01--Java开发中文乱码问题分析
一、常见的编码格式
1. ASCII码
总共128个字符,用1个字节的低7位表示,0~31是控制字符,32~126是打印字符。
2. ISO-8859-1
ISO组织在ASCII基础上进行扩展,仍是单字节编码,支持256个字符,支持大部分西欧字符。
3. GB2312 GBK GB18030
GB2312可用GBK方式解码,不会有问题。GB18030使用不多。
4. UTF-16
UTF-16定义了Unicode在计算机中的存取方法,采用2个字节存储。
5. UTF-8
UTF-16采用2个字节存储一个字符,很方便,但浪费空间,因为大部分字符用一个字节表示(英文)。
因此UTF-8采取了变长方式,根据字符不同,分别可存储1、2、3个字节。
二、Java中需要编码的场景
1. I/O操作
在Java中的文件和网络通讯过程中,都涉及到编码的场景。
2. 内存操作中的编码和解码
2.1 String类提供编码和解码功能
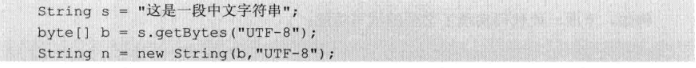
2.2 Charset类提供编码和解码功能

三、Web中设计编码的场景
1. 基础知识
对于URL、URI、QueryString、HTTP结构、meta标签知识,可参考之前的文章:http://www.cnblogs.com/ulli/p/6340673.html
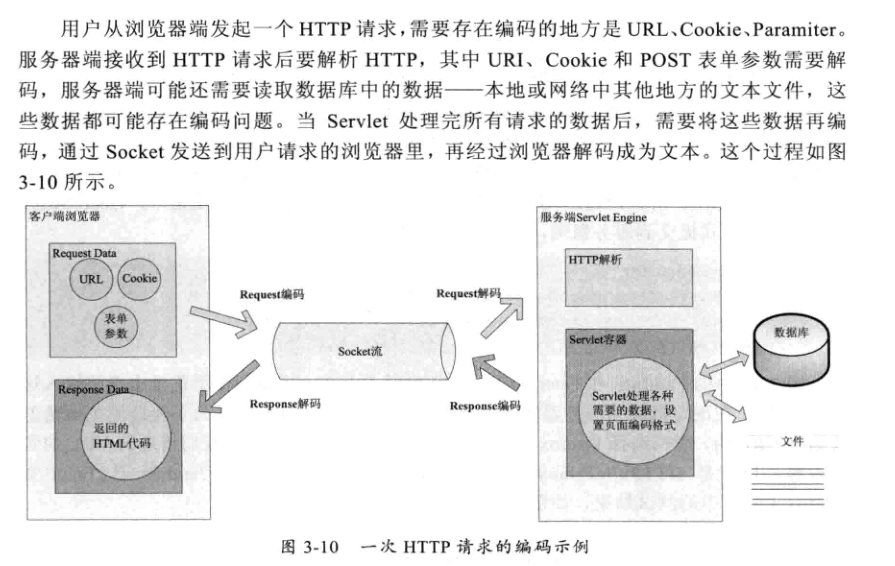
2. 编码规则
2.1 URL方式,例如,直接将地址复制到浏览器中。跟GET方式有区别,使用浏览器默认的编码集(一般为UTF-8或GBK)提交数据。
- PathInfo部分的编码与浏览器有关,一般Firefox和IE为GBK,因此,PathInfo中尽量不要包含中文。
- QueryString部分的编码也与浏览器相关,不同浏览器会用不同的编码方式,因此处理起来非常麻烦。但有时必须要处理中文,例如搜索引擎,因此常规做法是利用javascrip的encodeURI方法对url地址进行编码,该函数会利用UTF-8的方式对url进行编码,可避免浏览器编码方式不一致造成的乱码问题。

2.2 GET方式,会先使用meta标签中提供的Charset进行编码,若未指定,则使用默认ISO-8890-1编码
GET方式也会将请求数据放入到URL中的QueryString区域,根据前一个页面提供的编码集类型,对提交数据进行编码,然后提交到下一个页面。一般也是利用js对url进行拼接、编码后传至服务器。
比如,在login.html页面中进行输入,提交到process.jsp中,此时,编码的规则是根据login.html中meta标签指定的(如GBK、UTF-8等),而不是process.jsp中的编码集。
2.3 POST方式
POST方式会将请求数据放到http body区域,并根据前一个页面的meta标签提供的charset进行编码(),然后加密。
在服务器端,一般用request.setCharacterEncoding方法可设置编码,注意,一定要在request.getParameters方法前调用。
编码过程与GET方式类似,只是数据存储在http body区域。
注意:


2.4 HTTP Header的编解码
Cookie、RedirectPath等都是在header中进行传输的,Tomcat对Header的解码是在request.getHeader时进行的,且我们也不能设置其他的编码格式,只能是默认的ISO-8859-1。因此,若请求头中包含非ASCII字符,解码肯定会乱码。
同理,向header中写数据时,不要传递非ASCII字符,若需要,可先用org.apach.catalina.util.URLEncoder编码,再写入header,这样从浏览器到服务器之间的传递过程就不会丢失信息了,后续需要使用时,按照相应的字符集解码即可获取正确信息了。
四、常见乱码原因分析及解决方案
1. QueryString出现乱码
原因分析:
原因1. 各浏览器提交QueryString时编码格式不一致。
原因2. 服务器端未设置使用相应的编码集进行解码。
解决方案:
1. 对于原因1,一般在前端利用js的encodeURL函数对url进行编码,使用的是UTF-8格式。
2. 对于Tomcat7,需设置server.xml文件中的Connector节点,设置如下2个属性

并在第一次调用request.getParameters方法前,先调用request.setCharacterEncoding方法设置字符集。
之所以为tomcat7设置useBodyEncodingForURI,因为getParameters会调用parseParameters方法,请看如下代码:
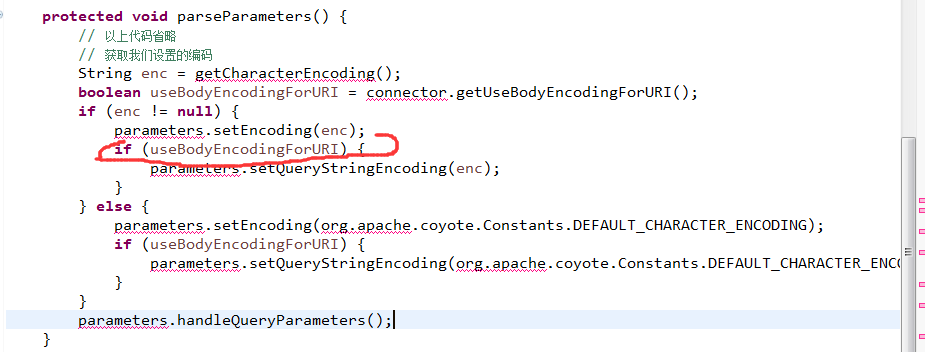
若未设置useBodyEncodingForURI的话,则只会给parameters赋值enc,而不会给QueryString赋值enc。
在解析参数时,对于 Post 请求,Tomcat 使用 encoding 来解码;对于 get 请求,Tomcat 使用 queryStringEncoding 来解析参数,因为此时 useBodyEncodingForURI 为 false 时,Tomcat 使用默认码 来解析,Tomcat 7的默认编码是 ISO-8859-1,所以解析之后参数出现乱码;Tomcat 8 默认编码是 UTF-8,因此解析不会出现乱码。

2. GET方式出现乱码
原因分析
GET方式提交时,会根据当前页面的response header中的Content-Type设定的字符集对数据进行编码,html的head代码如下:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
然后提交至目标页面。举个栗子,以get方式从login.html提交name和age到home.jsp,会利用login.html中meta域设定的编码集进行编码,然后将数据发送至home.jsp页面。
解决方案
有2中解决方案:
1. 设置数据提交页的response header中content-type,告诉浏览器编码时采用何种字符集。例如上面的login.html页面。
2. 提交数据前,用js拼接url地址在,然后调用encodeURL函数对url地址进行编码(UTF-8),然后提交服务器,服务器进行相应的解码即可。
3. POST方式出现乱码
原因分析:
数据提交时编码规则跟get相同,只是数据放在http body中。
解决方案
设置数据提交页的response header中content-type,告诉浏览器编码时采用何种字符集。例如上面的login.html页面,然后服务器进行相应解码。
参考文章:
关于URL编码:http://www.ruanyifeng.com/blog/2010/02/url_encoding.html
http://www.ruanyifeng.com/blog/2010/02/url_encoding.html
根据Tomcat源码分析QueryString有中文时该如何配置:http://www.infocool.net/kb/Tomcat/201607/169187.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号