

hdfs的FileSystem实例化
前言
在spark中通过hdfs的java接口并发写文件出现了数据丢失的问题,一顿操作后发现原来是FileSystem的缓存机制。补一课先
FileSystem实例化
FileSystem.get(config)是如何创建一个hadoop的FileSystem。
分为3个步骤。
1. 初始化所有支持的FileSystem(没有实例话,只是缓存类)
2. 通过uri的scheme拿到相应FileSystem
3. 缓存机制(如果不关闭的话,默认是开启)
下面详细分析一下各步骤流程
1. 初始化
通过java提供的ServiceLoader来录入所有可能的FileSystem,就像这样
ServiceLoader<FileSystem> serviceLoader = ServiceLoader.load(FileSystem.class); for (FileSystem fs : serviceLoader) { SERVICE_FILE_SYSTEMS.put(fs.getScheme(), fs.getClass()); }
待初始化的类通过配置文件声明,配置可以在hadoop-hdfs.jar里找到
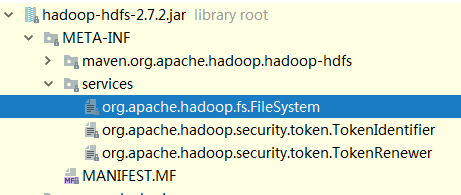
捎带一嘴,java提供的ServiceLoader有点像乞丐版spring的依赖反转。
2.scheme
通过对Uri的解析来判断创建一个什么FileSystem,
例如
hdfs://master:9200/test的scheme就是hdfs。
然后通过scheme和已经缓存好的FileSystem映射,找到需要实例化的类。
例如scheme是hdfs,那么就会创建一个DistributedFileSystem。
3. 缓存
FileSystem类中有一个Cache内部类,用于缓存已经被实例化的FileSystem。注意这个跟连接池还是有区别的,Cache中的缓存只是一个map,可以被多个线程拿到。这就会有一个问题,当你多线程同时get FileSystem的时候,可能返回的是同一个对象。所以切记,在多线程场景中,不要随意调用FileSystem.close,你关的连接可能会影响到其他正在使用的线程。
注意: 当你在其他框架上拿fileSystem对象需要额外注意,例如在spark上进行 FileSystem.get(),如果你想自定义某些配置,设置hdfs的副本数(dfs.replication) 之类,你必须在configuration中关闭FileSystem的缓存机制,也就是设置
configuration.set("fs.hdfs.impl.disable.cache","true")
这很重要,因为你不确定spark是否在你之前创建了一个FileSystem,而你得到的可能不是你想要的。
参考资料
// 遇到的相同问题
新博客地址
http://ixiaosi.art/
欢迎来访 : )


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构