
前言
zabbix一直是小规模互联网公司服务器性能监控首选,首先是免费,其次,有专门的公司和社区开发维护,使其稳定性和功能都在不断地增强和完善。zabbix拥有详细的UI界面和分组策略,在被监控的服务器上安装好agent后,无需添加任何监控选项,因为zabbix自带一些必要的监控,如agent.ping之类,zabbix支持画图,这个是专门给boss们看的,极其重要。另外还支持用户自定义监控选项,这一点非常方便,今天我要说的就是磁盘监控,标题中为动态的监控,意指智能的识别磁盘个数,并生成相应的监控选项,因为每台服务器的磁盘可能不一样,所以我是使用zabbix的discovery方式。
个人认为其UI界面是比较复杂的,但是毕竟越复杂越显得高端。我常用的不算configure和administration标签下所有的选项(这是必不可少的),也就graphs和screen,这两个选项是在monitor标签下的,也是BOSS们最关注的。
说到底,所有的自动判断都是人为的设置好所有的可能性,然后根据实际情况从中选择,方法有很多,看大家具体要求。在这里,我要对磁盘监控,首先要找出有哪些磁盘,这里使用shell脚本实现。
脚本如下:
cat diskstats.sh
#!/bin/bash
diskarray=(`cat /proc/diskstats |grep -E "\bsd[abcdefg][0-9]*\b|\bdm-[0-9]*\b"|grep -i "\b$1\b"|awk '{print $3}'|sort|uniq 2>/dev/null`)
length=${#diskarray[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$length;i++))
do
printf '\n\t\t{'
printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
如上,这里通过读取/proc/diskstats,选择其中的磁盘,根据实际情况,我这里就找出类似sda或者dm-的,一定要按实际情况改写脚本。
测试执行:zabbix_get -s 192.168.191.166 -k io.scandisk
得到如下信息:
{
"data":[
{"{#DISK_NAME}":"dm-0"},
{"{#DISK_NAME}":"dm-1"},
{"{#DISK_NAME}":"dm-2"},
{"{#DISK_NAME}":"sda"},
{"{#DISK_NAME}":"sda1"},
{"{#DISK_NAME}":"sda2"}
]
}
然后使用zabbix执行这个脚本,那么就要将其写到zabbix_agentd.conf中去,如下:
UserParameter=io.scandisk[*],/infra/zabbix/os/disk_scan.sh $1
对于磁盘的监控我采用iostat命令,因为它能给出磁盘的详细信息,如扇区读写情况,io队列长度,iowait,svctime等等。
命令如下:
nohup iostat -m -x -d 30 >/tmp/iostat_output &
通过tail -f /tmp/iostat_output,可获得iostat命令收集的磁盘信息,结果类似下面:
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
fd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.43 1.63 66.07 0.09 0.45 16.55 0.47 6.90 8.41 6.86 4.75 32.18
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-0 0.00 0.00 1.63 66.47 0.09 0.45 16.45 0.47 6.93 8.39 6.89 4.73 32.19
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
最开始已经说了,是结合zabbix的discovery功能,所以要对zabbix做出如下设置。

这里的键值一定要用在UserParameter里定义好的键值才能把磁盘自动发现上来。
然后建监控项原型:
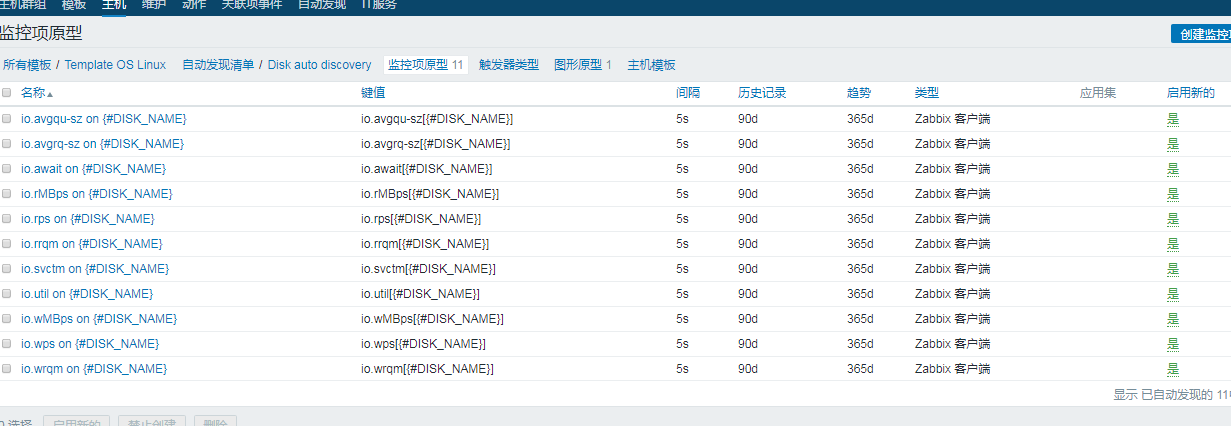
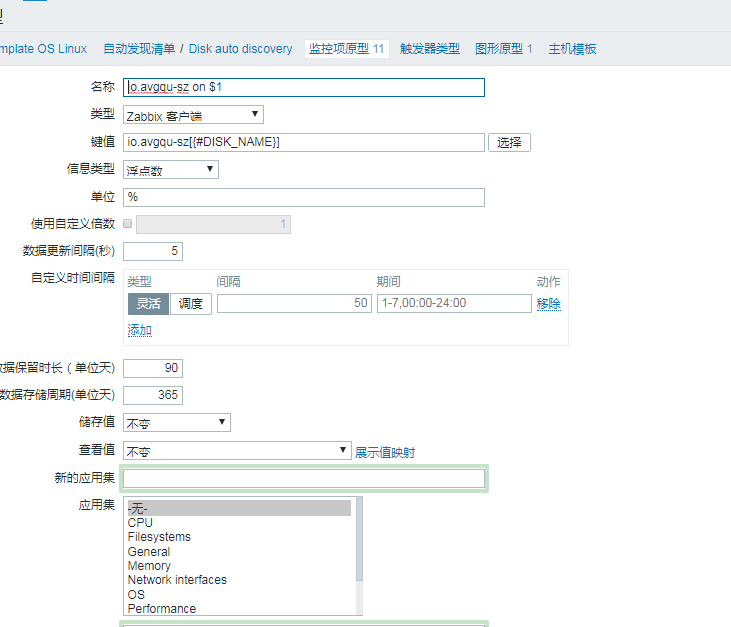
在建立好item之后,zabbix_agentd.conf中也要写上相应的UserParameters,如下。
UserParameter=io.scandisk[*],/infra/zabbix/os/disk_scan.sh $1
UserParameter=io.rrqm[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b"|tail -1|awk '{print $$2}'
UserParameter=io.wrqm[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b"|tail -1|awk '{print $$3}'
UserParameter=io.rps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b"|tail -1|awk '{print $$4}'
UserParameter=io.wps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$5}'
UserParameter=io.rMBps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$6}'
UserParameter=io.wMBps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$7}'
UserParameter=io.avgrq-sz[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$8}'
UserParameter=io.avgqu-sz[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$9}'
UserParameter=io.await[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$10}'
UserParameter=io.svctm[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$11}'
UserParameter=io.util[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$12}'
建图形原型:
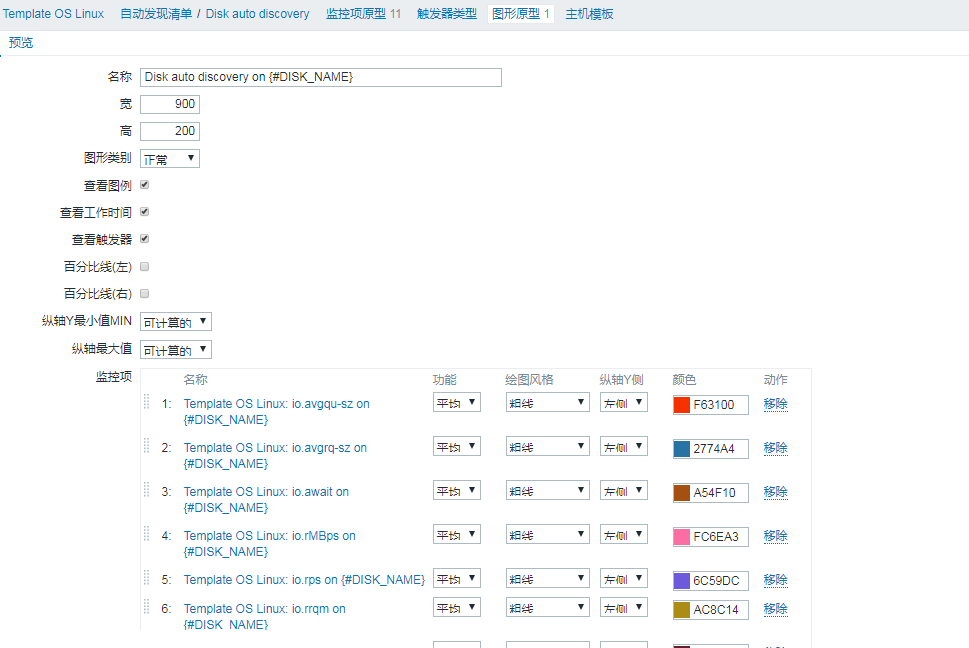
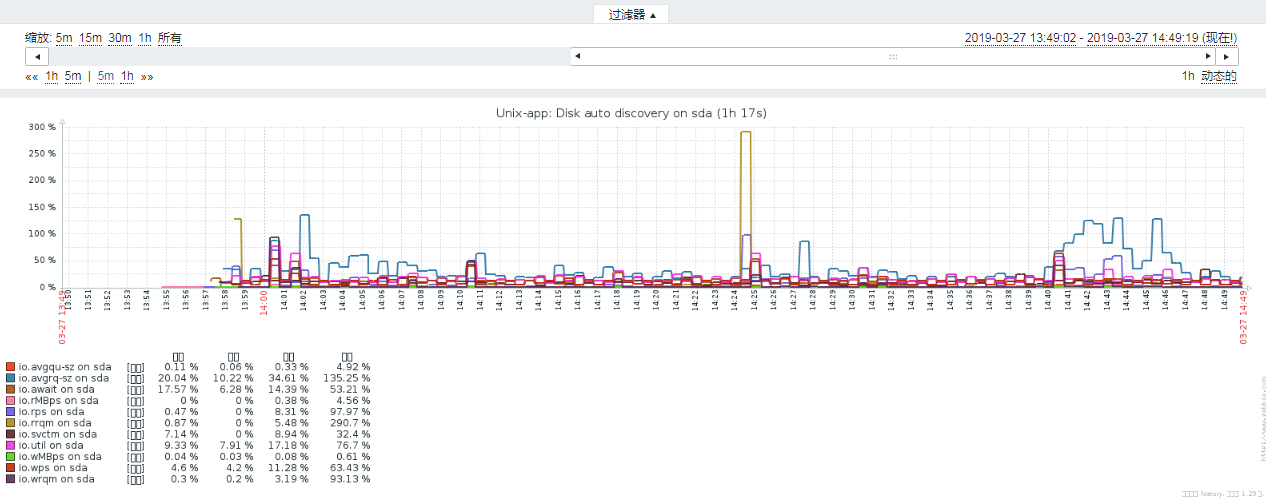
最终效果图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号