前言
六七八次的PTA作业主要部分是学生课程成绩统计系统,与之前的菜单点菜系列相似,甚至是更为简单,有了前面几次菜单计价题目的折磨,写课程成绩统计程序题目相对来说比较容易了,但在课程成绩统计程序1的构思上我觉得是最难的,也是花了相当多的一部分时间来尝试自己把主要框架搭建出来,最终迫于无奈,能力有限,听了老师的思路和同学讨论后才把最难的课程成绩统计程序写了出来,后面课程成绩统计2和课程成绩统计3无非是在1的基础上添加一些细节。
对于非课程成绩统计程序题,第七次第一第二题主要是考察了对于HashMap的运用对于键值对的理解,可能是因为老师刚好讲到Map才会出这么两道题吧。而第七次作业第四题又是考多态,估计是怕我们过了这么久忘了出给我们巩固一下。
第八次主要是考察接口,比如第一题和第三题用了Comparable接口,第四题用了一个自定义接口。
设计与分析
本次作业分析参考SourceMonitor的生成报表内容以及PowerDesigner的相应类图,部分题目比较简单就简单文字分析一下不用报表和类图来分析了,主要用报表和PowerDesigner来分析课程成绩统计程序系列。
第一次作业
7-1 课程成绩统计程序-1
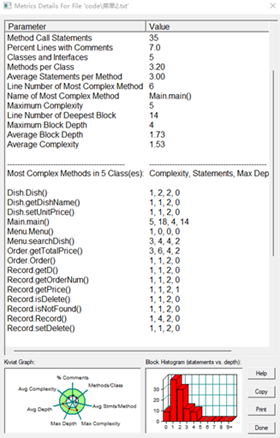
SourceMonitor生成报表:
powerdesigner生成类图:
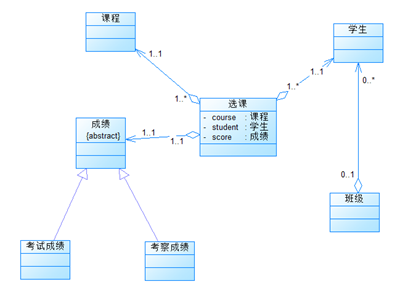
个人认为难度最大的一题(相对来说),毕竟这种大作业构思起来就比较难,跟着老师的思路来写还是没有什么太大的问题,按照题目给出的类图创建了Stu学生类,用于储存学生个人的成绩信息;Course课程类,储存每门课程的课程种类如选修必修,课程考核方式,如考试考察。Cls类用于储存每个班的总平均分情况,ChooseCourse类用于吧课程类学生类分数类联系到一起,Grader类储存分数,这里用到了继承,Grader2继承了Grader类,用于储存考察的分数。在学生类课程类和课程类里各放一个ChooesCourse类列表,用于通过学生来获取课程的总平均分,和通过课程来获取所以学生的成绩来计算平均分,如下
ArrayList<ChooseCourse> chooseCourses = new ArrayList<ChooseCourse>();
for(Course cou:courses)
{
if(cou.chooseCourses.size()==0)
{
System.out.println(cou.name+" "+"has no grades
yet");
}
else {
if (cou.method.equals("考试")) {
System.out.println(cou.name + " " + cou.usualaverage + " " + cou.finalaverage + " " + cou.courseAverage);
}
if (cou.method.equals("考察")) {
System.out.println(cou.name + " " + cou.finalaverage + " " + cou.courseAverage);
}
}
}
这里课程结果输出为例。
而题目中的排序问问题同样比较头痛,最难的实则是课程名称的排序,需要考虑中英文混合排序,在我的代码里则是直接照搬了老师的代码如下
class Course implements Comparable<Course>
引用接口;
public int compareTo(Course o) {
Comparator<Object> compare =
Collator.getInstance(java.util.Locale.CHINA);
return compare.compare(name,o.name);
}
重写compareTo方法,具体里面的内容我没有深究下去,以后碰到类似的直接ctrl+C ctrl+V。
其中我觉得最重要的还是分析代码,我在主类中创建了一个analyse方法来解析输入的字符串,再把解析后得到的数据存到相应的数组列表中以供使用,光是这一个方法起码占了整个源码的三分之一以上了。 在解析输入字符串是普通的错误处理很难满足题目要求,于是老师给了我们一段正则表达式来专门处理对于字符串的初步解析
public static int matchingInput(String s) {
if (matchingCourse(s))
{
return 1;
}
if (matchingScore(s)||matchSecondScore(s))
{
return 2;
}
return 0;
}
这一段就可以初步分辨出输入的是错误数据还是课程数据或学生成绩。具体才会到Analyse方法里面进一步的分析。其余没有什么大问题了。
7-3 课程成绩统计程序-2
SourceMonitor生成报表:
powerdesigner生成类图:
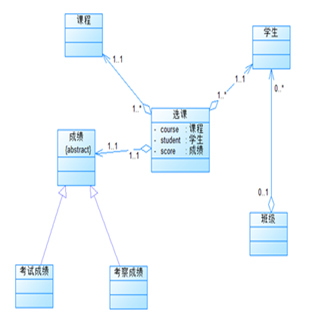

课程成绩统计程序-2在课程成绩统计程序-1的课程类型中加入了实验课,考核方式也多了实验,并且实验课只能以实验来考核,其他类型课程均不能以实验来作为考核。我在课程成绩统计程序1的代码中加了一百行不到的代码就完成了这题,甚至比第一次得分还要高。
增加了一个Grader3类继承Grader类,作为实验成绩的储存,
class Grade3 extends Grade{
int expNum;
ArrayList<Integer>score;
public Grade3(int expNum,ArrayList<Integer>score){
this.expNum=expNum;
this.score=score;
}
public int getScore(){
int expScore=0;
for(Integer temp:score){
expScore=temp+expScore;
}
return expScore/score.size();
}
}
因为实验的次数在4到9次之间不定,所以这里采用了一个数组列表score来储存所有的实验分数,也是因为这个我才知道原来构造器里也可以放数组列表,从analys方法那里解析出来的分数直接存到里面即可。
因为看课程信息的增加,导致上一题的正则表达式必须要进行一定的修改,如下
static String courseTypeMatching = "(选修|必修|实验)";
static String checkcourseTypeMatching = "(考试|考察|实验)";
static String thirdScoreInput = stuNumMatching + " " + stuNameMatching + " " + courseNameMatching + " " +
textMuchMatching
+scoreMuchMatching+scoreMuchMatching+scoreMuchMatching
+scoreMuchMatching+scoreMuchMatching+scoreMuchMatching
+scoreMuchMatching+scoreMuchMatching+scoreMuchMatching;
主要修改的地方就是这里,依照老师上次给的代码,照葫芦画瓢也算是写出来了。
在analysis方法中对于错误数据的处理给我折腾了老半天,第一次放在pta中运行课程于考核方式不匹配那几个测试点一直错误,我考虑了实验课程中考试和考察的错误,却没考虑必修课程中实验和选修课程中实验的错误情况。
7-2 课程成绩统计程序-3
SourceMonitor生成报表:
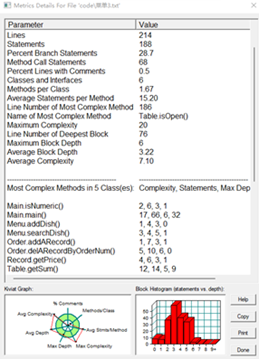
powerdesigner生成类图:
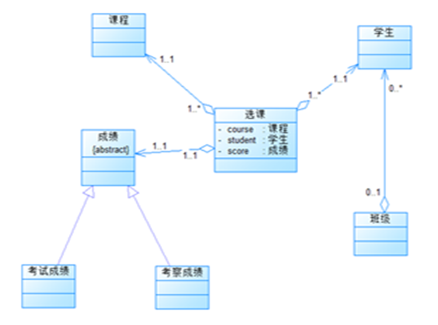
这题相较于课程成绩统计程序2多加了一个课程成绩的权重,看上去比较唬人,实际上做起来还是比较简单的,并且对于课程成绩的输出有了些许修改,比如说必修课的平时平均分和期末平均分删去。
和上一题一样,我也在Grader3类中加了一个储存权重的数组列表,如下
public void setEW(ArrayList<Float> EW) {
this.EW = EW;
}
而对于必修的总评成绩权重只有两个所以不需要数组列表,加两个表示权重的参数就行了。
可能稍微复杂一点的就是analys方法解析字符串的修改那比较麻烦了,因为数据太多,要准确算出数组哪一个元素对应什么,只要细心一点也没啥大问题。
首先,需要创建一个HashMap对象来存储数据。HashMap是一种键值对的数据结构,可以用来存储和检索数据。
7-1容器-HashMap-检索
接下来,需要向HashMap中添加一些数据。可以使用put()方法将键值对添加到HashMap中。
在检索数据时,首先需要获取用户输入的键值。可以使用Scanner类来获取用户输入。
然后,使用get()方法从HashMap中检索数据。get()方法接收一个键作为参数,并返回与该键关联的值。
最后,根据检索结果输出相应的信息。如果检索成功,输出对应的值;如果检索失败,输出提示信息。
需要注意的是,在使用HashMap时,键值对的键是唯一的,不能重复。因此,在添加数据时,需要确保键的唯一性。另外,为了提高检索的效率,可以使用合适的哈希函数来分配键的存储位置。
7-2 容器-HashMap-排序
首先,需要创建一个HashMap对象来存储数据。HashMap是一种键值对的数据结构,可以用来存储和检索数据。
接下来,向HashMap中添加一些数据。可以使用put()方法将键值对添加到HashMap中。
然后,将HashMap中的键值对转换为一个List对象。可以使用HashMap的entrySet()方法获取所有的键值对,然后使用ArrayList的构造函数将其转换为List对象。
接着,使用Collections类的sort()方法对List对象进行排序。sort()方法默认使用对象的自然顺序进行排序,如果需要自定义排序规则,可以实现Comparator接口并传递给sort()方法。
最后,根据排序结果输出相应的信息。可以使用for循环遍历排序后的List对象,并使用getKey()和getValue()方法获取键和值。
需要注意的是,在使用HashMap时,键值对的键是唯一的,不能重复。因此,在添加数据时,需要确保键的唯一性。另外,排序操作会改变原始的HashMap对象,因此在进行排序之前,可以选择创建一个副本来保留原始数据。
7-1 容器-ArrayList-排序
首先,需要创建一个ArrayList对象来存储数据。ArrayList是一种动态数组,可以用来存储和操作数据。
接下来,向ArrayList中添加一些数据。可以使用add()方法将元素添加到ArrayList中。
然后,使用Collections类的sort()方法对ArrayList进行排序。sort()方法默认使用对象的自然顺序进行排序,如果需要自定义排序规则,可以实现Comparator接口并传递给sort()方法。
最后,根据排序结果输出相应的信息。可以使用for循环遍历排序后的ArrayList对象,并输出每个元素。
需要注意的是,在使用ArrayList时,可以存储任意类型的对象。如果需要对自定义对象进行排序,需要确保对象实现了Comparable接口或者提供了Comparator接口的比较器。
另外,排序操作会改变原始的ArrayList对象,因此在进行排序之前,可以选择创建一个副本来保留原始数据。
踩坑心得
这三道课程成绩统计题难度差不多,第一道课程成绩统计题没有优化几次就能过,而菜单二菜单三在刚写完能运行的基础上放到pta里提交基本上只能过少数几个测试点,后期只能一个测试点一个测试点的改良优化,我的经验是,对与课程成绩统计程序这种题只能一步一步优化出来,而不能急于求成,不要想着一遍过,只能一点一点的拿分,通过测试点的测试条件来找到自己代码中有哪些不足。、
值得注意的是课程成绩统计2和3在pta上提交时有较多测试点会提示超时,如果没有超太多,多提交几次说不定之前超时的测试点就会过,我的课程成绩统计3第一次提交只有28分,在确认没有逻辑上的问题后用同样的代码多提交几遍最后拿到了52分。
总结
这三次pta作业中除了三次课程成绩统计题,其他大部分是对java语言的基础考察,通过这些问题,我也学到了许多java中非常有用的方法,也深切体会到java这门语言的方便之处,毕竟有这么多现成的方法可供使用。而重三次课程成绩统计题主要是考察了对象和类,也是通过这三题我慢慢的体会到了java中面向对象这一概念。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号