这应该是全网最全的CSP-S初赛复习吧
Update 2024/8/2: 加入了在数据结构中增加了“树”,做出部分更改。
Update 2024/8/19:感谢 @daitangchen2008 指出。更改部分错误。
Update 2024/9/20:rp++,更改负数取模错误部分以及树的遍历。
Update 2025/3/15:大幅度调整,修改大量 \(\LaTeX\) 错误。重新编辑排版。
1 linux基础命令
| cd | 切换目录 |
|---|---|
ls |
列出目前工作目录所含的文件及子目录。 |
pwd |
显示目前的目录。 |
mkdir |
创建文件夹。 |
rmdir |
删除空文件夹。 |
touch |
创建空白文件。 |
cp |
复制文件或者目录。 |
rm |
删除文件或者目录。 |
mv |
移动文件或者目录。 |
file |
查看文件类型。 |
man |
查看各个命令的使用文档。 |
2 Linux time指令
2.1 time 的简单用法
查看命令用时:
[roc@roclinux ~]$ time ls
program public_html repo rocscm
real 0m0.002s
user 0m0.002s
sys 0m0.000s
-
real:从进程 ls 开始执行到完成所耗费的 CPU 总时间。 -
user:进程 ls 执行用户态代码所耗费的 CPU 时间。 -
sys:进程 ls 在内核态运行所耗费的 CPU 时间。
命令的真正执行时间:\(user_{time}+sys_{time}\) 的时间。
一般情况:\(real_{time}=user_{time}+sys_{time}\),所以我们可以使用 \(real_{time}\) 作为执行时间。
2.2 time指令深入
情景一:
[roc@roclinux ~]$ time sudo find / -name php.ini
real 0m0.193s
user 0m0.076s
sys 0m0.115s
- 不一定 \(real_{time}=user_{time}+sys_{time}\)。
证明:
\(\because \ real_{time}\) 是包含了其他进程的执行时间和进程阻塞时间的,而 \(usr_{time}+sys_{time}\) 不包括其他进程的执行时间和进程阻塞时间的。
\(\therefore \ real_{time} > user_{time}+sys_{time}\) 是非常有可能的。
- 不一定 \(real_{time}>user_{time}+sys_{time}\)。
证明:
\(\because\) 多核CPU可以处理多项事务。
\(\therefore\) 完成工作总花费时间为:\(user_{time}+sys_{time}\)。
存在两种情况:
- \(real_{time}=user_{time}+sys_{time}\)
- \(real_{time}<user_{time}+sys_{time}\)
\(\therefore\) 单核 CPU 中关系式成立,多核 CPU 中关系式不成立。
- 不一定 \(real_{time}<user_{time}+sys_{time}\)。
单核 CPU 中关系不成立。
情景二:
第一次执行:
[roc@roclinux ~]$ time sudo find / -name mysql.sh
/etc/profile.d/mysql.sh
real 0m6.776s
user 0m1.101s
sys 0m1.363s
第二次执行:
[roc@roclinux ~]$ time sudo find / -name mysql.sh
/etc/profile.d/mysql.sh
real 0m3.059s
user 0m1.189s
sys 0m1.435s
原因:对于运行时间较短的任务计时时,会产生一定误差。time 命令输出的时间统计精度基本在 \(10\) 毫秒级。
3 GCC编译选项
| 指令 | 含义 |
|---|---|
-c |
编译源代码,但不进行链接操作,生成目标文件。 |
-o |
指定输出文件名。例如,-o myprogram 表示将输出文件命名为 myprogram。 |
-g |
生成调试信息。这意味着编译器将在目标文件中包含调试信息,可以用于调试程序。 |
-O |
指定优化级别。例如,-O2 表示使用较高的优化级别。 |
-Wall |
生成所有警告信息。这意味着编译器将生成所有警告信息,帮助开发者检查代码。 |
-std= |
指定使用的 C/C++ 标准。例如,-std=c++11 表示使用 C++11 标准。 |
-I |
指定编译时搜索的头文件目录。 |
-D |
定义宏。例如,-DDEBUG 表示定义宏 DEBUG。 |
-U |
取消定义宏。例如,-UDEBUG 表示取消定义宏 DEBUG。 |
-E |
只进行预处理操作,不进行编译和链接操作。 |
-Werror |
将所有警告信息视为错误信息。这意味着编译器将在生成警告信息时停止编译操作。 |
4 进制转换
4.1 进制数初步认识
- 十进制: 都是以 \(0-9\) 这九个数字组成,不能以 \(0\) 开头。
- 二进制: 由 \(0\) 和 \(1\) 两个数字组成。例如 \((10110)_{2}\)。
- 八进制: 由 \(0-7\) 数字组成,例如 \((57)_{8}\)。
- 十六进制:由 \(0-9\) 和 \(A-F\)(可以为小写) 组成。例如 \((7F)_{16}\)。
4.2 十进制转 X 进制:
-
4.2.1 整数转换
-
将需要转换的数 \(a\) 除以 \(x\),取余 \(a \bmod x\),余数为所求进制数,从下往上取
-
所得整数部分保留,重复步骤 \(1\),直到商为 \(0\)。
例如:\(9_{(10)}\to1001_{(2)}\)
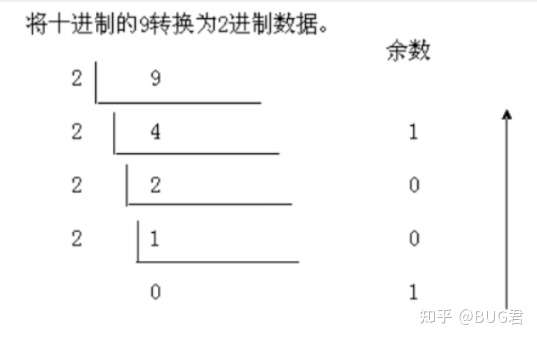
-
4.2.2 小数转化
十进制转二进制:
原理:十进制小数转换成二进制小数采用 “乘2取整,顺序输出” 法。
例如:十进制小数 \(0.68\) 转换为二进制数。
具体步骤:\[0.68\times 2=1.36\to1 \\ 0.36\times 2=0.72 \to0 \\ 0.72\times2=1.44 \to1 \\ 0.44\times2=0.88\to0 \\ 0.88\times2=1.76\to1 \\ \]已经达到了题目要求的精度,最后将取出的整数部分顺序输出即可。
则为:\((0.68)_{10} \to (0.10101)_2\)
其他进制思路一样,小数与整数结合的,两种方法直接一起套用
4.3 X 进制转换为十进制

小数部分:小数部分从小数点后一位指数 \(-1\) 为开始算起,以后依次为 \(-2\)、\(-3\),以此类推。
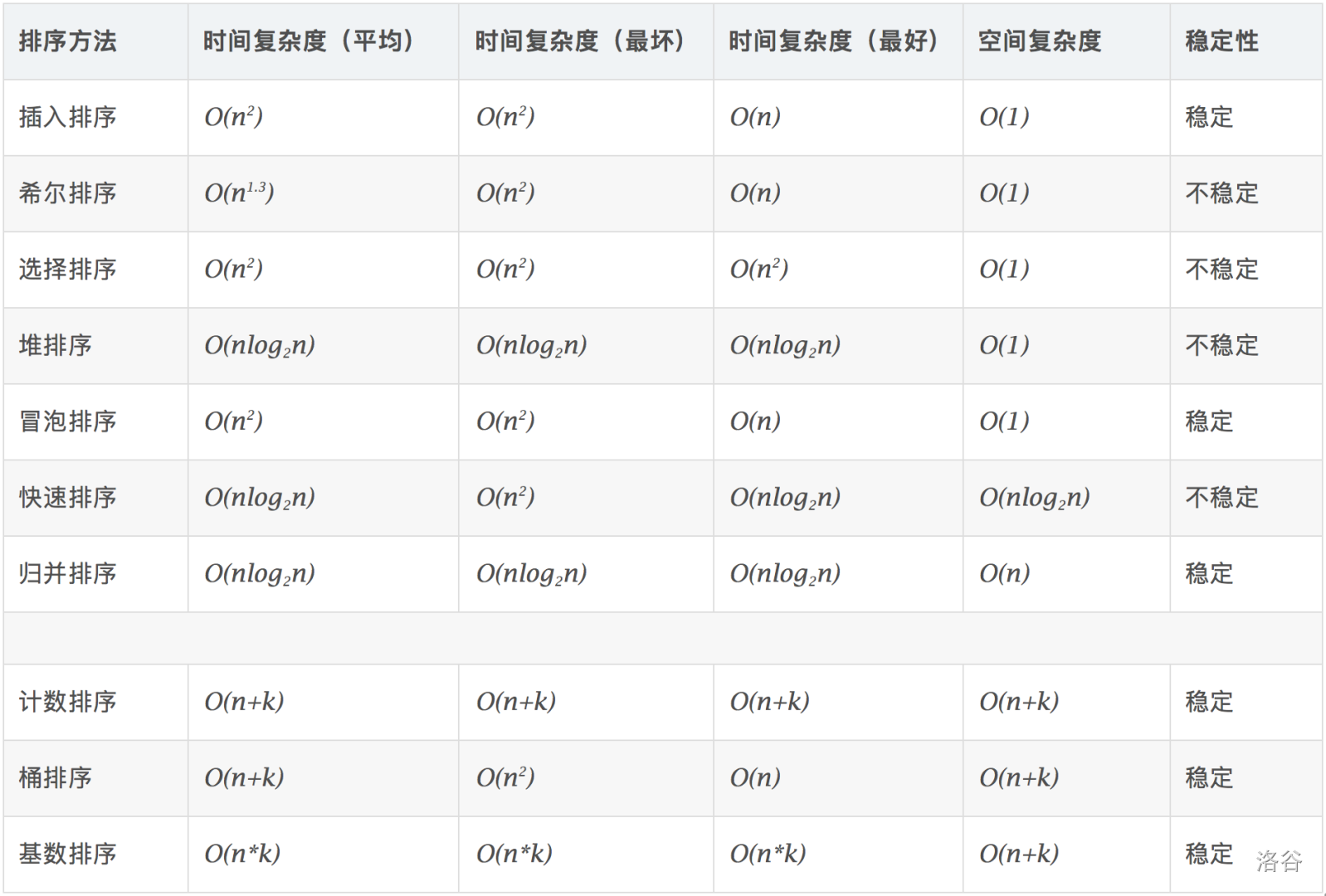
5 排序算法
6 原码、补码、反码、计算
6.1 机器数和真值
6.1.1 机器数
一个数在计算机中的二进制表示形式, 叫做这个数的机器数。机器数是带符号的,在计算机用一个数的最高位存放符号, 正数为 \(0\), 负数为 \(1\)。
比如,十进制中的数 \(+3\),计算机字长为 \(8\) 位,转换成二进制就是 \((00000011)_2\)。如果是 \(-3\) ,就是 \((10000011)_2\) 。
那么,这里的 \((00000011)_2\) 和 \((10000011)_2\) 就是机器数。
6.1.2 真值
因为第一位是符号位,所以机器数的形式值就不等于真正的数值。例如上面的有符号数 \((10000011)_2\),其最高位 \(1\) 代表负,其真正数值是 \(-3\) 而不是形式值 \(131\)(\((10000011)_2\)转换成十进制等于 \(131\))。所以,为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
例:$$(00000001)_2 = (+0000001)2 = (+1) \(10000001)_2 = (–0000001)2 = (–1)$$
6.2 原码, 反码, 补码的基础概念和计算方法
6.2.1 原码
原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值。比如如果是 \(8\) 位二进制:
第一位是符号位。因为第一位是符号位,所以 \(8\) 位二进制数的取值范围就是:
\(11111111 \Rightarrow 01111111\)
即
\(-127 \Rightarrow 127\)
原码是人脑最容易理解和计算的表示方式。
6.2.2 反码
反码的表示方法是:
正数的反码是其本身
负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
可见如果一个反码表示的是负数, 人脑无法直观的看出来它的数值。通常要将其转换成原码再计算。
6.2.3 补码
补码的表示方法是:
正数的补码就是其本身
负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后 \(+1\)。(即在反码的基础上 \(+1\)。)
对于负数, 补码表示方式也是人脑无法直观看出其数值的。通常也需要转换成原码在计算其数值。
7 同余
7.1 同余的概念
两个整数 \(a\),\(b\),若它们除以整数 \(m\) 所得的余数相等,则称 \(a\),\(b\) 对于模 \(m\) 同余。
记作 \(a \equiv b \pmod m\)
读作: \(a\) 与 \(b\) 关于模 \(m\) 同余。
举例说明:
所以 \(4, 16, 28\) 关于模 \(12\) 同余。
7.2 负数取模
可参考 C99 标准:
取模运算结果的正负是由左操作数的正负决定的。如果 % 左操作数是正数,那么取模运算的结果是非负数;如果 % 左操作数是负数,那么取模运算的结果是负数或0。
代码实践:
#include <iostream>
using namespace std;
int main()
{
cout << 5 % 2 << endl;
cout << 5 % -2 << endl;
cout << -5 % 2 << endl;
cout << -5 % -2 << endl;
return 0;
}
输出结果:
1
1
-1
-1
8 运算符
按位与 &
参加运算的两个数,换算为二进制后,进行与运算。只有当相应位上的数都是 \(1\) 时,该位才取 \(1\),否则该位为 \(0\)。
按位或 |
参加运算的两个数,换算为二进制后,进行或运算。只要相应位上存在 \(1\),那么该位就取 \(1\),均不为 \(1\),即为 \(0\)。
按位异或 ^
参加运算的两个数,换算为二进制后,进行异或运算。只有当相应位上的数字不相同时,该为才取 \(1\),若相同,即为 \(0\)。
任何数与 \(0\) 异或,结果都是其本身。
异或还可以交换两个数
a = a ^ b;
b = b ^ a;
a = a ^ b;
取反 ~
参加运算的两个数,换算为二进制后,进行取反运算。每个位上都取相反值,\(1\) 变成 \(0\),\(0\) 变成 \(1\)。
左移 <<
右移 >>
9 大端与小端模式
前置知识:读数据永远是从低地址开始的。
9.1 低地址、高地址
地址编号小的是低地址,地址编号大的是高地址。

9.2 数据的低位、高位

9.3 小端模式
小端模式:数据的 低位 放在 低地址 空间,数据的 高位 放在 高地址 空间。
简记:小端就是低位对应低地址,高位对应高地址。
存放二进制数:\(1011-0100-1111-0110-1000-1100-0001-0101\)。
注意:我们在存放的时候是以一个存储单元为单位来存放,存储单元内部不需要再转变顺序。
就例如下面的低位 \(0001-0101\) 存放在 \(0\) 号地址,我们不需要把它变成 \(1010-1000\)。

读取数据:注意一定一定是从低地址读起。我们知道这是小端存储,所以在读出来的时候会从低位开始放。

存放十六进制数:\((2AB93584FE1)_{16}\)
十六进制数每一位转化为二进制就是 \(4\) 位:\(2\) 对应 \(0010\),\(A\) 对应 \(1010\),以此类推。所以在存放的时候两个十六进制位就占用一个存储单元。

9.4 大端模式
数据的 高位 放在 低地址 空间,数据的 低位 放在 高地址空间。
存放二进制数:\(1011-0100-1111-0110-1000-1100-0001-0101\)


读取数据:注意仍然是从低地址开始读,我们知道这是大端模式,当我们从 \(0\) 号地址读到 \(1011-0100\) 时,我们知道它是高位,所以放到高位的位置上去。
存放十六进制数:\((2AB93584FE1C)_{16}\)。


读取数据:注意从低地址开始读取,读到的从高地址开始放。
10 数据结构
10.1 基础数据结构
-
10.1.1 队列
是一种“先进先出”的线性数据结构,元素从右端进入队列(入队),从左端离开队列(出队),称队列的左端为队头,右端为队尾。
-
10.1.2 链表
链表每个元素都是一个对象,每个对象按线性顺序排列。
双向链表: 每个元素都是一个对象,每个对象有关键字 \(key\) 和两个指针:\(prev\) 和 \(next\)。 假设 \(x\) 为链表的一个元素,\(x.next\) 指向链表中的后继元素,\(x.prev\) 指向它在链表的前面元素,如果 \(x.prev=NULL\),则 \(x\) 是链表中的第一个元素(链表的头),\(x.next=NULL\),则 \(x\) 是链表中的最后一个元素(链表的尾),属性 \(L.head\) 指向链表的第一个元素,如果 \(L.head=NULL\),则链表为空。
单向链表: 则省略每个元素的 \(prev\) 指针。
循环链表: 是表头元素的 \(prev\) 指针执行表尾元素,表尾元素的 \(next\) 指针指向表头元素。
-
栈
是一种“先进后出”的线性数据结构。栈只有一端能够进出元素,称这一端为栈顶,另一端为栈底。添加或删除栈中元素时,我们只能将其插入到栈顶(进栈),或者把栈顶元素从栈中取出(出栈)。
-
图
图是一个二元组 \(G=(V(G), E(G))\)。其中 \(V(G)\) 是非空集,称为 点集,对于 \(V\) 中的每个元素,我们称其为 顶点 或 节点,简称 点;\(E(G)\) 为 \(V(G)\) 各结点之间边的集合,称为 边集。
常用 \(G=(V,E)\) 表示图。
图分为有权图与无权图,有向图与无向图:
-
有权图对于每一个边集都有一个权值,而无权图则没有。
-
有向图对于每一个边集 \((x,y)\),都会有 \(x\) 指向 \(y\) 或 \(y\) 指向 \(x\) ,无向图没有。
对于简单图的概念,如下:
自环:对 \(E\) 中的边 \(e = (u, v)\),若 \(u = v\),则 \(e\) 被称作一个自环。
重边:若 \(E\) 中存在两个完全相同的元素(边)\(x,y\),则它们被称作(一组)重边。
简单图:若一个图中没有自环和重边,它被称为简单图。具有至少两个顶点的简单无向图中一定存在度相同的结点。
-
-
树
定义
一个没有固定根结点的树称为 无根树。无根树有几种等价的形式化定义:
-
有 \(n\) 个结点,\(n-1\) 条边的连通无向图。
-
无向无环的连通图。
-
任意两个结点之间有且仅有一条简单路径的无向图。
-
任何边均为桥的连通图。
-
没有圈,且在任意不同两点间添加一条边之后所得图含唯一的一个圈的图。
在无根树的基础上,指定一个结点称为 根,则形成一棵 有根树。有根树在很多时候仍以无向图表示,只是规定了结点之间的上下级关系,详见下文。。
有关树的定义
适用于无根树和有根树
-
森林:每个连通分量(连通块)都是树的图。按照定义,一棵树也是森林。
-
生成树:一个连通无向图的生成子图,同时要求是树。也即在图的边集中选择 \(n - 1\) 条,将所有顶点连通。
-
无根树的叶结点:度数不超过 \(1\) 的结点。
-
有根树的叶结点:没有子结点的结点。
只适用于有根树
-
父亲:对于除根以外的每个结点,定义为从该结点到根路径上的第二个结点。
根结点没有父结点。 -
祖先:一个结点到根结点的路径上,除了它本身外的结点。
根结点的祖先集合为空。 -
子结点:如果 \(u\) 是 \(v\) 的父亲,那么 \(v\) 是 \(u\) 的子结点。
子结点的顺序一般不加以区分,二叉树是一个例外。 -
结点的深度:到根结点的路径上的边数。
-
树的高度:所有结点的深度的最大值。
-
兄弟:同一个父亲的多个子结点互为兄弟。
-
后代:子结点和子结点的后代。
或者理解成:如果 \(u\) 是 \(v\) 的祖先,那么 \(v\) 是 \(u\) 的后代。

- 子树:删掉与父亲相连的边后,该结点所在的子图。

特殊的树
-
链:满足与任一结点相连的边不超过 \(2\) 条的树称为链。
-
菊花/星星:满足存在 \(u\) 使得所有除 \(u\) 以外结点均与 \(u\) 相连的树称为菊花。
-
有根二叉树:每个结点最多只有两个儿子(子结点)的有根树称为二叉树。常常对两个子结点的顺序加以区分,分别称之为左子结点和右子结点。
大多数情况下,二叉树 一词均指有根二叉树。 -
完整二叉树:每个结点的子结点数量均为 \(0\) 或者 \(2\) 的二叉树。换言之,每个结点或者是树叶,或者左右子树均非空。

- 完全二叉树:只有最下面两层结点的度数可以小于 2,且最下面一层的结点都集中在该层最左边的连续位置上。

- 完美二叉树(满二叉树):所有叶结点的深度均相同,且所有非叶节点的子节点数量均为 \(2\) 的二叉树称为完美二叉树。

树的遍历
先序遍历(前序遍历):先访问根节点,再访问左儿子,最后访问右儿子。
中序遍历:先访问左儿子,再访问根节点,最后访问右儿子。
后序遍历:先访问左儿子,再访问右儿子,最后访问根节点。
层序遍历:按层,从上往下,从左往右遍历。
如下图

先序遍历:\(FBADCEGIH\)
中序遍历:\(ABCDEFGHI\)
后序遍历:\(ACEDBHIGF\)
层序遍历:\(FBGADICEH\)
知道先序和中序或后序或中序都能确定整棵二叉树。而知道先序和后序则不能确定整棵二叉树。
-
10.2 拓展数据结构
-
10.2.1 线性结构:
堆(优先队列):
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。


-
10.2.2 图论有关:
-
稀疏图:
当稀疏图的边数远远少于完全图(任意两点有边),反之,稠密图的边数接近于或等于完全图。
-
二分图(偶图)
节点由两个集合组成,且两个集合内部没有边的图。换言之,存在一种方案,将节点划分成满足以上性质的两个集合。

性质
- 如果两个集合中的点分别染成黑色和白色,可以发现二分图中的每一条边都一定是连接一个黑色点和一个白色点。
- 二分图不存在长度为奇数的环。
判定
如何判定一个图是不是二分图呢?
换言之,我们需要知道是否可以将图中的顶点分成两个满足条件的集合。
显然,直接枚举答案集合的话实在是太慢了,我们需要更高效的方法。
考虑二分图的性质,我们可以使用 DFS 或者 BFS 来遍历这张图。如果发现了奇环,那么就不是二分图,否则是。
-
欧拉图
基本概念:
回路:一条路径的起止顶点相同。
开路:一条路径的起止顶点不相同。
通过图 \(G\) 的每条边一次且仅一次的回路称为欧拉回路。存在欧拉回路的图,称为欧拉图。
通过图 \(G\) 的每条边一次且仅一次的开路称为欧拉路,对应的有半欧拉图。
相关定理:
-
要想一个图 \(G\) 是欧拉图,图 \(G\) 需要满足两个条件:
针对有向图来说:1.图 \(G\) 是连通的,不能有孤立的点存在。
2.每个顶点的入度要等于出度。针对无向图来说:
1.图 \(G\) 是连通的,不能有孤立的点存在。
2.度数为奇数的点的个数为 \(0\)。 -
要想一个图 \(G\) 是半欧拉图,图 \(G\) 需要满足两个条件:
针对有向图来说:
1.图 \(G\) 是连通的,不能有孤立的点存在。
2.存在两个顶点,其入度不等于出度,其中一点出度比入度大 \(1\),为路径起点,另一点入度比出度大 \(1\),为路径的终点
针对无向图来说:
1.图 \(G\) 是连通的,不能有孤立的点存在。
2.度数为奇数的点的个数为 \(2\),并且这两个点一定是路径的起点和终点。
-
-
有向无环图(DAG)
拓扑排序的概念
这里就要说到拓扑排序了:
在图论中,拓扑排序是一个有向无环图的所有顶点的线性序列。且该序列必须满足下面两个条件:
- 每个顶点出现且只出现一次。
- 若存在一条从顶点 \(A\) 到顶点 \(B\) 的路径,那么在序列中顶点 \(A\) 出现在顶点 \(B\) 的前面。
有向无环图(DAG)才有拓扑排序,非 DAG 图没有拓扑排序一说。
例如,下面这个图:

它是一个 DAG 图,那么如何写出它的拓扑排序呢?这里说一种比较常用的方法:
- 从 DAG 图中选择一个 没有前驱(即入度为 \(0\))的顶点并输出。
- 从图中删除该顶点和所有以它为起点的有向边。
- 重复 1 和 2 直到当前的 DAG 图为空或当前图中不存在无前驱的顶点为止。后一种情况说明有向图中必然存在环。
于是,得到拓扑排序后的结果是 \({1, 2, 4, 3, 5}\)。
通常,一个有向无环图可以有一个或多个拓扑排序序列。
拓扑排序的应用
拓扑排序通常用来 “排序” 具有依赖关系的任务。
比如,如果用一个 DAG 图来表示一个工程,其中每个顶点表示工程中的一个任务,用有向边 \(\{A,B\}\{A,B\}\) 表示在做任务 \(B\) 之前必须先完成任务 \(A\)。故在这个工程中,任意两个任务要么具有确定的先后关系,要么是没有关系,绝对不存在互相矛盾的关系(即环路)。
当图能进行拓扑排序,这个图一定是有向无环图。
-
连通图与强连通图
在无向图中, 若从顶点 \(v1\) 到顶点 \(v2\) 有路径, 则称顶点 \(v1\) 与 \(v2\)是连通的。如果图中任意一对顶点都是连通的,则称此图是连通图。
强连通和弱连通的概念只在有向图中存在。
强连通图:在有向图中, 若对于每一对顶点 \(v1\) 和 \(v2\),都存在一条从 \(v1\) 到 \(v2\) 和从\(v2\) 到 \(v1\) 的路径,则称此图是强连通图。
弱连通图:将有向图的所有的有向边替换为无向边,所得到的图称为原图的基图。如果一个有向图的基图是连通图,则有向图是弱连通图。
-
双连通图
定义:在无向连通图中,如果删除该图的任何一个结点或边都不能改变该图的连通性,则该图为双连通的无向图。,和点连通度与边连通度来结合这来说,就是点连通度或边连通度大于 \(1\) 的图。
割点:在一个无向图中,如果删除某个顶点,这个图就不再连通(任意两点之间无法相互到达),那么这个顶点就是这个图的割点。割边:除了割点还有一种问题是求割边(也称桥),即在一个无向图中删除某条边后,图不再连通。
-
-
哈希表:
哈希算法是通过一个哈希函数,将一段数据(也包括字符串、较大的数字等)转化为能够用变量表示或是直接就可作为数组下标的数字,这样转化后的数值我们称之为哈希值, 也就是算出一个数来代表一个字符串。
我们通过哈希值从而实现很快地查找和匹配,
常用:字符串Hash和哈希表。
字符串Hash流程
如果我们用 \(O(m)\) 的时间来计算长度为 \(m\) 的字符串的哈希值,则总的时间复杂度并没有改观,这里就需要用到一个叫做滚动哈希的优化技巧。
我们选取两个合适的互素常数 \(b\)(进制)和 \(h\)(模数)\((b < h)\),假设字符串 \(C =c_1,c_2,···,c_m\),那么我们定义哈希函数:
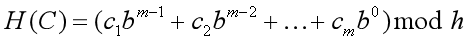
正常的数字是十进制的,这里 \(b\) 是基数,相当于把字符串看做是 \(b\) 进制数。
这一过程是递推计算的,设 \(H(c, k)\) 为前 \(k\) 个字符的构成的字符串的哈希值,则:(以下均不考虑取模的情况)
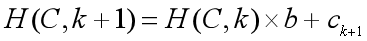
如字符串 \(C=“ACDA”\)(为方便处理,我们令 \(‘A’\)表示 \(1\),\(‘B’\) 表示 \(2\),以此类推),则:
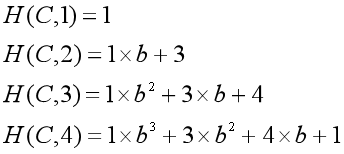
通常题目要求的判断字符串 \(C\) 从位置 \(k+1\) 开始的长度为 \(n\) 的子串 \(C'=c_k,c_{k+1},c_{k+2},···,c_{k+n-1}\) 的哈希值与另一匹配串 \(S = s_1,s_2,···,s_n\) 的哈希值是否相等,则:
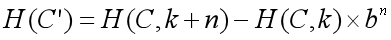
于是只要预处理出 \(b_n\),就能在 \(O(1)\) 时间内得到任意的字符串子串哈希值,从而完成字符串匹配,那么上述字符串匹配问题的总复杂度就为 \(O(n + m)\) 。
如字符串 \(C=“ACDA”,S=”CD”\),当 \(k=1, n=2\) 时:
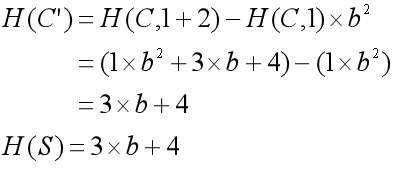
因此子串 \(C'\) 与匹配串 \(S\) 匹配。
在实现时,可以利用 \(64\) 位无符号整数计算哈希值,即取 \(h=2^{64}\),通过自然溢出省去求模运算。
字符串Hash正确性
字符串Hash对于任意不同的字符串所产生的哈希值必然是互不相同的吗?显然不是的,但概率很低,在竞赛中我们常常认为这种情况不会发生。
即便如此,我们还可以再用“双哈希”降低出现相同哈希值的概率,即取不同的模数,把不同模数算出的哈希值都记下来,只有几个哈希值都一样,我们才能判定匹配。我们通常用双哈希就可以将冲突的概率降到很低,如果分别取 \(h=10^9+7\) 和 \(h=10^9+9\),就几乎不可能发生冲突,因为他们是一对“孪生素数”。
数字哈希与哈希冲突
不过比赛更多考的是数字哈希,对于一个数 \(x\),可以定义哈希函数 \(h(x)=x\bmod p\) 来进行哈希。
如一串序列 \(a=\{7,14,6,9,10,5\}\),定义哈希函数 \(h(x)=x\bmod6\),那么将序列每个数 \(\bmod6\),新的序列 \(\{1,2,0,3,4,5\}\)。
但是改一下 \(a=\{7,14,6,9,10,12\}\) ,那么新的序列 \(a\) 为 \(\{1,2,0,3,4,0\}\),有两个\(0\),这就是哈希冲突,存储时会有两个数下标为 \(0\)。
1、开放定址法:我们在遇到哈希冲突时,去寻找一个新的空闲的哈希地址。
(1)线性探测法
当我们的所需要存放值的位置被占了,我们就往后面一直加 \(1\) 并对 \(m\) 取模直到存在一个空余的地址供我们存放值,取模是为了保证找到的位置在 \(0\) 至 \(m-1\) 的有效空间之中。
距离:

存在问题:出现非同义词冲突(两个不想同的哈希值,抢占同一个后续的哈希地址)被称为堆积或聚集现象。
(2)平方探测法(二次探测)
当我们的所需要存放值的位置被占了,会前后寻找而不是单独方向的寻找。
举例:

2、再哈希法:
同时构造多个不同的哈希函数,等发生哈希冲突时就使用第二个、第三个……等其他的哈希函数计算地址,直到不发生冲突为止。虽然不易发生聚集,但是增加了计算时间。
3、链地址法:
将所有哈希地址相同的记录都链接在同一链表中。

4、建立公共溢出区:
将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中。
本篇文章根据 NOI 大纲(2023年修订版) 以及根据自己的做题经验编写,也参考了OI wiki以及 CSDN 和 博客园 的教程,欢迎大家指正。



