
夜莺官方文档优化第一弹:手把手教你部署和架构讲解,消灭所有部署失败的 case!干!
前置说明
各种环境的选型建议
- Docker compose 方式:仅仅用于简单测试,不推荐在生产环境使用 Docker compose,升级起来挺麻烦的,除非你对 Docker compose 真的很熟
- 二进制部署:最推荐的方式,稳,升级也方便
- Helm 方式:公司大规模使用了 Kubernetes,可以选择 Helm 方式,前提是贵司对 Helm 这套真的很熟
- 存储选型:如果之前没有部署过,是个新环境,时序库选型建议使用 VictoriaMetrics,单机版 VictoriaMetrics 就可以抗住每秒上百万数据点,性能很好,CPU、内存的占用都比 Prometheus 少,而且,完全兼容 Prometheus 的查询接口
- 时间校准:社区反馈的很多问题都是因为机器时间没有校准,监控系统对时间很敏感,请各位先把机器时间校准一致,让服务端的机器、时序库的机器、要监控的目标机器、浏览器所在的 PC 时间,都保持一致
用户名密码
默认用户是 root,密码是 root.2020。
使用 Docker compose 快速体验
具体可以参考这个文档。不推荐使用,除非你对 Docker compose 真的很熟!
安装前置依赖
我们更推荐二进制的方式来部署,后文都是以二进制的方式来说明部署方式以及架构。夜莺依赖 mysql 存储用户配置类数据,依赖 redis 存储 jwt token 和机器心跳上报的 metadata,所以,先准备 mysql 和 redis。这俩组件请大家自行安装,这里也提供一个小脚本来安装这两个组件,大家可以参考:
# install mysql
yum -y install mariadb*
systemctl enable mariadb
systemctl restart mariadb
mysql -e "SET PASSWORD FOR 'root'@'localhost' = PASSWORD('1234');"
# install redis
yum install -y redis
systemctl enable redis
systemctl restart redis上例中 mysql 的 root 密码设置为了 1234,建议维持这个不变,后续就省去了修改配置文件的麻烦。如果你想修改默认用户名和密码,就要对应的修改配置文件中的 mysql 连接信息,配置文件的哪个地方配置了 mysql 的密码呢?通过下面的命令可以找到:
# 夜莺的主配置文件是 etc/config.toml
grep "1234" etc/config.toml安装夜莺
可以去 https://flashcat.cloud/download/nightingale/ 找最新版本的包,文档里的包地址可能已经不是最新的了
# 创建个 n9e 的目录,后面把 n9e 相关的文件解压到这里
mkdir -p /opt/n9e && cd /opt/n9e
# 下载 n9e 发布包,amd64 是 x84 的包,下载站点也提供 arm64 的包,如果需要其他平台的包则要自行编译了
tarball=n9e-v6.0.0-ga.7.0.2-linux-amd64.tar.gz
urlpath=https://download.flashcat.cloud/${tarball}
wget -q $urlpath || exit 1
# 解压缩发布包
tar zxvf ${tarball}
# 解压缩之后,可以看到 n9e.sql 是建表语句,导入数据库
mysql -uroot -p1234 < n9e.sql
# 启动 n9e,先使用 nohup 简单测试,如果需要 systemd 托管,请自行准备 service 文件
nohup ./n9e &> n9e.log &
# 检查 n9e.log 是否有异常日志,检查端口是否在监听,正常应该监听在 17000
ss -tlnp|grep 17000如果日志和端口都没啥问题,恭喜,你完成了夜莺的安装!通过浏览器访问这个机器的 17000,理论上就可以看到登录页面了。
玩法1:仅使用夜莺做告警管理
如果您之前已经部署了 Prometheus、Thanos、VictoriaMetrics、M3DB、Mimir 等某个时序库,只是想使用夜莺的告警管理功能,没问题,架构如下:
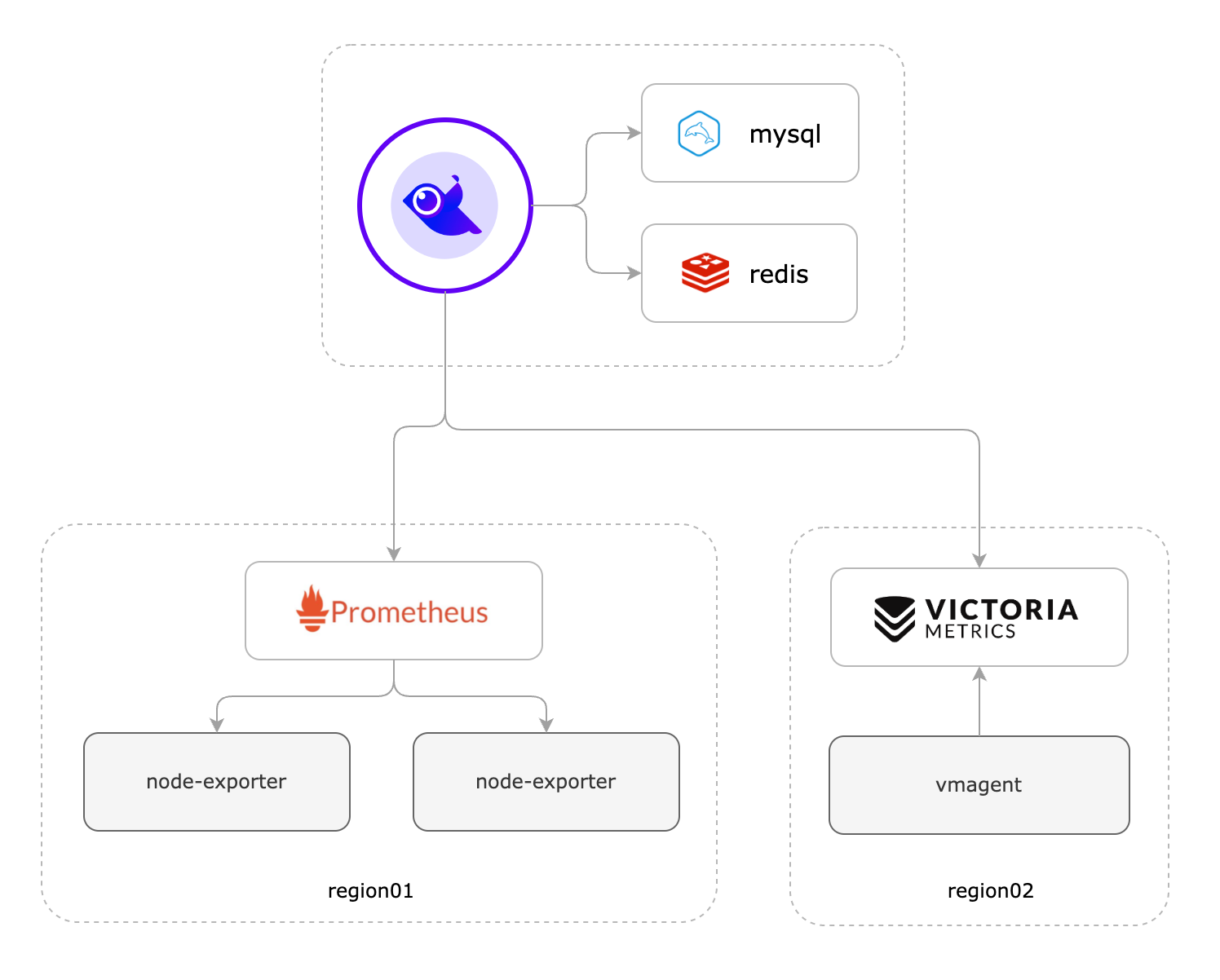
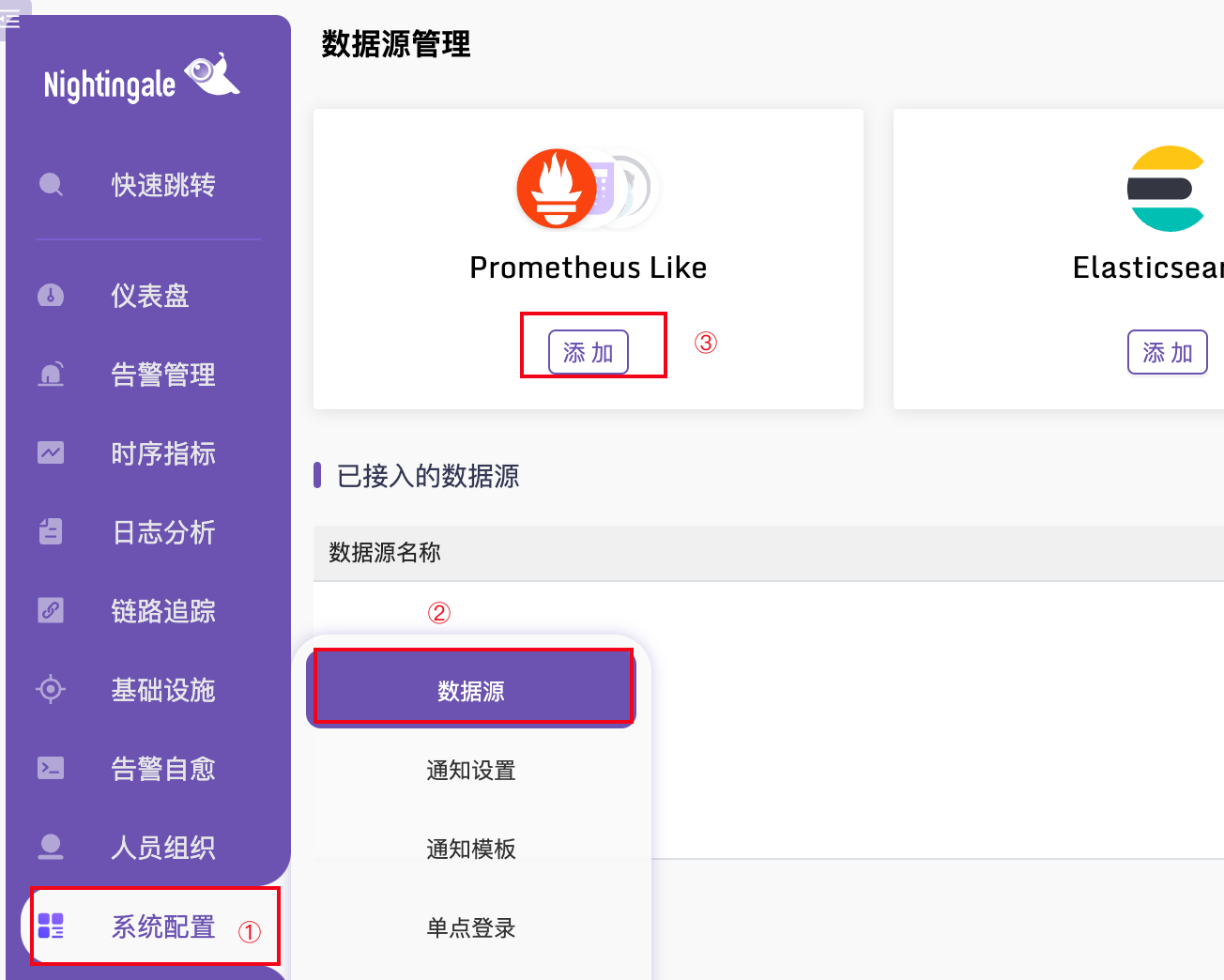
假设你之前有个 Prometheus,只需要把 Prometheus 作为数据源配置进来就可以了,入口在:
具体配置样例如下:
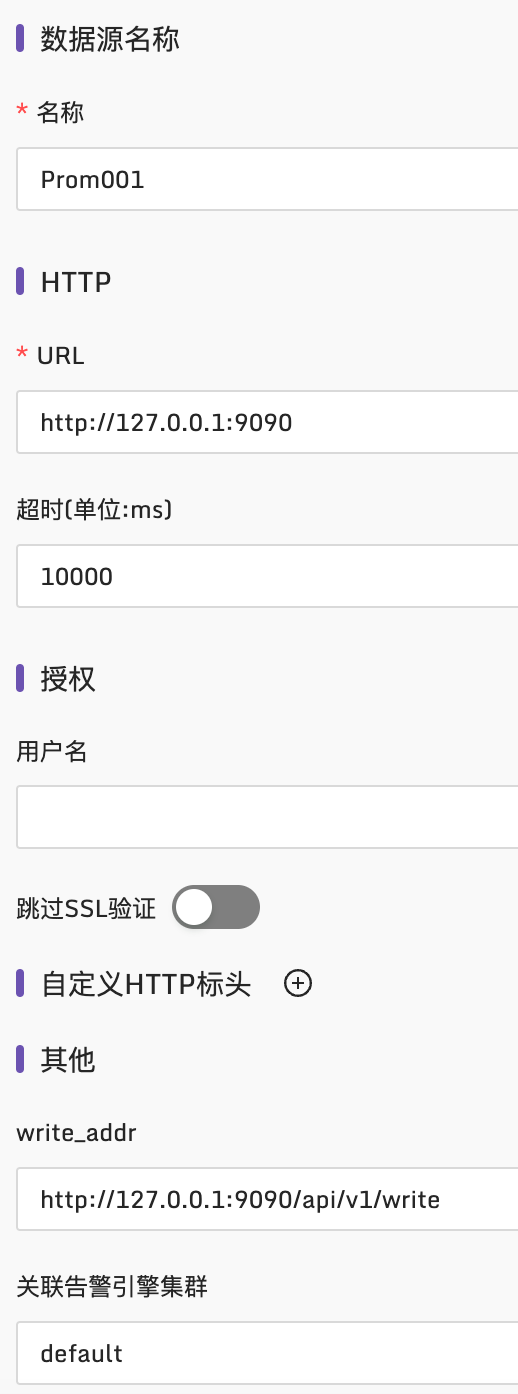
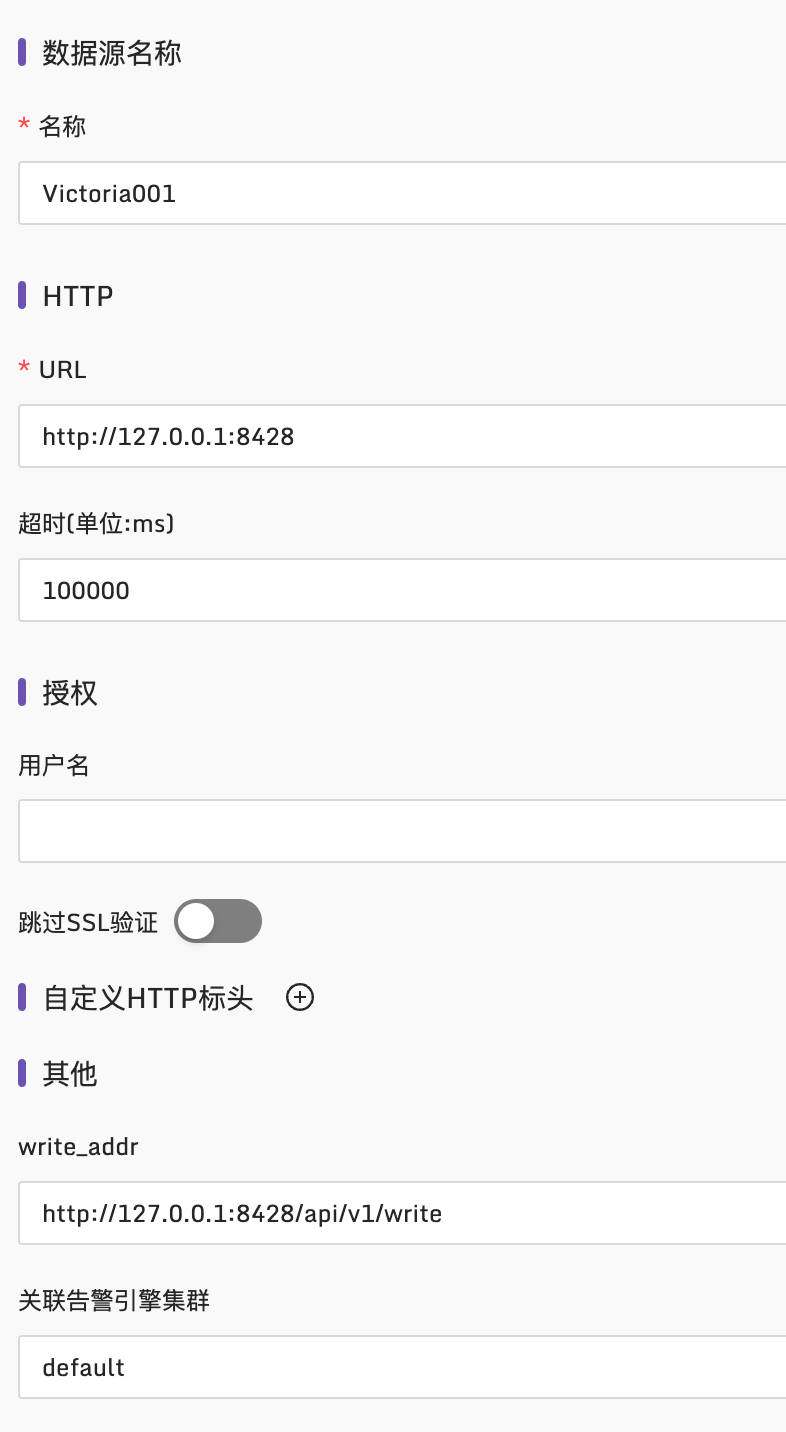
这里一些配置项的含义解释如下:
- 名称:随意取名,就是个标识,使用英文命名
- URL:Prometheus 的访问地址,如果是其他时序库,这个地址就不同喽,比如集群版本的 VictoriaMetrics,可能是类似这么个地址:
http://127.0.0.1:8481/select/0/prometheus - 超时时间:单位是毫秒,建议最小设置为10000,即10s,如果一些大的查询,就会比较耗时
- 授权:如果时序库启用了 Basic auth,这里就配置对应的 Basic auth username 和 password 即可
- 跳过 SSL 验证:如果证书不是正儿八经的证书想要跳过校验,就勾选这个项
- 自定义 HTTP 头:访问时序库的时候可以附加一些 HTTP Header
- write_addr:这个是时序库的 remote write 地址,我的例子中是 Prometheus,所以 url path 是
/api/v1/write,如果是其他时序库可能不同,比如集群版本的 VictoriaMetrics,remote write 地址可能是类似这个样子:http://127.0.0.1:8480/insert/0/prometheus/api/v1/write。这个信息用在哪里呢?平时都用不到,除非你在夜莺里使用了记录规则(recording rule),记录规则会生成新指标,新指标要回写时序库,所以要求时序库提供 remote write 地址。如果你不知道啥是 recording rule,可以 google 一下,google 关键字:“Prometheus recording rule”,或者跳过以后再说 - 关联告警引擎集群:这个说起来有点复杂了,选中默认的 default 即可,如果需要在边缘机房单独部署 n9e-alert 的时候,才需要详细了解这个信息
以上配置完成之后,我们去即时查询验证一下,看看能否查询到这个 Prometheus 的数据:
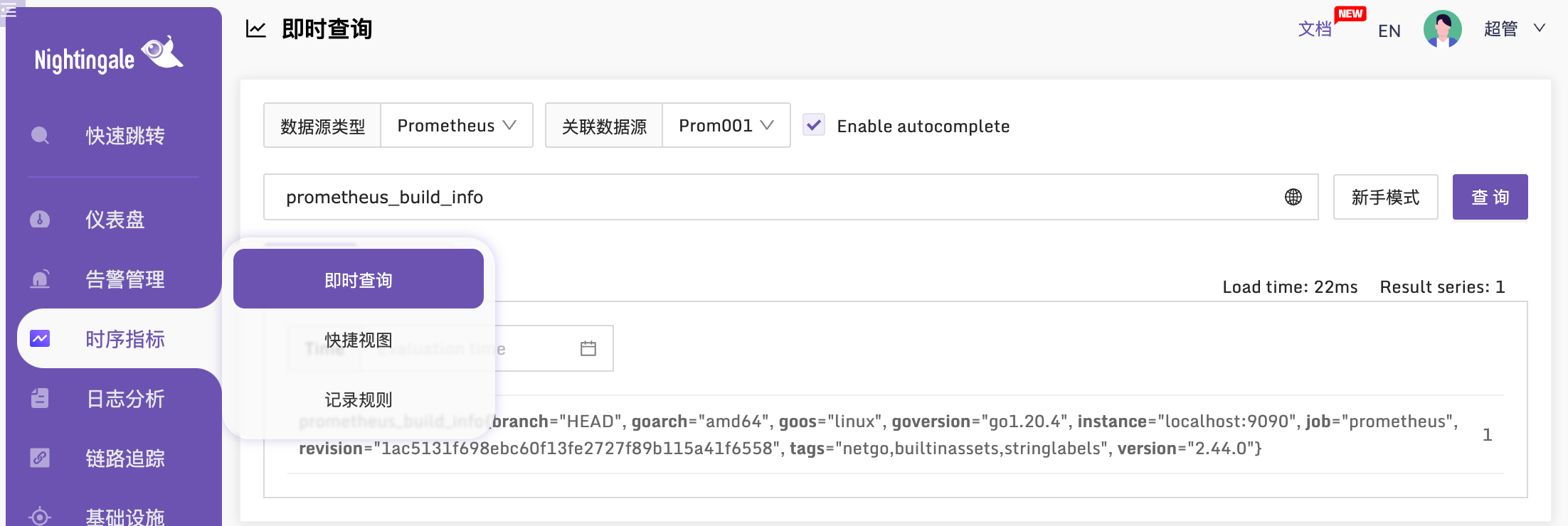
如上就表示正常的,如果有些数据确定时序库里是有的,但是在即时查询里查不到,有可能是时间没有校准,请自行检查时间。之后,就可以在夜莺里配置告警规则了,具体可以参考后续告警相关的文档。
玩法2:使用 categraf 采集数据,使用夜莺接收数据
社区里经常有小伙伴咨询,问夜莺可以监控xx么?
其实,夜莺啥都可以监控,又啥都监控不了。夜莺是一个服务端组件,类似 Grafana,可以接入不同的数据源,比如 Prometheus、VictoriaMetrics、Thanos 等等,只要数据进到这些库里了,夜莺就可以对数据源的数据进行分析、告警、可视化,以及后续的事件处理、告警自愈。
当然,夜莺也有端口接收监控数据,可以跟开源社区常见的各种监控采集器打通,比如 Telegraf、Categraf、Grafana-agent、Datadog-agent、Prometheus 生态的各类 Exporter 等等。这些 agent 采集了数据推给夜莺,夜莺适配了这些 agent 的数据传输协议,所以可以接收这些 agent 上报的监控数据,转存到后端对接的数据源,之后就可以对这些数据做告警分析、可视化。
所以夜莺本身不做监控数据采集,啥都不能监控,但是夜莺可以对接数据源,又啥都可以监控。
这一小节,我们介绍使用 Categraf 作采集器,然后推数据给夜莺,夜莺转存到时序库,并且后续对这些数据做可视化、告警等,整个架构如下图所示:
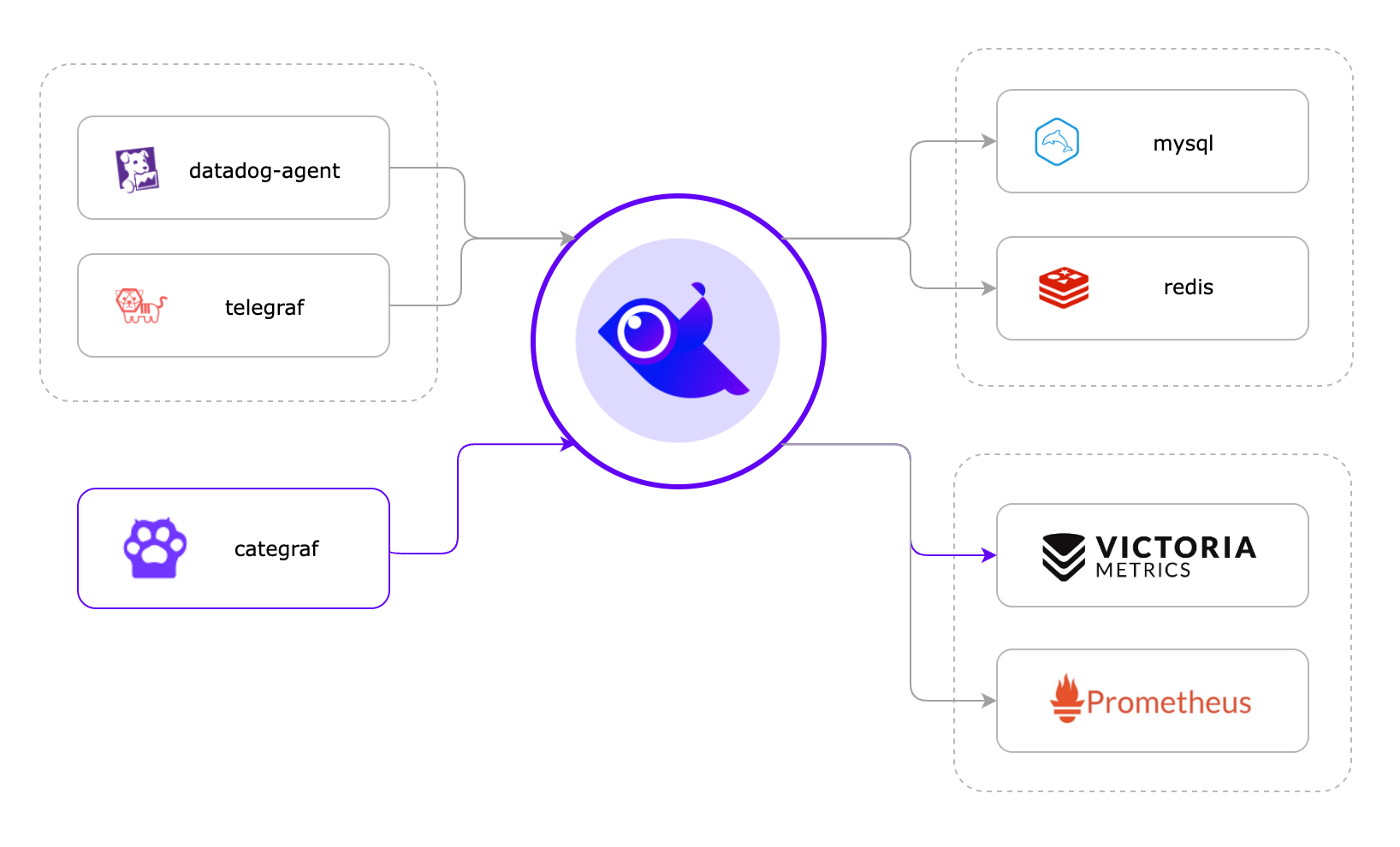
图上画了三个 agent:datadog-agent、telegraf、categraf,都可以和夜莺对接,我们推荐的是 categraf,所以本节主要以 categraf 举例。夜莺默认监听的端口是 17000,通过 api:/prometheus/v1/write 接收 remote write 协议的监控数据,categraf 恰好可以以 remote write 协议上报监控数据,所以二者可以对接,telegraf、grafana-agent 其实也可以以 remote write 协议上报监控数据,所以也可以和夜莺对接。
夜莺收到监控数据之后,夜莺自身不存储这些时序数据,直接转存到后端时序库,在这里,夜莺的角色只是一个 Pushgateway 的角色。我们推荐的时序库是单机版本的 VictoriaMetrics,后文就以此演示。当然了,夜莺可以同时并行转发数据给后端多个时序库,就像上图画的,把一份数据同时存储在 VictoriaMetrics 和 Prometheus,也是可以通过配置实现的。
安装单机版本的 VictoriaMetrics
如果选用集群版本的 VictoriaMetrics,可以参考 这里。当然,单机版本对绝大部分公司,够用了,配合云盘保障数据可靠性,稳。所以这里,我就演示单机版本的部署。
安装 VictoriaMetrics
VictoriaMetrics 下载地址在 github releases 上,作为技术人员,我想,你应该可以下载的到。我的环境是 x86_64 的 linux,所以选择下载:victoria-metrics-linux-amd64-v1.90.0.tar.gz (撰写这个文档的时候,最新版本是 v1.90.0)。
VictoriaMetrics 解压缩之后,里边就一个二进制:
[root@vm-159 tarball]# ll vic*
-rw-r--r--. 1 root root 10370599 5月 17 18:43 victoria-metrics-linux-amd64-v1.90.0.tar.gz
-rwxr-xr-x. 1 1000 1000 20191152 4月 7 09:00 victoria-metrics-prod启动它:
[root@vm-159 tarball]# nohup ./victoria-metrics-prod &> stdout.log &
[1] 12632
[root@vm-159 tarball]# ss -tlnp|grep 12632
LISTEN 0 128 *:8428 *:* users:(("victoria-metric",pid=12632,fd=10))通过上面的命令可以看出,单机版本的 VictoriaMetrics 监听在 8428 端口。通过浏览器访问 VictoriaMetrics 的 8428,理论上可以看到下面的页面:

如上,就表示 VictoriaMetrics 安装成功,当然,我仅仅使用 nohup 简单启动的,如果生产环境,建议使用 systemd 托管并设置开机自启动。
打通夜莺和 VictoriaMetrics
分两个步骤,首先就类似上面配置 Prometheus 数据源那种方式,在夜莺里配置一个 VictoriaMetrics 的数据源,比如我的配置:
其次,就需要修改配置文件了。打开夜莺的 etc/config.toml 配置,找到 HTTP.Pushgw 部分,默认配置如下:
[HTTP.Pushgw]
Enable = true
# [HTTP.Pushgw.BasicAuth]
# user001 = "ccc26da7b9aba533cbb263a36c07dcc5"这个表示:开启夜莺的监控数据接收类的 API,默认就是开启的,所以,默认配置就够了,不用动。那个 HTTP.Pushgw.BasicAuth 表示 BasicAuth(不懂啥是 BasicAuth 请自行 Google 哈) 的配置,如果是内网环境就维持注释就可以了,不用开启 BasicAuth,如果要把夜莺接收数据的接口暴露到公网,为了安全考虑,就需要 HTTPS + BasicAuth 双重保障了,这里的 HTTP.Pushgw.BasicAuth 相关的配置在公网环境下就应该打开,而且,应该修改这个 password:ccc26da7b9aba533cbb263a36c07dcc5,不要使用默认的 password。
另一个要修改的配置是 Pushgw.Writers 部分,把 VictoriaMetrics 的 remote write 地址配置上,我的环境的例子如下:
[Pushgw]
LabelRewrite = true
[[Pushgw.Writers]]
Url = "http://127.0.0.1:8428/api/v1/write"这里的 [[Pushgw.Writers]] 是双中括号扩起来的,这在 toml 配置中表示数组,如果你想把数据转发给后端多个时序库,就可以配置多个 [[Pushgw.Writers]],比如:
[Pushgw]
LabelRewrite = true
[[Pushgw.Writers]]
Url = "http://127.0.0.1:8428/api/v1/write"
[[Pushgw.Writers]]
Url = "http://127.0.0.1:9090/api/v1/write"OK,这样一来,夜莺接收到 categraf、telegraf、grafana-agent 等各类 agent 上报上来的监控数据,都会转发给后端的 VictoriaMetrics,完活。
部署 categraf 上报监控数据
Categraf 的安装请 参考文档,这个文档已经很详细了就不再赘述了。重点关注配置文件 config.toml,一个是 heartbeat 的配置:
[heartbeat]
enable = true
url = "http://127.0.0.1:17000/v1/n9e/heartbeat"这个配置是 Categraf 向夜莺心跳的地址,夜莺 v5 的话没有这个机制,需要把 Categraf heartbeat 的 enable 关掉。我这里演示的夜莺 v6,所以 heartbeat 的 enable 要设置为 true,建议大家用高版本的 Categraf,我这里用的是 v0.3.4。
另一个配置是 writers 部分:
[[writers]]
url = "http://127.0.0.1:17000/prometheus/v1/write"这表示:把数据推给夜莺的 17000 端口,url path 是 /prometheus/v1/write 这是夜莺的 remote write 协议的数据接收地址。
上面我的例子中,夜莺的地址都是:127.0.0.1:17000,因为我的 Categraf 和 夜莺 在一台机器上,如果你的 Categraf 和夜莺在不同的机器,注意改成合适的 IP。
按照 文档 中介绍的方法启动 Categraf,我这只是临时测试,所以,直接 nohup 启动得了:
nohup ./categraf &> categraf.log &验证结果
如果一切正常,Categraf 就会推数据给夜莺,夜莺转发给 VictoriaMetrics,而 VictoriaMetrics 又是夜莺的数据源,所以在夜莺的即时查询页面,理论上可以查询到 VictoriaMetrics 的数据,验证一下:
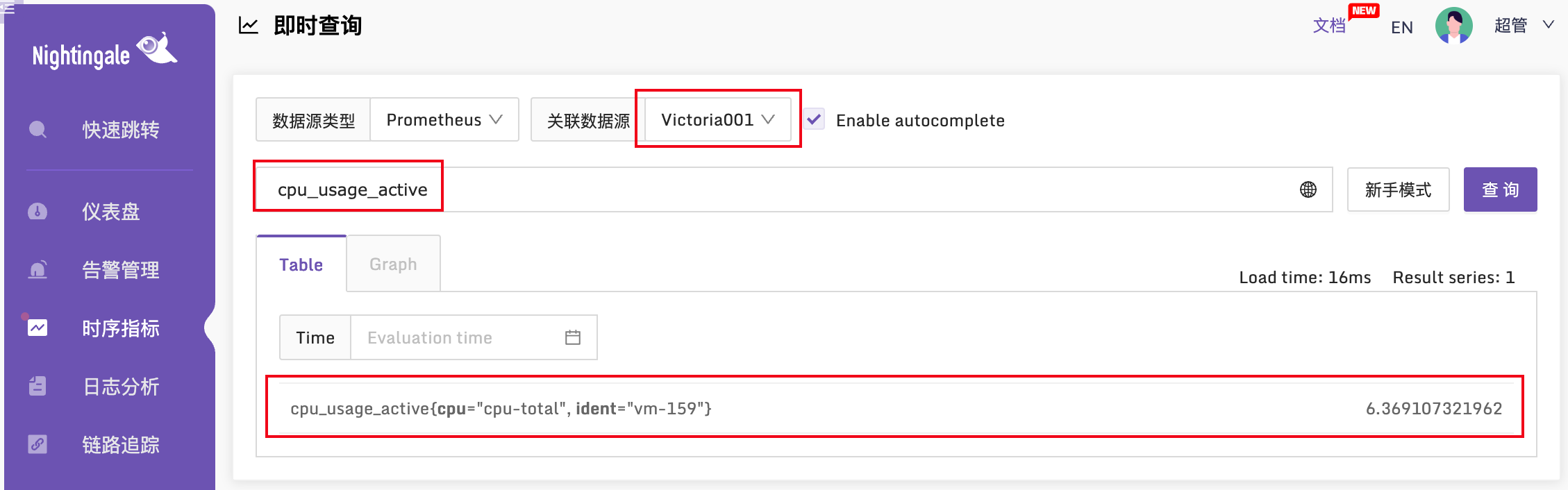
cpu_usage_active 这个指标就是 Categraf 采集上报的,看起来一切正常。欧耶!
夜莺高可用方案
这里服务端总共涉及到4个组件:时序库、mysql、redis、夜莺,其中时序库、mysql、redis 的高可用,大家 Google 一下网上大堆资料,这里不展开。关键是夜莺如何做高可用?
其实,很简单,多部署几个 n9e 实例就可以了。多个 n9e 实例会自动组成集群,分担压力。n9e 前面可以架设负载均衡,四层、七层都可以,某个 n9e 实例挂掉,负载均衡会自动剔除,用户通过浏览器访问夜莺的时候,访问负载均衡的地址,Categraf 的 writer 和 heartbeat 也配置成负载均衡的地址,就可以了。
如果夜莺里配置了3千条告警规则,部署了3个n9e实例,这三个n9e实例就会自动分配(通过一致性哈希算法)要处理的告警规则,确保每个n9e实例只处理大概1千条告警规则,分担告警引擎处理压力。如果某个n9e实例挂掉,其他实例会自动感知(利用mysql做了一些心跳机制)自动接管未被处理的告警规则,这也是把n9e集群化部署的好处。
高级玩法
如果,夜莺部署在北京机房,某些机房和北京机房网络链路较差,此时,应该把时序库、告警引擎下沉部署,具体应该如何做呢?看这里
转载自:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v6/install/intro/


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库