
已经有 Prometheus 了,还需要夜莺?
谈起当下监控,Prometheus 无疑是最火的项目,如果只是监控机器、网络设备,Zabbix 尚可一战,如果既要监控设备又要监控应用程序、Kubernetes 等基础设施,Prometheus 就是最佳选择。甚至有些开源项目,已经内置支持了 Prometheus 协议的指标暴露,比如新版本的 Zookeeper、新版本的 RabbitMQ、Nginx vts 等等。Prometheus 的影响力可见一斑。
很多场景里讲到的 Prometheus 这个词,其实已经不仅仅是 Prometheus 项目本身了,而是 Prometheus 生态,包括 Prometheus 定义的指标格式、传输协议、查询语言、各类 Exporter 采集器、各类兼容的存储等。
在 Prometheus 生态里,采集可以使用各类 Exporter,存储可以使用 VictoriaMetrics,看图可以使用 Grafana,看起来已经非常完备了,为啥又冒出一个“夜莺(Nightingale)”的开源项目,还声称和 Prometheus 无缝对接?本文尝试探讨一二。
夜莺介绍
从夜莺官网摘出一段夜莺项目介绍:
夜莺监控是一款开源云原生观测分析工具,采用 All-in-One 的设计理念,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。夜莺于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 100 多个版本。
夜莺最初由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。夜莺的核心研发团队,也是 Open-Falcon 项目原核心研发人员,从 2014 年(Open-Falcon 是 2014 年开源)算起来,也有 10 年了,只为把监控这个事情做好。
看完项目介绍,只能知道夜莺是一个监控系统,到底和 Prometheus 有哪些差异点,暂时没有看出来。别急,我们先来看看 Prometheus 的问题。
Prometheus 的问题
Prometheus 的采集、存储、看图都已经解决的挺好了。唯独就是告警,对某些公司来讲,可能会有如下痛点:
- 一个公司有很多套 Prometheus,规则分散在多个 yaml 中不方便管理
- 希望能有一套易用的、权限隔离的 UI,把监控能力开放给全公司各个团队并让他们自服务,别啥事都来找监控团队
- 直接使用 Promql 查询数据、配置告警规则要求有点高,能否内置一些规则库、查询语句,让知识可沉淀,让普通用户也能开箱即用
- 告警规则希望能够更灵活一些,比如支持不同的规则不同的生效时间,能够内置提供一些告警自愈的机制等等
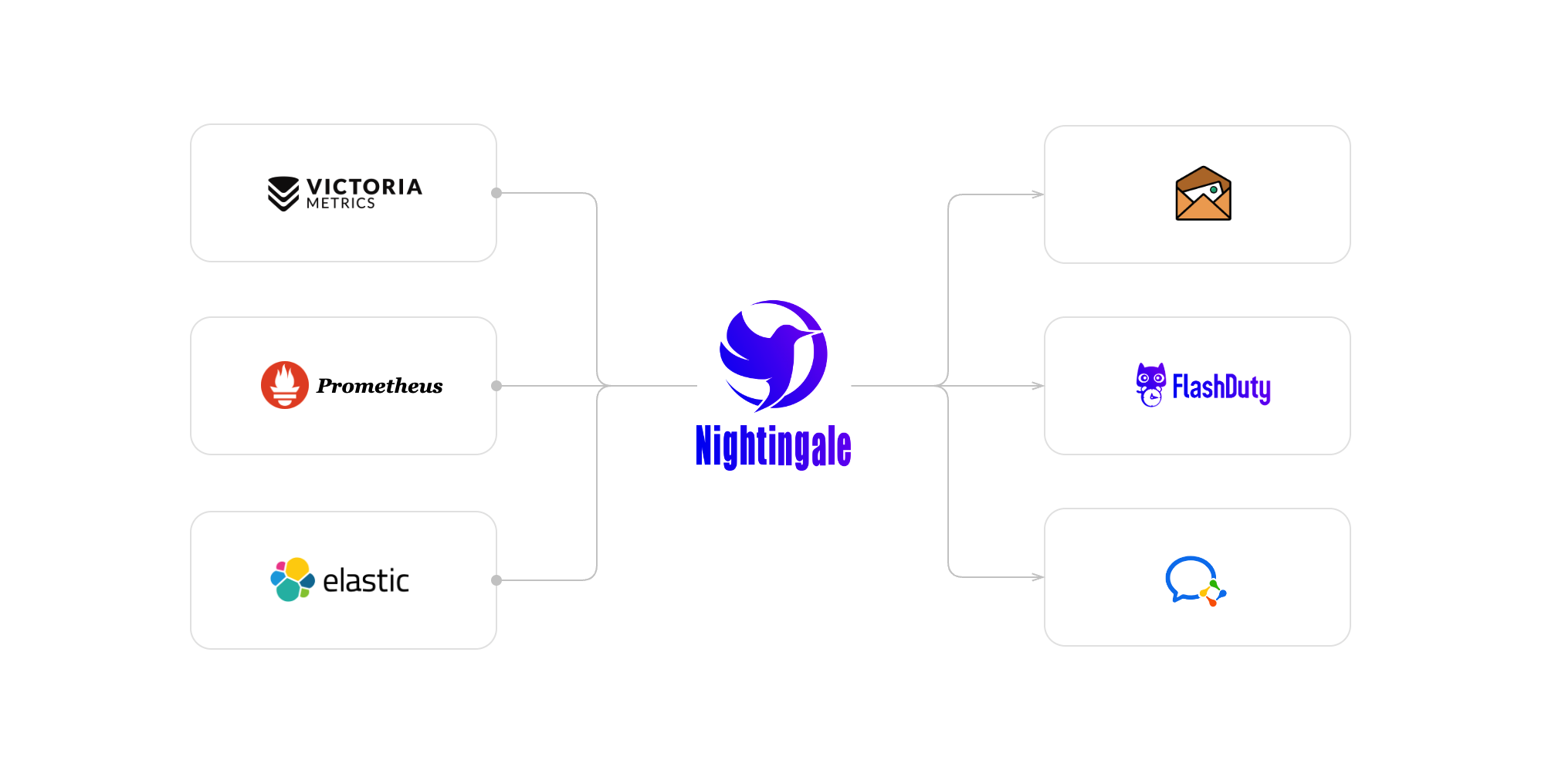
夜莺就是为此而生的。其实夜莺老版本是自成体系的,脱胎自 Open-Falcon,但是随着 Prometheus 大势起来,夜莺就开始拥抱 Prometheus 生态了。可以把夜莺看做是时序数据的告警引擎。当然,夜莺也提供看图、仪表盘的能力,甚至可以查看 Elasticsearch、Loki、TDEngine 的数据,不过当前现状就是夜莺的告警能力大家用的最多,仪表盘大都仍然使用 Grafana 居多。典型的夜莺使用的架构如下:
可以用夜莺完全替代 Prometheus 吗?
其实不是替代的关系,是协同的关系。在夜莺看来,Prometheus 主要是作为时序库使用,除了 Prometheus 这个时序库,还可以选择 VictoriaMetrics、Thanos、M3DB、TDEngine 等其他时序库。夜莺呢,则只是作为一个时序库的告警引擎,既可以对接 Prometheus,也可以对接其他时序库,用户在夜莺里统一管理告警规则,对异常数据做判定,产生告警事件,并做后续分发通知、告警自愈等逻辑。
另外,如果你有多个机房,时序库分散在多个机房,机房之间的网络不好,即便发生网络割裂你也希望边缘机房能够自治不影响告警,夜莺也非常合适。这种情况夜莺称为边缘机房部署模式,时序库和告警引擎下沉部署,网络断了也没事,网络好的时候还可以在中心端统一查看数据,统一管理告警规则,其架构图如下:
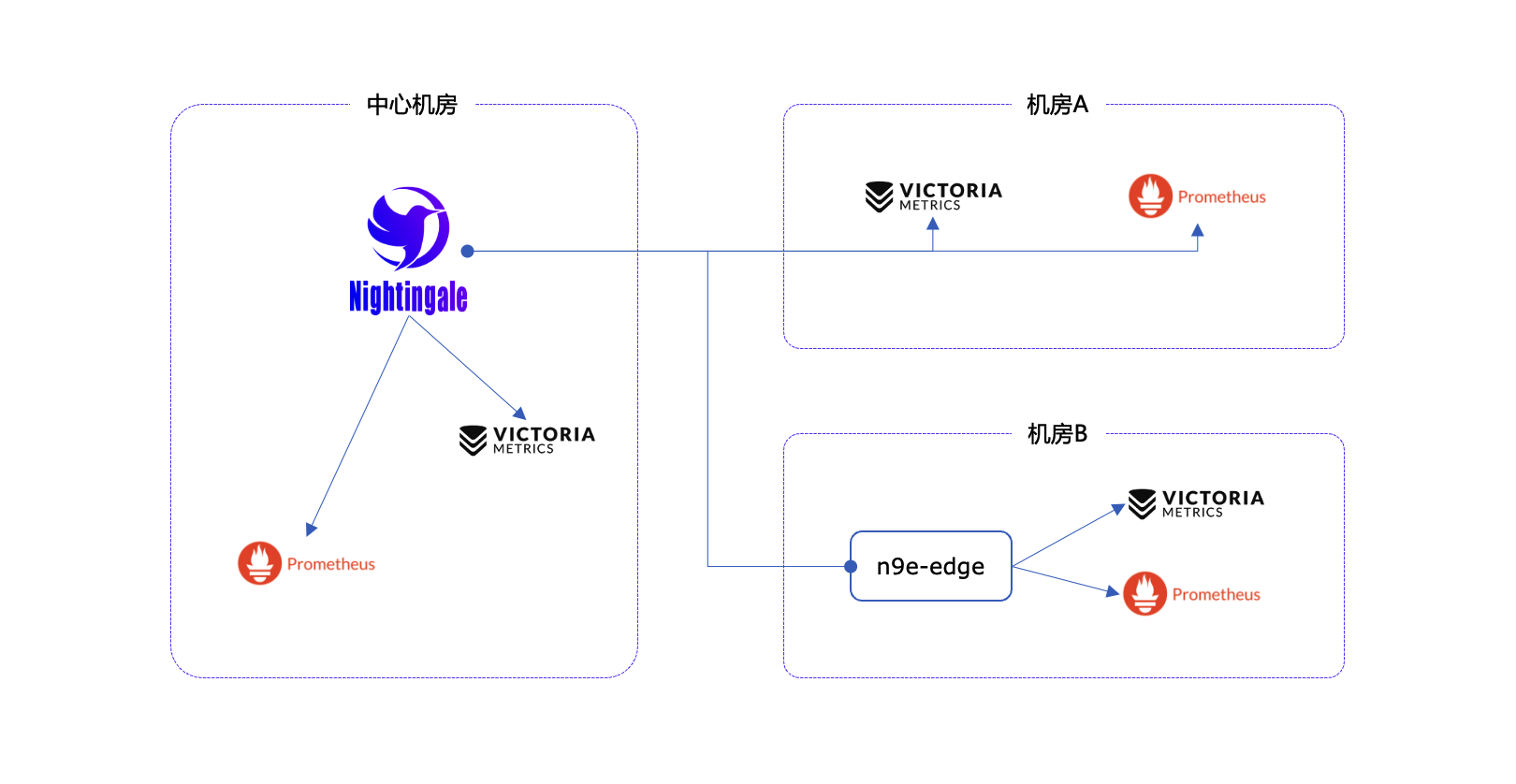
上例中,演示了 3 个机房的部署架构,其中机房 A 和中心机房之间网络链路很好,机房 B 和中心机房之间的网络链路不太好,各个机房都有时序库。所以,中心机房的夜莺告警引擎直接处理中心机房和机房 A 的时序库,机房 B 的时序库由机房 B 的告警引擎处理,也就是图中的 n9e-edge,n9e-edge 会从中心机房的夜莺同步告警规则,然后对本机房的时序库做告警判定。
这样一来,即便机房 B 和中心机房之间网络割裂,由于 n9e-edge 内存中早就同步到了告警规则,所以机房 B 的告警引擎还是可以正常处理机房 B 的两个时序库的告警判定工作。提升了监控系统整体高可用性。
什么场景用夜莺而非 Prometheus?
关键看你的痛点是什么。如果现阶段使用单点的 Prometheus 也可以很好的解决你的问题,完全没必要换,在任何公司,技术工具的迁移都是会受到各种阻力的,懂的自然懂。
如果你有告警规则管理的痛点、边缘机房告警高可用的痛点,那可以尝试一下夜莺。任何工具都有自己的优缺点,根据场景选择。
夜莺可以接收各类监控系统的告警统一做事件通知吗?
有些朋友看到夜莺可以对接各类时序库,做告警判断生成告警事件并分发,就想说,那我其他的监控系统产生的告警能否也交给夜莺去发送呢?这样就可以统一管理告警通知模板、联系人、认证登录权限等问题。
实际是不行的。这是一个典型的事件 OnCall 需求,收集各个监控系统(比如 Prometheus、Zabbix、Open-Falcon、蓝鲸、各类云监控、ElastAlert 等)的告警,统一做告警收敛降噪、排班、认领升级、按条件灵活分发等,这个需求要想做好,值得用一个单独的产品来搞,我们姑且称这个产品为 OnCall 产品。OnCall 产品和各个监控系统之间的关系是:
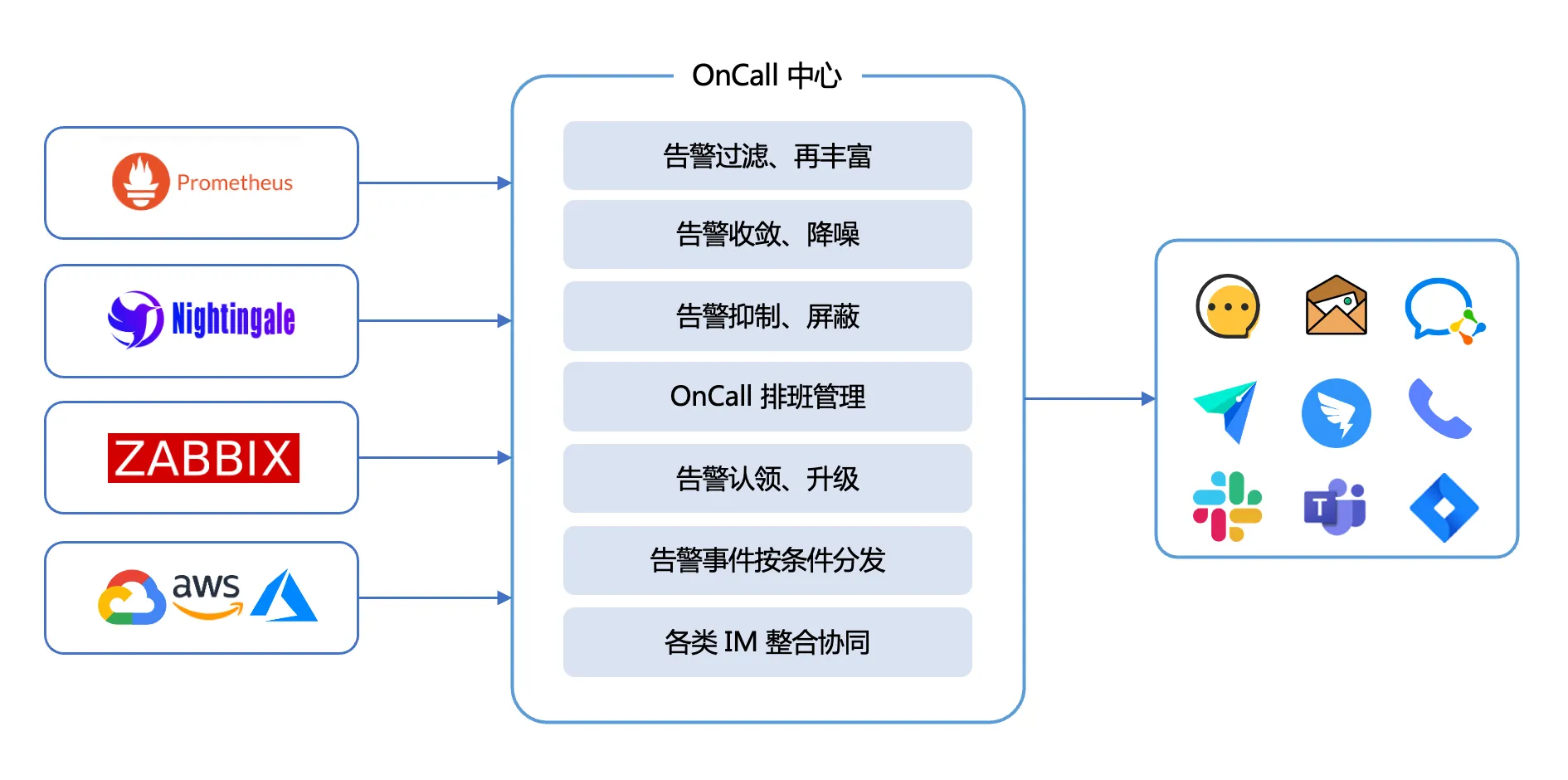
即:监控系统(包括各类云监控)重点把数据采集、存储、可视化分析、告警判定这些问题解决好,负责产生告警事件,之后告警事件就交给 OnCall 中心来处理即可,OnCall 中心来负责告警事件的收敛降噪、抑制屏蔽、过滤分发等等诸多事宜。
好的 OnCall 产品都是商业产品,比如 PagerDuty、FlashDuty、Opsgenie 等,大家可以自行 Google,各取所需。
夜莺比 Prometheus 还多了啥有意思的功能?
这里我随便截几张系统图,略作介绍。
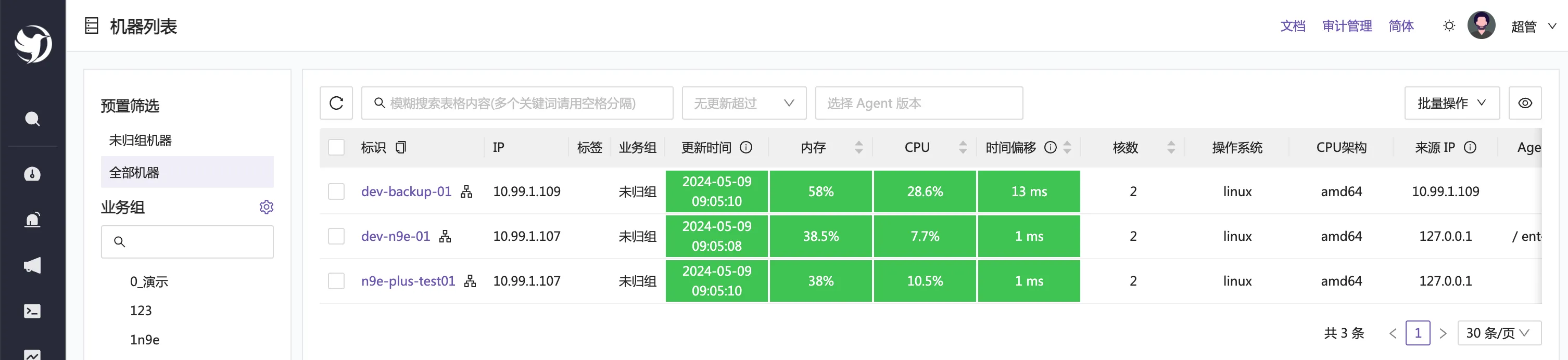
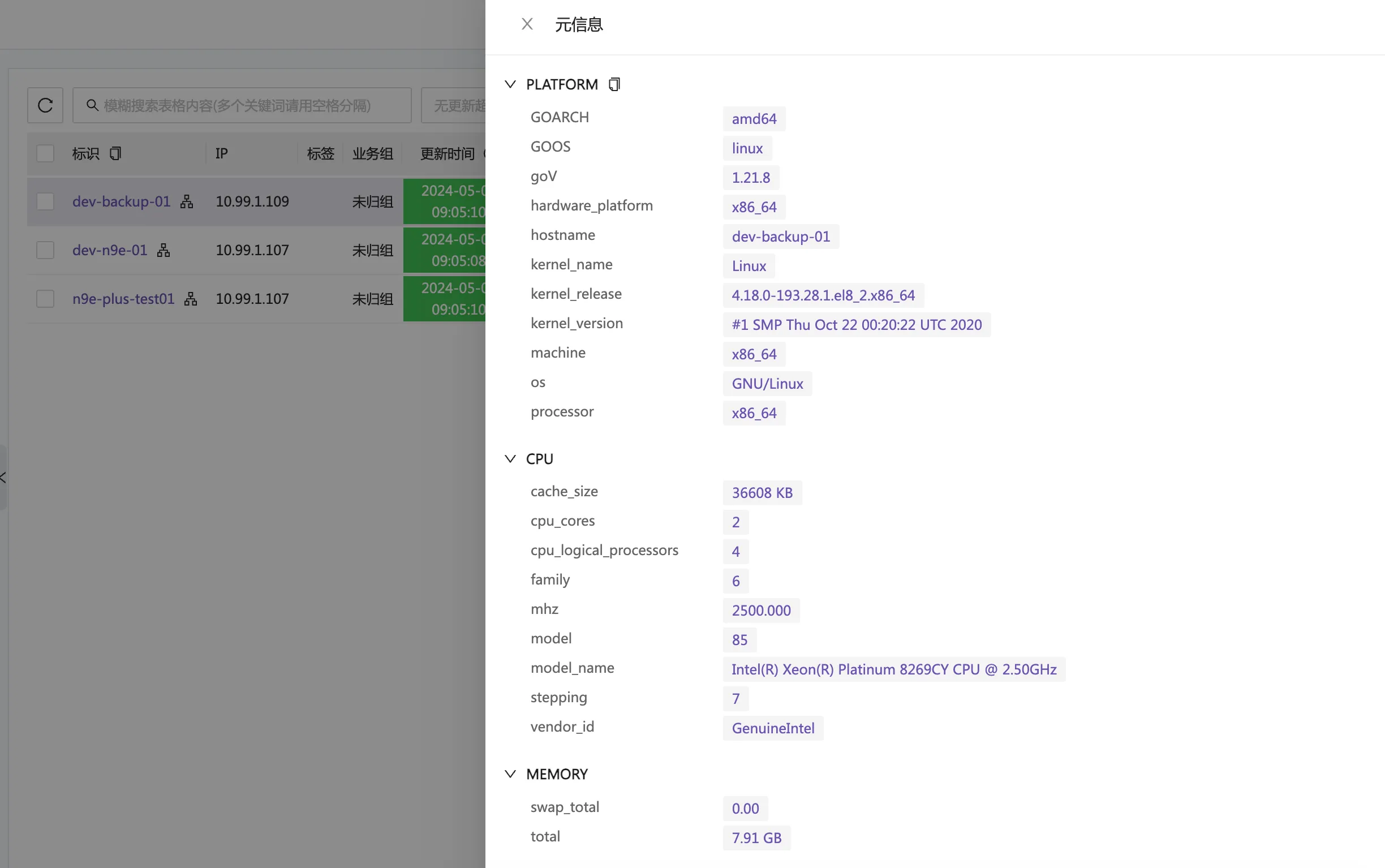
夜莺不做采集,可以对接市面上各类采集器,其中,categraf 采集器和夜莺的对接最为丝滑,使用 categraf 作为采集器的话,可以采集机器的各类元信息,构建一个轻量的机器层面的 CMDB。
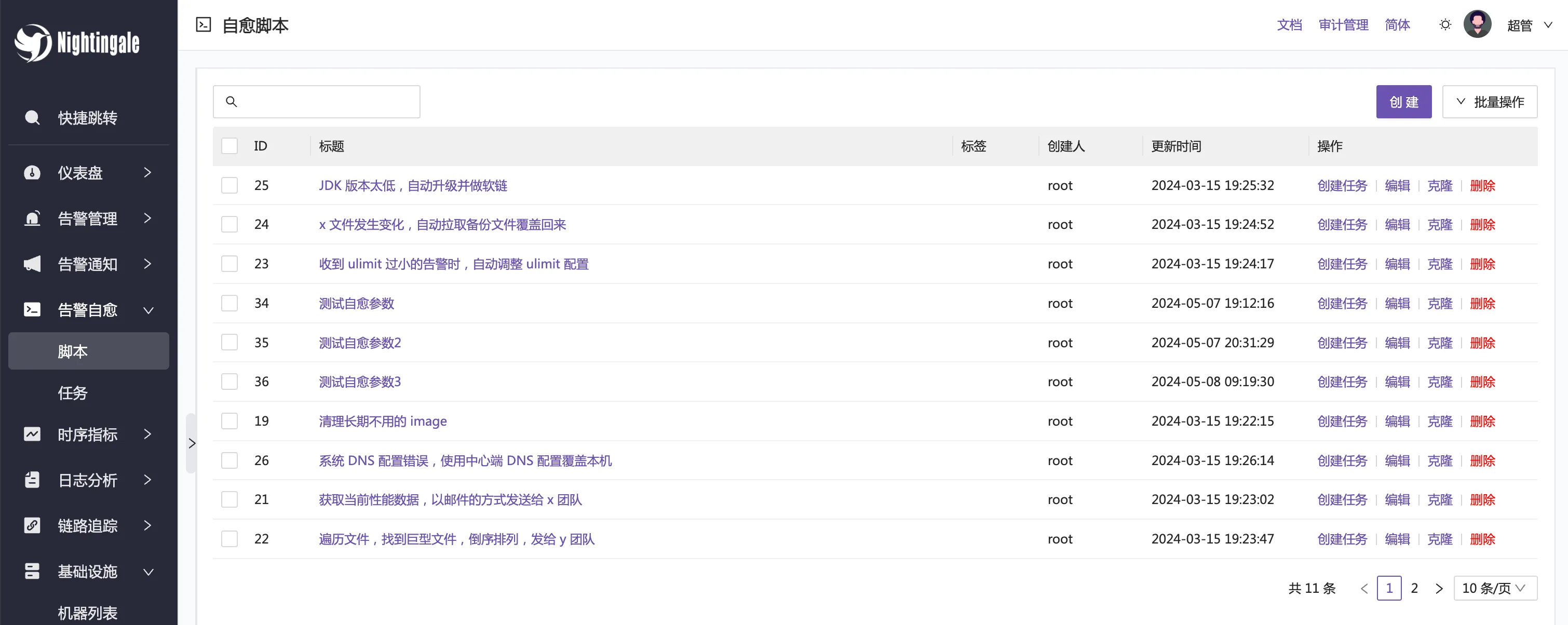
夜莺内置提供告警自愈的能力,即告警时可以自动到告警的机器上执行脚本,你可以在脚本里写一些自动化的修复逻辑。
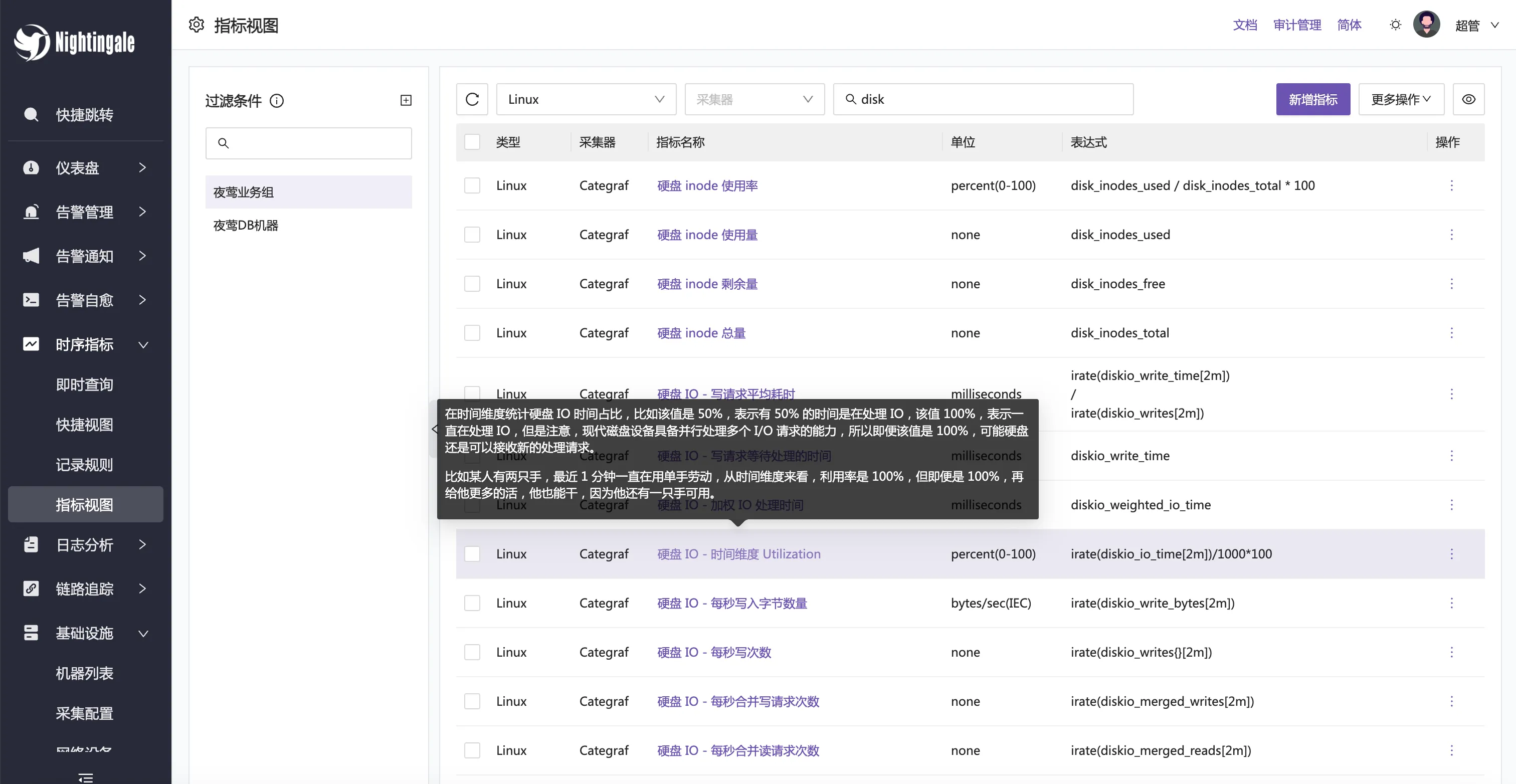
夜莺内置提供了指标视图,会在 v7 beta3 版本放出,会内置提供很多常用的 promql,点击查询即可,对小白用户会极为友好。
小结
已经有 Prometheus 了,为啥还需要夜莺(Nightingale)?本文算是对这个问题的一个探索性回复。希望对你有帮助,感谢大家的阅读。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库