所以我们自然推导出应该由最后参与者记录全局事务状态(我们称为xa-log)
UP-2PC核心方案
UP-2PC核心方案,包含3点:
1.利用RM节点分布式存全局事务状态信息(xa-log)
2.使用最后参与者协议
3.由最后参与者记录全局事务状态信息(xa-log)
xa-log中记录了全局事务id所涉及的所有资源管理器节点列表,和对应的本地xid,以及全局事务状态(commit|rollback)。
这里仅对全局事务需要进行commit做下说明,如果最后参与者commit成功,则认为全局事务commit成功,若最后参与者commit成功而其他资源管理器异常,则交由异常处理程序轮询xa-log表完成其他资源管理器的xa commit操作。
最后参与者的选择策略:如果第一个本地事务参与者如果发生了写操作,则选择其为最后参与者;否则在其他发生了写操作的参与中随机选择。该选择策略实现了最后参与者的分布式随机选择,进而保证xa-log的分布式随机分布。
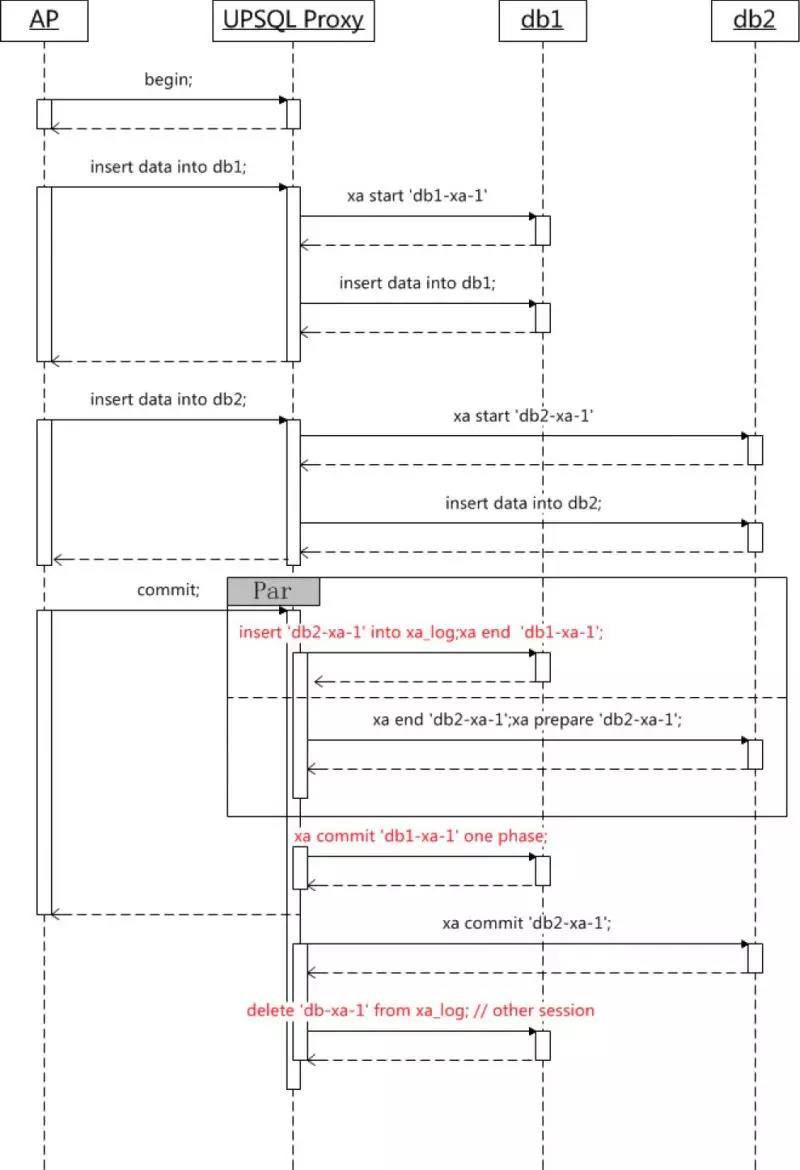
图例:UP-2PC实现
如图所示,UP-2PC的实现要点在于:
1.全局事务提交,则由最后参与者记录xa-log
2.最后参与者提交前,需要保证其他参与则处于prepare状态
3.在所有参与者事务提交结束后,删除xa-log
UP-2PC异常处理
在确保全局事务状态(xa-log)安全保存后,就可以针对2PC的各种异常进行处理。
不考虑TM异常,将异常按时间线进行区分:
1.全局事务commit之前:因为没有执行本地xa和xa-log的相关操作,则按事务提交失败处理
2.全局事务执行commit阶段:
– xa-log记录与prepare阶段异常:则回滚所有本地事务
– 最后参与者commit异常:则查询xa-log,如xa-log有全局事务的com mit记录,则视为事务提交成功;没有则视为提交失败;查询结果不确定 (如最后参与者宕机等),则事务状态不确定,可以考虑断开与AP连接(即不应答AP事务状态), 或保持连接直至得到查询结果未知。
– 其他参与者commit异常:依然应答全局事务成功,交由后续异步commit。
其他异常及异常处理: 以xa-log记录为准,对比xa-log与RM的xa-id信息进行对比分析进行提交或回滚操作。
需要指出的是由于TM是集群多机部署,所以xaid在编码时需要能区分不同TM节点信息。
与TDSQL分布式事务实现的区别
在已公开的同类产品中TDSQL与UP-2PC的解决思路最为接近,这里做下简单对比。
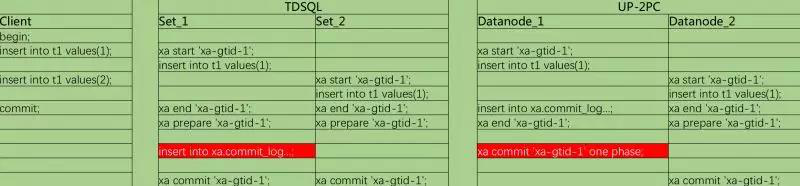
图例:TDSQL与UP-2PC对比
注:示例来自TDSQL的公开介绍材料,为简化描述略作修改
UP-2PC相对TDSQL的分布式事务解决方案主要区别在于UP-2PC采用了最后参与者策略,由最后参与者进行xa-log记录。
优点:减少启用一个数据库会话、一次网络交互、减少一个事务、退化一个2PC事务为一阶段
缺点:业务数据库用户需要具有xa-log的读写权限,因而具有运维风险,特别是在复用数据库实例的情况下
一次进一步展开思考,TDSQL不使用最后参与者策略的理由可能如下:
• 作为云上产品,应尽可能避免运维风险
• XA业务场景占比较少,性能影响有限
• 方便将来xa-log由其他方式存储
UP-2PC性能优化
在实现UP-2PC方案后,XA分布式事务的性能影响大约为30%(依赖场景),虽然符合预期,但也说明需要进一步优化。
这里给出UP-2PC两个性能优化方案:
• 本地事务启动优化
• MySQL XA协议优化
本地事务启动优化
对于属于不可重复读的全局事务,我们可以延迟开启本地事务以减少资源锁定时间。
本地事务启动优化的核心策略:
1.全局事务为不可重复读
2.本地事务只有发生了写才需要开启本地XA事务
针对如下业务场景:
/*事务隔离级别为read-commited或read-uncommited*/
Begin;
select db1 and db2; //1st
update db1;
update db2;
select db1 and db2; //2nd
Commit;
我们推演下全局事务管理器对上述语句的处理逻辑:
1.当第一次执行查询操作时,由于db1和db2都未发生写操作,则不必开启本地事务,在查询结束后可以将本地事务会话归还连接池。
2.在遇到第一次写入操作时,分别开启对应的本地事务管理器。
3.在后续查询时,由于已持有本地事务连接,则使用该连接进行查询操作。
而实际的场景中,可能操作如下:
Begin;
select db1 and db2;
update db1;
select db1 and db2;
Commit;
即全局事务内,查询的节点数量多于更新的节点数量,通过本方案只会对写入数据库节点开启本地XA事务,从而避免了不必要的事务开启操作。
MySQL XA协议优化
在实现UP-2PC的过程中我们一直有这样一个设计期望:在全局事务只涉及一个本地事务,我们能否对该事务不启用xa协议?
在我们实现“本地事务启动优化”后,这个问题视乎解决了,因为让最后参与者不使用XA协议就可以轻松实现了上述目标,但最后参与者不使用XA协议可能会导致我们无法解决后面提及的分布式死锁问题。
于是我们转换思路,对我们的设计目标的本质进行剖析,即XA一阶段提交与传统事务提交有什么区别?
答案:多了一个xa end。
于是XA协议优化方案也就呼之欲出,即省略掉不必须要的XA END。

图例:UP-2PC优化方案
如图所示,通过减少了xa end阶段,减少了交互次数自然提高了系统健壮性,也提高了性能。
分布式事务带来的新问题
在实现了基于2PC的分布式事务,对外提供统一事务管理特征,也会引入一些新问题,例如:
• 分布式事务死锁
• 对外XA协议支持(外部2PC)
• Savepoint支持
这里仅对部分解决方案进行说明。
分布式事务死锁
由于分布式事务管理多个RM,所以必然会带来分布式资源竞争和分布式死锁。例如:
• 会话a 和 b 开启分布式事务
• time 1: a write db1.resource1
• time 2: b write db2.resource2
• time 3: a write db2.resource2 -> 锁:a 等待b的 db2.resource2
• time 4: b write db1.resource1 -> 锁:b 等待a的 db1.resource1
在时间点4, a和b发生了资源循环等待,从而出现了分布式死锁。
如何解决分布式死锁呢,这里提供一种死锁检测方法:
• 扩展innodb_trx表,增加事务xid的记录
• TM层确保同一全局事务所对应的本地事务xid相同
这样就可以对所有全局事务的锁信息进行分析,并发现分布式死锁。
下表为扩展innodb_trx的效果,由于代码修改较为简单这里就不累述。

另一种方法是在本地事务中加入事务时间信息,在RM层根据时间先后顺序,保证只会存在单一时序的资源等待,从而避免死锁发生。
对外XA协议支持(外部2PC)
如果我们将应用UP-2PC的数据库集群视为一个整体,则实现分布式事务的过程为内部2PC,对外部应用提供2PC协议支持(即支持XA协议),则称为外部2PC。数据集群的内部外部2PC,可以与MySQL的内部外部2PC对应理解。
该逻辑较为简单,即在外部执行XA PREPARE时,我们在xa-log中记录全局事务状态为Prepare即可,需要指出的是:外部2PC下,内部的分布式事务无法使用前述的最后参与者优化方案。

图例:外部两XA协议实现
总结
本文介绍了UP-2PC的具体实现,涵盖了核心解决方案与异常处理策略、性能优化、带来的新问题与解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号