敏捷估算简介
抽象的
传统的软件开发估算技术是缓慢、持久的练习,因此完全不适合敏捷过程。出现了适合敏捷模型的新估算方法,只需最少的努力即可提供“刚好足够”的信息来支持优先级排序和决策制定。本文介绍了这些技术中最流行的技术,并介绍了这些实践如何在更大的、多团队的项目中发挥作用,在这些项目中,规范化已成为分歧的主题。
介绍
预测性、分阶段项目中使用的传统估算技术旨在为任务或相关需求集生成时间估算。我们这些参加过此类估算会议的人(通常被误称为“计划”会议)会知道这是多么痛苦的经历。
关于“X”到底有多复杂以及编码需要多长时间,经常有无休止的讨论。问题是每个任务都被独立于其他任务考虑。每个人都倾向于从自己做工作的角度来思考问题并没有帮助,自然而然,(感知和真实)专业知识的程度因人而异。
传统方法
在敏捷宣言之前,传统上使用三种主要方法来估算软件开发项目中的工作:
- 自下而上的估算——这是基于“普通开发人员”执行特定任务的概念,而进行估算的人试图孤立地计算出可能需要多少时间。比如我写这个Java函数需要5个小时,而且我的速度比同龄人快,所以我估计7个小时。它往往会创建非常大的“自下而上”的估计,这些估计经常受到管理层的挑战(减少),然后导致进度问题。
- 自上而下的估计——这是基于“模式匹配”的想法,即您查看整个项目(或者可能是项目的发布),并将其总规模与其他类似项目的人时数进行比较。“这个项目的复杂程度是上一个项目的两倍,上一个项目是 2,400 人时,所以我们估计它是 4,800 人时”。这往往会导致过于乐观的估计,需要与单独的自下而上的估计进行协调。
- 功能点估计——这种方法经常被用来尝试从估计中去除人为因素(偏见、乐观等),并通过一个简单的量化指标来量化工作的“规模”。在过去,它可能是代码行,但更常见的是正在开发的功能(例如软件对象方法或子例程)的数量以及用于说明它是大型、中型或小型功能的限定指标。结果是一个称为“功能点”的数值。然后,您可以使用此指标连同团队-基于时间因素(例如,这支球队可以做到每天2.0功能点),以拿出一个时间估计。这仅在您有一些先前的开发工作来比较时才有效。
敏捷估算方法
故事点 (Story Point)
与做出个人价值判断相比,人类大脑更擅长进行比较。您通常可以确定两本书中较长的一本,但准确估计其中一本的页数是极其困难的。这个原则是看似简单但非常成功的设备的基础,称为故事点。

故事点是一个抽象的衡量标准;他们没有单位。我们所知道的是,2 个故事点的编码和测试时间是 1 个故事点的两倍,而 4 个故事点的编码和测试时间是 2 的两倍,依此类推。这就引出了一个问题:我们如何根据抽象的度量来估计某事?更进一步,我们如何克服个人根据个人能力进行估算的问题?
估计方法
有两种流行的估计方法,它们都克服了这些困难。两者都具有三个关键特征:
- 所有团队成员都必须参加,
- 只会做出相对判断,并且
- 每种方法都作为游戏进行。
规划扑克
第一种方法被称为“规划扑克”,最初由 James Grenning (2002) 描述并由 Mike Cohn 在“敏捷估算和规划”(2005) 中推广。游戏是这样的:
- 一个用户故事被读给整个团队,然后每个团队成员在不透露他/她有根据的猜测的情况下估计故事点的数量,
- 所有估计同时显示,
- 高估和低估由其支持者解释,随后进行讨论,
- 然后在返回到步骤 2 之前重复秘密估计过程。
估计通常会很快收敛,但如果一两个团队成员经过反复讨论无法达成一致,则采取多数意见。规划扑克的另一个关键要素是估计值的允许值,它只能是斐波那契数列中的一个数字series: 1, 2, 3, 5, 8 或者类似的,比如等比数列1, 2, 4, 8。这是因为当事物变大时,准确的价值判断变得更加困难。例如,当仅使用整数时,与 1 的 20% 的偏差仍为 1;这是快速和容易的。但是,与 8 的 20% 背离是 7 或 9,这变得更加困难。消除 7 或 9 作为选项使答案为 8,这又是又快又简单。
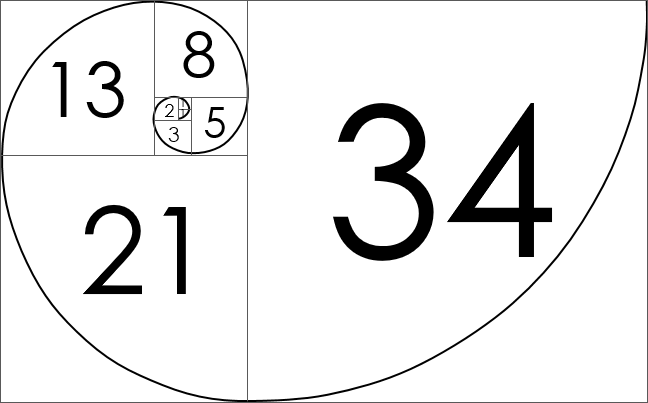
图 1:斐波那契数列
这一过程忽略了一个关键要素。当团队估算第一个故事时,每个团队成员如何知道什么构成了单个故事点?他们没有任何参考意义(双关语意为双关语)可供他们使用。请记住,我们使用的是比较方法,对于第一个故事,没有什么可以与之比较的。这个 catch-22 是通过使用一个参考故事来解决的。整个团队找到最小的用户故事,(忽略那些需要几乎零努力的故事)并同意将其称为 1 个故事点。所有随后的估计都将与该故事相关。偶尔提醒参考故事是实现一致性的好主意。
两阶段估计
第二种估计方法通过从第二个故事而不是第一个故事开始过程来避免这个问题,从而可以立即进行比较。这种方法有两个阶段。在第一阶段,初始用户故事被放置在普通视图中,例如放在墙上或桌子上。第一个团队成员获取下一个用户故事并将其放置:
- 在第一个故事的左边,表示它需要的工作比第一个故事少,
- 向右,表示它需要更多的工作,或
- 在另一个故事下面,表明它需要大约相同的工作量。
每个团队成员轮流放置相对于其他人的新用户故事。团队成员在轮到他们时还有另一个选择:如果他们不同意原始位置,他们可以将先前放置的故事移动到另一个位置。播放继续,直到没有更多故事并且没有人想要重新排列顺序。此时,故事具有相对顺序,但尚未分配故事点。这是在第二阶段完成的。
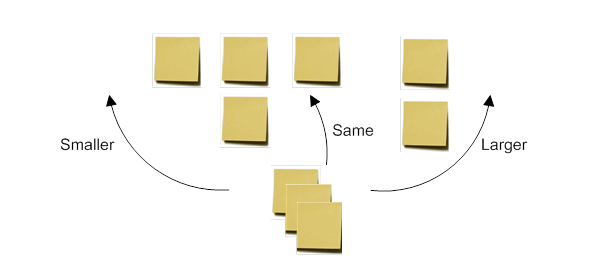
数字 2: 相对尺寸
第二阶段还需要斐波那契数列或类似的东西。数字 1 位于最左边的故事列上方,代表最小的用户故事。第一个团队成员取下一个数字 2,并将其放在他/她认为是第一列工作量两倍的故事之上。这不必是相邻的故事列。下一个玩家取下一个数字并以相同的方式将其分配给一列故事。每个玩家都有另外一个选择,即用他们的数字替换之前的数字,例如,他们可能觉得分配 5 的故事实际上可能是 8 并且没有 5,因此不使用 5。可选地,如果现在明显位置错误,则规则还可以允许玩家在分配了编号后移动用户故事。一旦所有数字都被放置并达成一致,不在数字下方的故事会被收集在前一个数字下方;它们实际上是向下舍入而不是向上舍入。
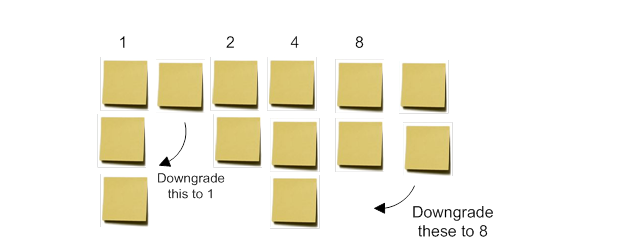
在这两款游戏中,零值也可以用于最小的用户故事被真正认为是 30 分钟的任务,并且可以以很少的成本或没有成本滚动到其他人的情况下。请注意,只有有限数量的零故事点项目是真正免费的。太多了,它们会加起来一个或多个故事点。
当需要对积压工作进行估算时(在 Scrum 术语中)以及在确定新故事或更改现有故事时,可以在项目全面展开之前使用这些估算方法。
下一个问题是,我们如何知道可以为任何迭代分配多少故事点?这就是速度的用武之地。
速度
速度是衡量一个团队在一次迭代中可以实现多少故事点的指标,基于之前的表现。故事点和速度必须保持抽象,以避免团队重新陷入绝对的、基于时间的估计的旧习惯。
但是通过推断,velocity 确实通过以下方式为故事点分配了绝对时间值:取整个团队在迭代中可用的天数,减去非编码/测试职责,例如假期、会议等,并除以速度。结果是每个故事点的团队人天数。例如:
- 一个 5 人的团队每 2 周迭代可能有 50 个团队日可用,
- 每个人平均每周有 1 天时间开会、休假或因其他原因不可用,即每次迭代 2 天,
- 他们的速度是 46.5。
50 – (5 x 2) / 46.5 = 每个故事点 0.86 个团队人天
重要的是要意识到“团队人员天数”的值是所有团队成员的平均值,并且所有团队成员都必须参与迭代才能使速度有意义。如果 3 名经验丰富的编码员被初级团队成员替换为迭代,则必须重新评估该迭代的预期速度。
虽然可以轻松计算故事点时间估计,但这样做并没有帮助。事实上,它破坏了故事点的整个概念,因为它导致了根据完成一个故事所需的时间来估计的诱惑,正如我们将看到的,这不是一个好的做法有很多原因。对于刚接触敏捷实践的工程师和经理来说,这种诱惑最大,尽管他们遵循敏捷原则,但如果没有在计划中的某处出现对“人日”的估计,就会感到相当不舒服。
将故事点与时间联系起来
那么,为什么我们不直接将故事点与时间联系起来,以便我们知道每个故事点以及每个故事需要多长时间才能完成?有两个主要原因,并且都与速度有关。
我们不想将故事点直接与时间联系起来的第一个原因是速度不是恒定的,至少它不应该是恒定的。随着团队成员对项目、流程、环境以及彼此之间的熟悉,他们的生产力应该会提高。换句话说,随着项目的进展,团队应该表现出速度的增加。如果我们直接将故事点与时间联系起来,我们只能为每次迭代分配相同数量的故事点,因为可用时间保持不变,而可变且不断增加的速度意味着团队工作得更快,因此我们可以分配更多的故事每次迭代的点数。
第二个原因对于具有多个团队的项目至关重要。团队的规模并不总是相同,再加上不同的经验和专业知识,会影响团队在一次迭代中可以完成的工作量。因此,团队速度很少相同。速度快的团队将比速度慢的团队完成更多的故事点。不同的速度告诉我们每次迭代可以为每个团队分配多少故事点。如果用时间来衡量故事,每个故事都需要对每个团队进行单独的时间估算,每个估算都不同,这显然是荒谬的。
认识到不同的团队具有不同的速度后,我们还应该能够得出结论,故事点的大小也可能因团队而异。每个团队可能对故事点对他们的意义有一致的看法,但跨团队,故事点可能不一样。这给我们留下了项目报告问题,因为无法聚合跨团队完成或计划的故事点;他们使用相同的术语,但不相同的措施。这也意味着团队之间的速度无法比较。事实上,7.5 的速度可能低于 6.2 的速度,因为第一团队的故事点的规模要小得多。如果每个团队都有自己的积压工作并进行自己的估算,那么所有这些都很好。除了举报,完全独立运作的团队不会有问题。但这就是我们想要的吗?
图 4:故事点大小可能因团队而异
归一化还是不归一化?
拥有完全自治的团队会降低敏捷项目中应存在的灵活性,以适应变化和新的用户故事。变化可能会要求故事从一个团队转移到另一个团队。事实上,如果产品负责人能够随着项目的进展动态地将故事分配给团队,而不是在开始时将所有故事都交给团队,那么他/她的工作就会容易得多。为了协调团队并使他们使用相同的估计值,他们必须对故事点具有相同的定义,这是通过称为规范化的过程实现的。
关于规范化是好事还是坏事,敏捷社区内部并没有达成一致的意见。有人说这是浪费时间,而且前期的故事分配效果很好。其他人说,团队需要在同一页面上,以实现完全的敏捷性和更轻松的状态报告。虽然辩论仍在继续,但值得研究规范化的方法。
归一化方法
为了使估计正常化,诱惑是再次按时回退;我们都知道 1 天是什么,那么为什么不使用它作为通用的度量单位而不是故事点呢?一旦我们这样做,我们就失去了我们之前讨论过的相对估计的所有好处。然而,在不诉诸时间估算的情况下,我们仍然可以使用一天的努力来为每个团队使用的参考故事带来一定程度的一致性,他们将根据这些故事来比较其他团队。
- 首先,在跨团队会议中,所有人都同意 1 天努力的定义(考虑假期、行政职责、会议等)。这有时被称为理想的开发者日,或简称为开发者日。
- 接下来,每个团队从他们熟悉的故事中选择一个符合约定定义的 1 开发者日参考故事。
- 最后,忘记了这个 1 个故事点参考估计需要 1 天的事实,故事点再次成为一个抽象的度量。
这个过程不会给出完美的故事点对称,但它会足够接近故事可以跨团队转移,并且聚合报告有意义。它还可以帮助刚接触敏捷过程的个人最初将故事点视为 1 天的努力,尽管应该抵制无限期地继续这种思维方式的诱惑。
如果需要更高的一致性,则可以使用另一种标准化技术,该技术涉及团队代表聚集在一起参加一个共同的估算会议,以确定他们已达成共识的故事。然后,他们使用为项目选择的方法估算每个故事,为每个故事分配故事点。或者,每个代表可以首先将故事集带回他们的团队进行估算,然后将这些结果用于更高级别会议的估算。这组故事现在提供了商定估计的基线,每个团队使用它来校准自己的估计过程。这种思想的交流甚至应该在第一次迭代之前发生;在估算开始之前,然后偶尔在整个项目中重新同步。
请记住,规范化不是强制性的,只有在相信项目的收益值得时才应该花费所需的努力:毕竟,归根结底,一切都与投资回报 (ROI) 有关。
关于规范化的最后一句话。有些人认为他们正在使跨团队的速度正常化,以便可以比较团队的表现。这是完全无效的。正如我们所展示的,团队规模、经验和环境可能会有很大差异,因此,无论故事点是否正常化,速度应该并且确实会随着时间的推移在不同的团队甚至同一团队中有所不同。
“无估计”方法
由于比较跨团队的估计存在问题,加上一些研究发现,简单地计算所有需求或用户故事(即它们都是相同的大小)导致项目和发布估计在统计上与使用故事点相同,有朝着没有估计的方向发展(#NoEstimat e )。近年来,这种方法在行业中越来越受欢迎。
除了在简化规划过程方面给团队带来的好处(没有人特别喜欢估算工作,让我们面对现实吧),使用简单的用户故事计数可以更容易地跨项目进行比较。
结束
在所有这些过程中必须记住,评估本身并不是目的,因此在敏捷哲学下,应该使用尽可能少的努力来完成工作。对于积压的优先级排序和为每次迭代实现有意义的分配,估计是必要的,但深入挖掘以提高准确性是浪费。通过这样做,用户故事开始进行分析,这应该是实施的一部分,而不是估计和计划的一部分。与许多活动一样,收益递减规律也适用于估计;“不要花太长时间,你不会得到明显更好的结果。”
最后,最好的估计来自整个团队的集体意见。只使用你的经理或专家往往会导致乐观的估计。相反,主要使用团队中的新人可能会导致估计值超出必要范围。包括所有人;毕竟,这是敏捷方式。
- What is Agile Estimation?
- What is Story Point in Agile? How to Estimate a User Story?
- User Story Splitting - Vertical Slice vs Horizontal Slice
- How to Prioritize Product Backlog Using MoSCoW Method
- How to Prioritize Product Backlog Using 100 Points Methods?
- What is a Sprint Goal in Scrum?
- What is Burndown Chart in Scrum?
posted on 2021-11-18 14:33 Lynch_Warren 阅读(1180) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号