知识图谱介绍(三)
八、知识表示与建模
1.知识表示是知识图谱构建中的核心环节,它涉及将现实世界的复杂信息和关系转化为计算机可理解和处理的格式。有效的知识表示不仅有助于提高知识图谱的查询效率,还能加强知识的推理能力,是实现知识图谱功能的关键。
2.知识表达是知识图谱构建的核心,是将现实世界中的知识转化为计算机可理解和处理的形式。
3.知识建模是通过形式化的语言和方法,对知识进行抽象和表示,以便于计算机的存储和推理。
一般建模方式:
(1)自顶向下的数据建模方法。先为知识图谱设计数据模式( Schema ),再依据设计好的数据模式进行有针对性的数据抽取;
(2)自底向上的数据建模方法。先进行数据的收集和整理,再根据数据内容总结、归纳其特点,提炼框架,逐步形成确定的数据模式

8.1知识表示模型
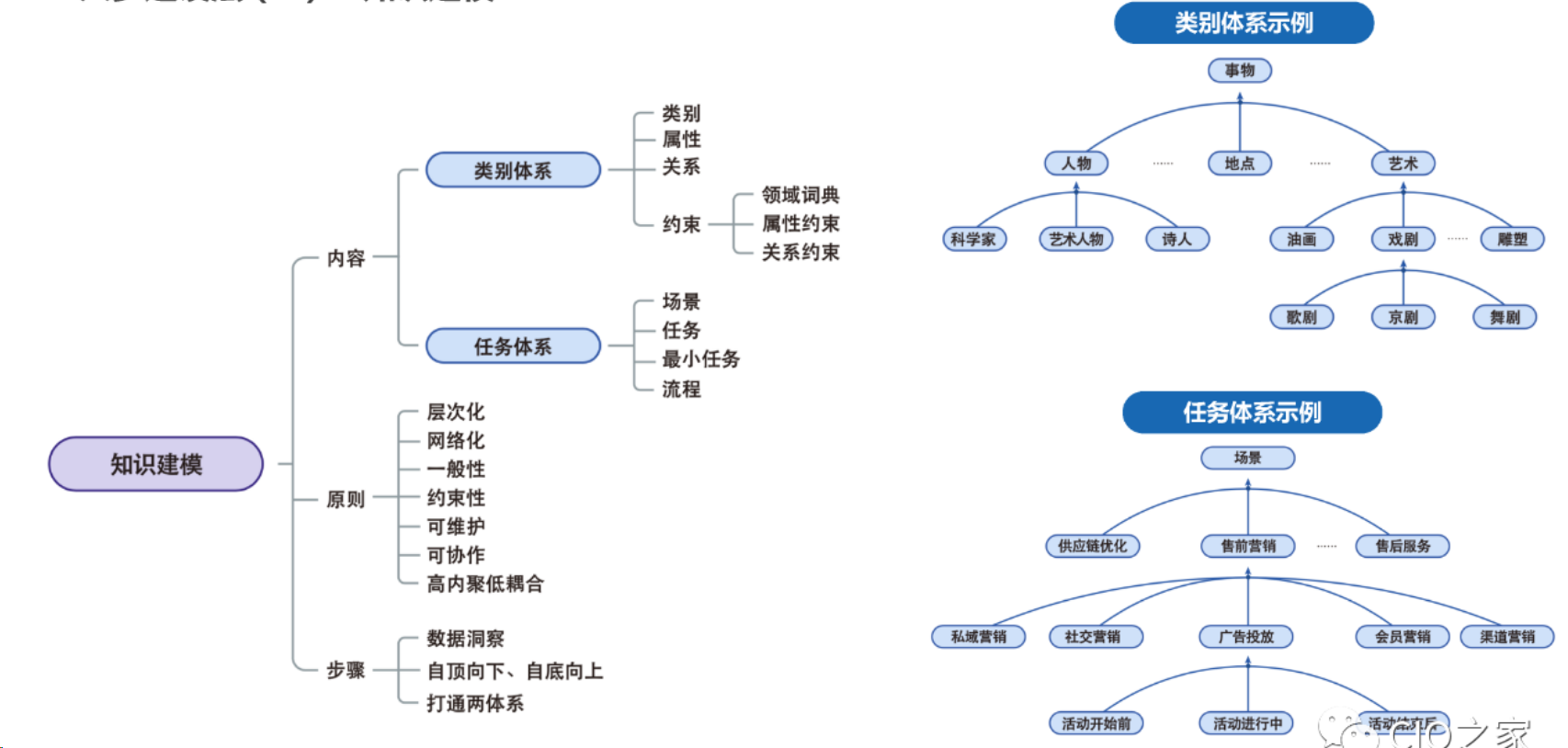
1.基于语义网的知识表达方法,利用本体和RDF等技术,对知识进行统一的表达和描述
2.基于深度学习的知识表达方法,利用神经网络模型对知识进行自动抽取和表示学习,
3.知识表示的首要任务是选择合适的模型。当前主流的知识表示模型包括资源描述框架(RDF)、Web本体语言(OWL)和属性图模型。
8.1.1RDF
RDF是一种将信息表示为“主体-谓词-宾语”三元组的模型,它使得知识的表示形式既灵活又标准化。在RDF中,每个实体和关系都被赋予一个唯一的URI(统一资源标识符),以确保其全球唯一性和可互操作性。RDF的优势在于其简单性和扩展性,但它在表达复杂关系和属性方面存在局限。
- Resource:页面、图片、视频等任何具有URI标识符。
- Description:属性、特征和资源之间的关系。
- Framework:模型、语言和这些描述的语法。
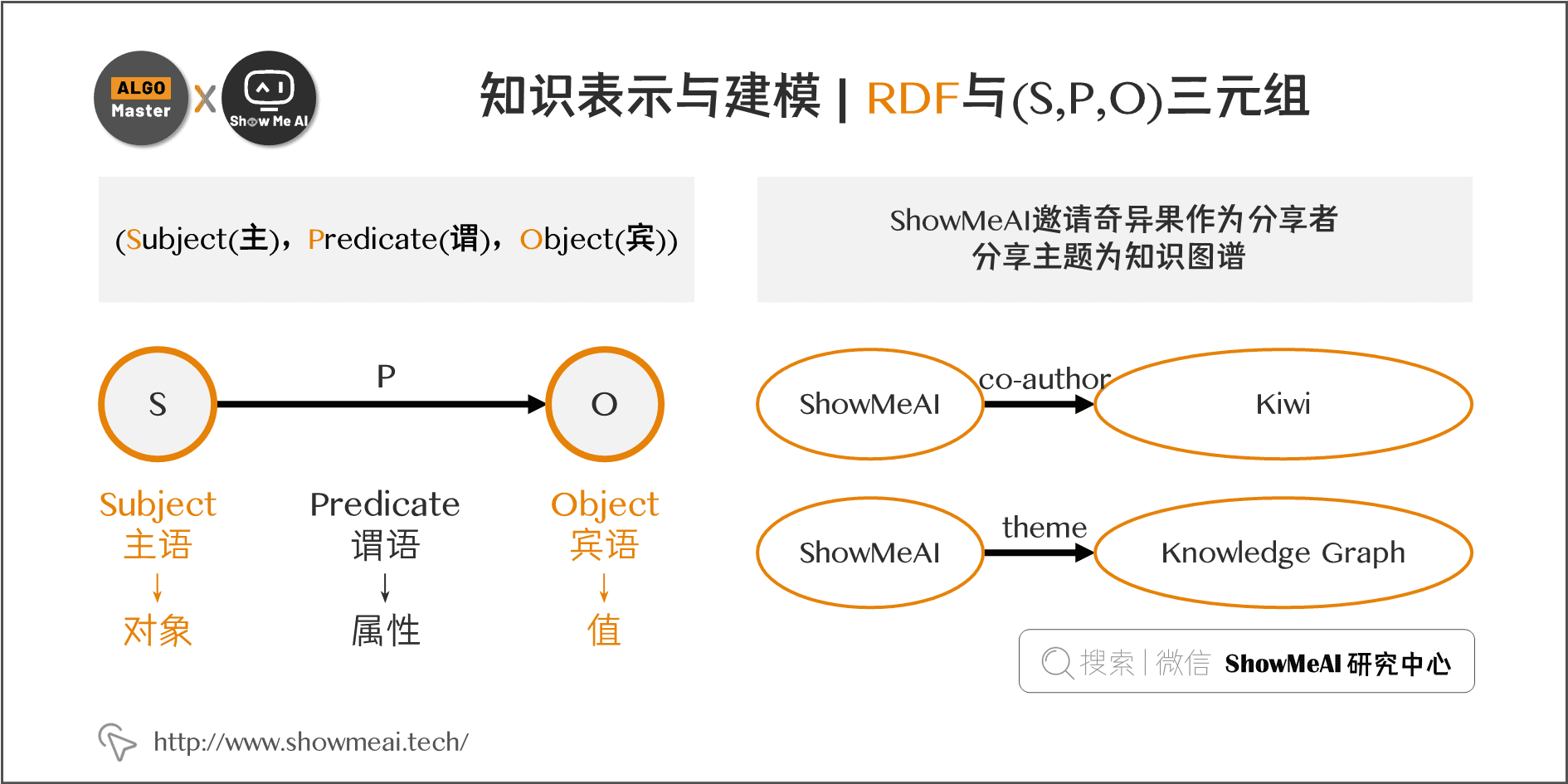
RDF由一系列三元组(triple)模型组成,即每一份知识可以被分解为 (Subject(主),Predicate(谓),Object(宾))。
- 主语(Subject):声明被描述的对象
- 谓语(Predicate):这个对象的属性
- 宾语(Object):这个属性的值
所以,RDF三元组可以被描述成 (对象,属性,值),即上文提到的 (节点,边,节点) 这样的图。
8.1.2OWL
OWL是基于RDF的一种更为复杂和强大的知识表示语言。它支持更丰富的数据类型和关系,包括类、属性、个体等,并能表达复杂的逻辑关系,如等价类、属性限制等。OWL的优势在于其表达能力和逻辑推理能力,适用于构建复杂的领域知识图谱。
8.1.3 RDFS (RDF Schema)
一个三元组就是一个关系。在RDF里可以声明一些规则,从一些关系推导出另一些关系。这些规则称为“Schema”,所以有了 RDFS(RDF Schema)。规则可以用一些词汇表示,如Class、subClassOf、type、Property、subPropertyOf、Domain、Rnage等。
8.1.3属性图模型(知识图谱Schema)
于RDF/RDFS定义了图谱的实体类型、关系(属性)类型、以及实体本身的 Schema 定义。每一层定义在 Schema 的表示语法上都是一致的。
属性图模型通过图结构来表示知识,其中节点代表实体,边代表关系,节点和边都可以附带属性。这种模型直观且易于实现,适用于大规模的图数据处理。它在图数据库中得到了广泛应用,如Neo4j、ArangoDB等。
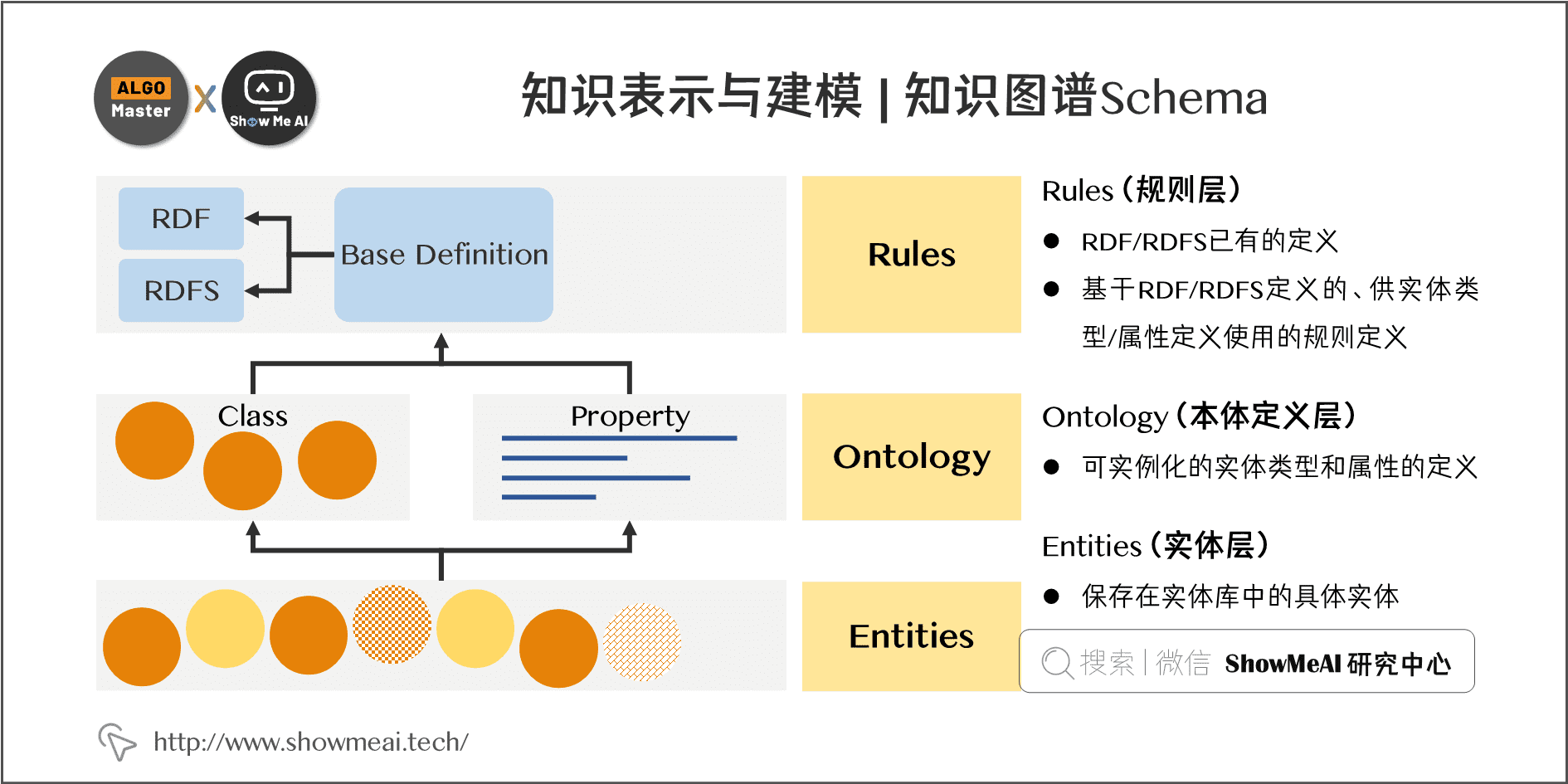
Rules层(规则层)。一些基础概念的定义(包括RDF/RDFS已有的定义,以及基于RDF / RDFS定义的、供实体类型/属性定义使用的规则定义),该层规则的定义一般在确定后是不可变的。
Ontology层(本体定义层)。包括可实例化的实体类型(Class,可继承)和属性(Property,可继承)的定义,如Thing,Person,wife,name等。
Entities层(实体层)。保存在实体库中的具体实体。
8.2本体构建Schema
本体是知识图谱中用来描述特定领域知识和概念的一组术语和定义。本体的构建是知识图谱构建的重要部分,它定义了知识图谱中的实体类别、属性和关系类型。
本体构建的关键在于准确地把握和表达领域知识。这通常需要领域专家的参与,以确保本体的准确性和全面性。在实际操作中,可以使用本体编辑工具如Protégé来创建和管理本体,同时结合NLP技术自动化提取和维护本体结构。
8.3关系提取与表示
关系提取是指从原始数据中识别出实体之间的关系,并将其加入到知识图谱中。这一步骤通常依赖于文本分析和数据挖掘技术。关系提取的方法包括基于规则的方法、机器学习方法和深度学习方法。
关系的表示要考虑到其多样性和复杂性。在简单的情况下,关系可以被直接表示为实体之间的连接。但在复杂情况下,关系可能涉及多个实体和属性,甚至是关系的层次和类型。在这种情况下,需要更复杂的数据结构和算法来准确表示关系。
8.4 知识建模技术
1.逻辑建模方法,采用形式化逻辑语言对知识进行建模,便于计算机的自动推理,
2.图形建模方法,利用图形结构对知识进行建模,可视化展示知识的关联关系。
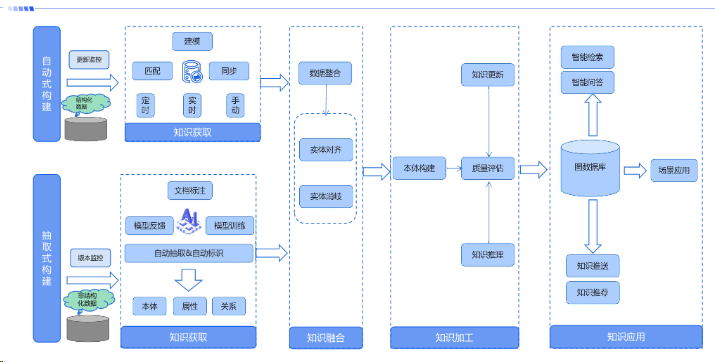
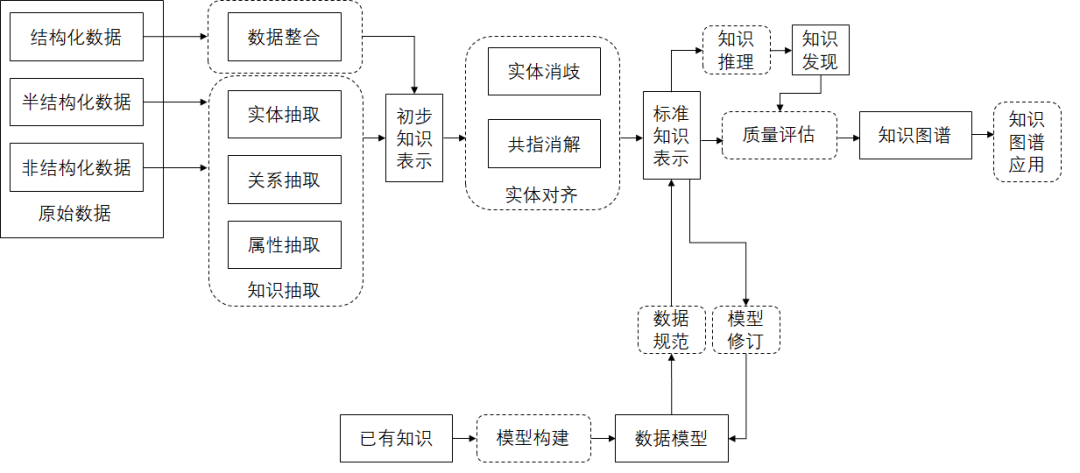
九、知识图谱构建流程及数据流向
9.1构建流程

9.2数据流向
十、知识图谱构建技术
构建知识图谱是一个复杂的过程,涉及数据处理、知识提取、存储管理等多个阶段。本节将详细探讨知识图谱构建的关键技术,并提供具体的代码示例。
10.1图数据库选择
选择合适的图数据库是构建知识图谱的首要步骤。图数据库专为处理图形数据而设计,提供高效的节点、边查询和存储能力。常见的图数据库有Neo4j、ArangoDB等。
Neo4j
Neo4j是一个高性能的NoSQL图形数据库,支持Cypher查询语言,适合于处理复杂的关系数据。它的优势在于强大的关系处理能力和良好的社区支持。
ArangoDB
ArangoDB是一个多模型数据库,支持文档、键值及图形数据。它在灵活性和扩展性方面表现出色,适用于多种类型的数据存储需求。
10.2构建流程
构建知识图谱的过程大致可分为数据预处理、实体关系识别、图数据库存储和优化几个阶段。
数据预处理
数据预处理包括数据清洗、实体识别等步骤,目的是将原始数据转换为适合构建知识图谱的格式。
import pandas as pd
# 示例:清洗和准备数据
def clean_data(data):
# 数据清洗逻辑
cleaned_data = data.dropna() # 去除空值
return cleaned_data
# 假设我们有一个原始数据集
raw_data = pd.read_csv('example_dataset.csv')
cleaned_data = clean_data(raw_data)
实体关系识别
实体关系识别是从清洗后的数据中提取实体和关系。这里以Python和PyTorch实现一个简单的命名实体识别模型为例。
import torch
import torch.nn as nn
import torch.optim as optim
# 示例:定义一个简单的命名实体识别模型
class NERModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(NERModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
embedded = self.embedding(x)
lstm_out, _ = self.lstm(embedded)
out = self.fc(lstm_out)
return out
# 初始化模型、损失函数和优化器
model = NERModel(vocab_size=1000, embedding_dim=64, hidden_dim=128)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
图数据库存储
将提取的实体和关系存储到图数据库中。以Neo4j为例,展示如何使用Cypher语言存储数据。
// 示例:使用Cypher语言在Neo4j中创建节点和关系
CREATE (p1:Person {name: 'Alice'})
CREATE (p2:Person {name: 'Bob'})
CREATE (p1)-[:KNOWS]->(p2)
优化和索引
为提高查询效率,可以在图数据库中创建索引。
// 示例:在Neo4j中为Person节点的name属性创建索引
CREATE INDEX ON :Person(name)
10.3深度学习在构建中的应用
深度学习技术在知识图谱构建中主要用于实体识别、关系提取和知识融合。以下展示一个使用深度学习进行关系提取的示例。
# 示例:使用深度学习进行关系提取
class RelationExtractionModel(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(RelationExtractionModel, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, 2) # 假设有两种关系类型
def forward(self, x):
lstm_out, _ = self.lstm(x)
out = self.fc(lstm_out[:, -1, :])
return out
# 初始化模型、损失函数和优化器
relation_model = RelationExtractionModel(input_dim=300, hidden_dim=128)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(relation_model.parameters(), lr=0.001)
在这个模型中,我们使用LSTM网络从文本数据中提取特征,并通过全连接层预测实体间的关系类型。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号