游戏和transformer相关
(30 封私信 / 1 条消息) embedding层和全连接层的区别是什么? - 知乎 (zhihu.com)
[DL] 游戏AI中的单位建模与目标选择机制 - 知乎 (zhihu.com)
温故知新——激活函数及其各自的优缺点 - 知乎 (zhihu.com)
transformer与强化学习
我眼中2022深度强化学习发展趋势 - 深度强化学习实验室 (deeprlhub.com)
结合 Transformer 与 强化学习(初试,失败) - 知乎 (zhihu.com)
(30 封私信) 为什么目前的强化学习里深度网络很少用 transformer ,更多的是 lstm rnn 这类网络? - 知乎 (zhihu.com)
transformer在RL中不好用:
- Sample efficiency: 在 RL 的一大分类—— actor-critic 算法中,actor和critic是交替训练的。这就要求他们各自的模型需要在较少的样本训练中迅速适应对方的变化。然而,众所周知,Transformer 需要大量的样本来学习,因此自然而然面临 sample efficiency 的问题
- Implicit sequential information: 经典强化学习任务的主要的目标是去学习一个 MDP 环境中的最优策略,这表示着时序信息在预测下一个行动中起着非常重要的作用。在常规的 RL 场景中,由于智能体根据其自然的时间顺序逐一接收单帧的 observation,并不会产生什么问题。然而,Transformer在每一步都会收到一连串的 observations,而它们的顺序信息通常是由位置编码给出的,即顺序信息不是明确给出的,而是必须由 Transformer 自己来学习的。
- Transformer 目前的训练速度较慢,资源消耗较大
-
在线的过程实际上有意义的样本都来自ood——没有见过的,然后对它们的value进行快速的拟合——explore+exploitation。因此,众所周知的data efficiency matters,要求:1)较少样本下快速的拟合,2)网络高度可变以适应持续不断地ood。这两点都不是trm所符合的。
-
trm对时间先后顺序的记忆何识别能力比rnn弱,trm采用的positional encoding对提取不同行为先后顺序的能力弱于rnn,而在强化学习中这种先后顺序是比较重要的。2. trm通常要在较大规模的任务下才能发挥优势,在小数据任务下trm比rnn优势很小或者根本没优势,而多数使用强化学习的任务都使用相对较小的数据和模型。
- 个人猜测是策略梯度的方差太大,不适合用于优化transformer。
- transformer模型中缺少一种解释输入序列中单词顺序的方法,transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding
transformer八股
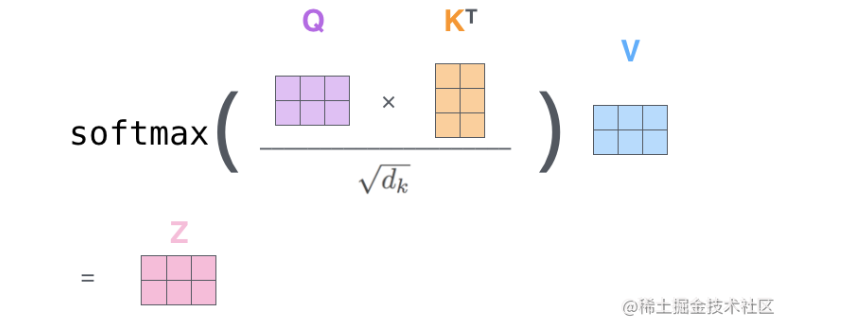
Transformer各层网络结构详解!面试必备!(附代码实现) - 掘金 (juejin.cn)
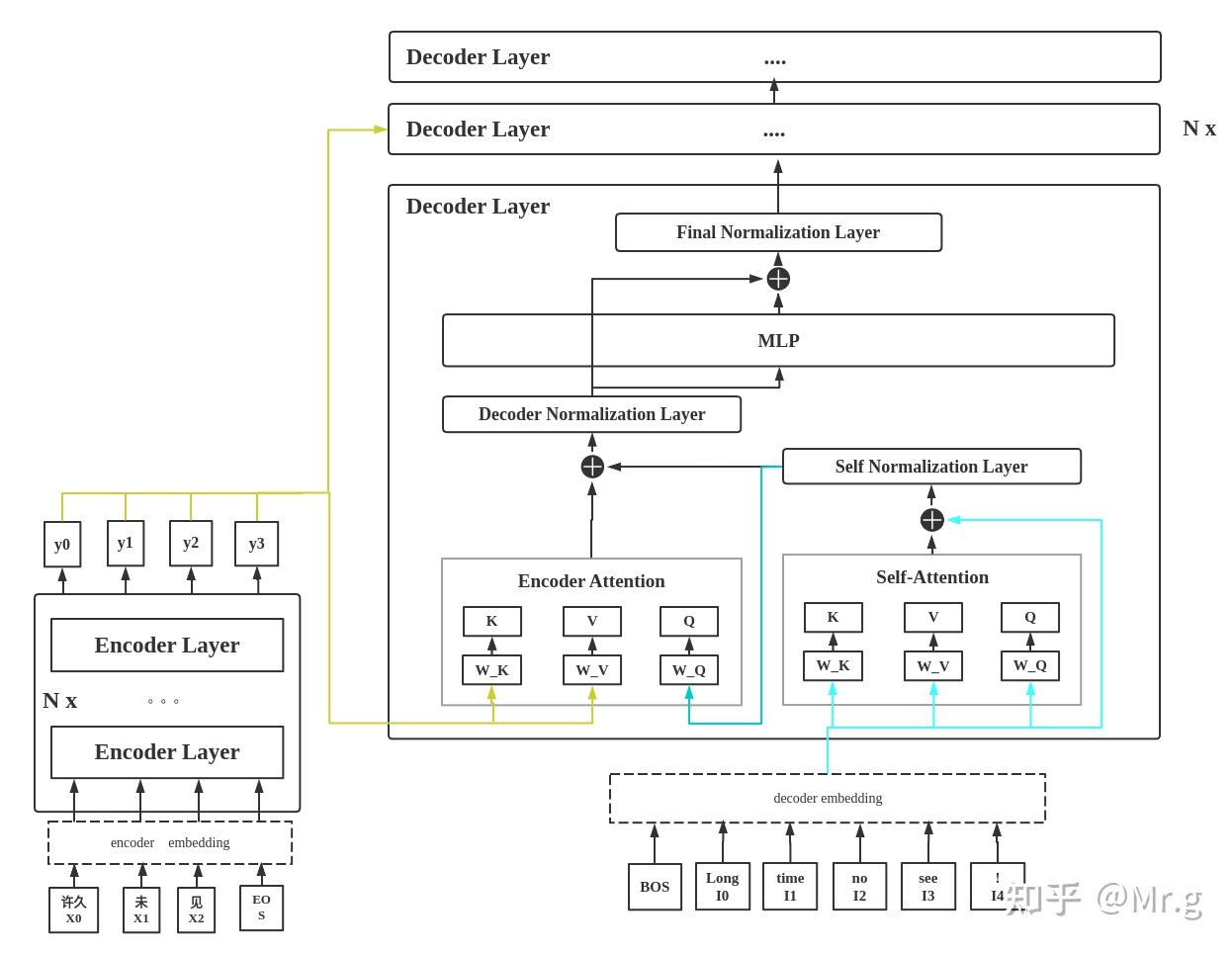
Transformer Decoder详解 - 知乎 (zhihu.com)
mask attention机制
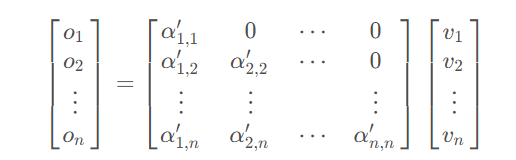
(124条消息) MultiHead-Attention和Masked-Attention的机制和原理_mask multi-head attention_iioSnail的博客-CSDN博客
- Query(to match others):输入信息,具有引导作用,包含我们需要哪些信息这个想法(我在搜索栏中输入:灰色男士毛衣,我希望系统返回一些相似的商品给我)
- Key(to be matched):内容信息,表示其他待匹配的商品(当系统收到灰色、男士毛衣这样的信息后,去匹配数据库中的所有商品)
- Attention(Q, K):表示Query和Key的匹配程度(系统中商品(Key)很多,其中符合我的描述(Query)的商品的匹配程度会高一点)
- Value(information to be extracted):信息本身,V只是单纯表达了输入特征的信息
(124条消息) 21个Transformer面试题的简单回答_视学算法的博客-CSDN博客
也就是bn将第一个样本第一个通道的数据和第二个样本第一个通道的数据做均值方差处理。如:“中国是我家 ”和“我们爱护它”这个两个样本,将每个通道做处理,也就是“中“和“我”,“国”和“们”,以此Norm处理后,句子与句子间的关联性消失了,会有多余的字无法估算方差等;而用LN,则默认“中国是我家”的五个字在同一维度下,同理,“我们爱护它”也是同一维度,也就是每个单词都在这个句子的语义信息里包含着,做Norm操作后,依旧保留词长度,且使句子的前后词关联性更强
通过把一部分不重要的复杂信息损失掉,以此来降低拟合难度以及过拟合的风险,从而加速了模型的收敛
美国运通 PyTorch NN: 培训 |卡格尔 (kaggle.com)
openai Surgery:论文笔记:基于大规模深度强化学习的Dota 2 AI - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号