01--Java集合知识
一、Java集合概览
Java中集合分2大块,Collection和Map,分别代表不同功能的集合类对象,整体结构图如下:
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap

二、Colleciton
1. List特点及常用类
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法,查询速度快。因为往list集合里插入或删除数据时,会伴随着后面数据的移动,所有插入删除数据速度慢。
常用类有ArrayList、LinkedList、Vector(线程安全)、Stack(线程安全)。
1.1 ArrayList
ArrayList的内部实现为数组,因此,插入和删除操作效率较低(涉及到元素移位),但查询效率较高。示例代码如下:


package com.yyn.collectionandmap; import java.util.ArrayList; import java.util.Collection; import java.util.Collections; import java.util.Comparator; import java.util.LinkedList; public class ListTest { public static void testArrayList(){ System.out.println("####Begin ArrayList Test####"); ArrayList<String> list = new ArrayList<String>(); for(int i=0;i<10;i++){ list.add("a"+i%3); } list.add("a9"); System.out.println("Original: " + list); System.out.println("contains test:" + list.contains("a2")); list.remove("a3"); System.out.println("index of a9: " + list.indexOf("a9")); //对list排序,可用Colletions的静态方法 //list.sort(new MyComparator<String>()); Collections.sort(list, new MyComparator<String>()); System.out.println("After sort: " + list); System.out.println("####End ArrayList Test####"); } public static void testLinkedList(){ LinkedList<String> list = new LinkedList<String>(); } public static void main(String[] args) { // TODO Auto-generated method stub testArrayList(); } } class MyComparator<T> implements Comparator<T>{ public int compare(T o1, T o2) { // TODO Auto-generated method stub int result = o1.toString().compareTo(o2.toString()); if(result < 0) return -1; else if (result > 0) return 1; return 0; } }
1.2 LinkedList
LinkedList内部实现为双向链表,因此,插入和删除效率较高(只需改变前后节点关系),但查询效率较低,适用于改动多,但查询少的场景。
LInkedList的使用方法跟ArrayList类似。
2. Queue特点及常用类
。。。。。。
3. Set特点及常用类
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
Set的常用类有HashSet、TreeSet。
package com.yyn.collectionandmap; import java.util.*; public class ListTest { public static void testArrayList(){ System.out.println("####Begin ArrayList Test####"); ArrayList<String> list = new ArrayList<String>(); for(int i=0;i<10;i++){ list.add("a"+i%3); } list.add("a9"); System.out.println("Original: " + list); System.out.println("contains test:" + list.contains("a2")); list.remove("a3"); System.out.println("index of a9: " + list.indexOf("a9")); //对list排序,可用Colletions的静态方法 //list.sort(new MyComparator<String>()); Collections.sort(list, new MyComparator<String>()); System.out.println("After sort: " + list); System.out.println("####End ArrayList Test####"); } public static void testLinkedList(){ LinkedList<String> list = new LinkedList<String>(); } public static void testHashSet(){ //创建一个线程同步的HashSet对象 //Set<String> set = Collections.synchronizedSet(new HashSet<String>()); Set<String> set = new HashSet<String>(); set.add("xxx"); set.add("yyy"); System.out.println(set); set.add("xxx"); System.out.println(set); //若需要对HashSet排序,直接新建一个TreeSet即可,效率较高 TreeSet<String> treeSet = new TreeSet<String>(set); System.out.println(treeSet); } public static void main(String[] args) { // TODO Auto-generated method stub //testArrayList(); testHashSet(); } } class MyComparator<T> implements Comparator<T>{ public int compare(T o1, T o2) { // TODO Auto-generated method stub int result = o1.toString().compareTo(o2.toString()); if(result < 0) return -1; else if (result > 0) return 1; return 0; } }
3.1 HashSet
HashSet中的对象是无序的,若需要进行排序,直接利用HashSet创建TreeSet即可。
3.2 TreeSet
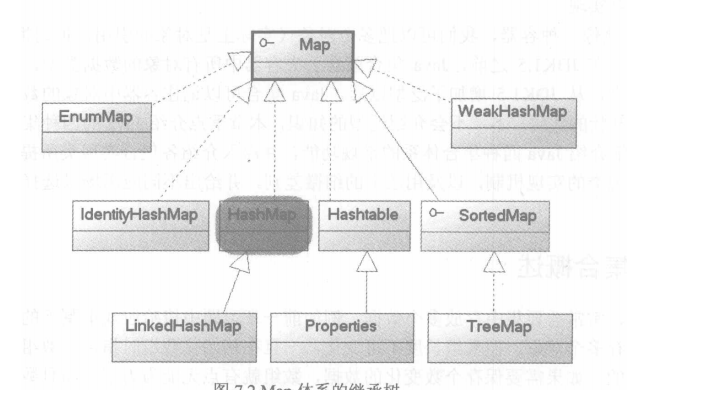
三. Map
“集合框架”提供两种常规的 Map 实现:HashMap 和TreeMap。和所有的具体实现一样,使用哪种实现取决于您的特定需要。在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按顺序遍历键,那么TreeMap 会更好。根据集合大小,先把元素添加到 HashMap,再把这种映射转换成一个用于有序键遍历的 TreeMap 可能更快。
实现类:HashMap、Hashtable、LinkedHashMap和TreeMap
1.HashMap
HashMap是最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的
2.Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
3.ConcurrentHashMap
线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
4.LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
5.TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,非同步的;
四、主要实现类区别小结
1.Vector和ArrayList
1,vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
2,如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%。如果在集合中使用数据量比较大的数据,用vector有一定的优势。
3,如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,如果频繁的访问数据,这个时候使用vector和arraylist都可以。而如果移动一个指定位置会导致后面的元素都发生移动,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据时其它元素不移动。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
2.arraylist和linkedlist
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
3.HashMap与TreeMap
1、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
2、在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
两个map中的元素一样,但顺序不一样,导致hashCode()不一样。
同样做测试:
在HashMap中,同样的值的map,顺序不同,equals时,false;
而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。
4.HashTable与HashMap
1、同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
2、HashMap允许存在一个为null的key,多个为null的value 。
3、hashtable的key和value都不允许为null。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号