

raft笔记
目的:一致性算法,允许一组机器作为一个一致的组来工作,这些组可以承受某些成员的故障,提高可用性
领导选举,日志同步,快照,集群变动
复制状态机用于解决分布式系统中的各种容错问题,会出现共识算法
共识和复制状态机通过保持复制日志的一致性
raft是一种日志复制算法
Raft通过首先选举一个领导者,然后让领导者完全负责管理复制的日志来实现一致性
一个 Raft 集群包含若干个服务器节点;通常是 5 个
日志复制维护特性
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。//来自唯一leader
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。//来自一个一致性检查,发送时附加上一次的结果
不一致的结果通过强制follower与leader统一来解决
为了保证应用了日志的统一也就是不会被覆盖,领导之选举的时候需要附加完整性的限制
raft协议通过约束当前任期不能提交之前任期的日志条目保证避免提交之前任期符合提交条件但未提交日志。
raft在集群更改的时候一次只能从集群中添加或删除一个服务器
raft协议通过约束当前任期不能提交之前任期的日志条目保证避免提交之前任期符合提交条件但未提交日志。
no-op补丁
聊聊Raft的性能优化_raft算法优化_李兆龙的博客的博客-CSDN博客
原始的RAFT论文中对非对称的网络划分处理不好,比如S1、S2、S3分别位于三个IDC,其中S1和S2之间网络不通,其他之间可以联通。这样一旦S1或者是S2抢到了Leader,另外一方在超时之后就会触发选主,例如S1为Leader,S2不断超时触发选主,S3提升Term打断当前Lease,从而拒绝Leader的更新。这个时候可以增加一个trick的检查,每个Follower维护一个时间戳记录收到Leader上数据更新的时间,只有超过ElectionTImeout之后才允许接受Vote请求。这个类似Zookeeper中只有Candidate才能发起和接受投票,就可以保证S1和S3能够一直维持稳定的quorum集合,S2不能选主成功
由于Snapshot可能会比较大,RPC都有消息大小限制,需要采用些手段进行处理:可以拆分数据采用N个RPC,每个RPC带上offset和data的方式;也可以采用Chunk的方式,采用一个RPC,但是拆分成多个Chunk进行发送。
RAFT完善
功能完善
原始的RAFT在实际使用中还需要对一些功能进行完善,来避免一些问题。
- pre-vote
网络划分会导致某个节点的数据与集群最新数据差距拉大,但是term因为不断尝试选主而变得很大。网络恢复之后,Leader向其进行replicate就会导致Leader因为term较小而stepdown。这种情况可以引入pre-vote来避免。follower在转变为Candidate之前,先与集群节点通信,获得集群Leader是否存活的信息,如果当前集群有Leader存活,follower就不会转变为Candidate,也不会增加term。
- transfer leadership
在实际一些应用中,需要考虑一些副本局部性放置,来降低网络的延迟和带宽占用。RAFT在transfer leadership的时候,先block当前leader的写入过程,然后排空target节点的复制队列,使得target节点日志达到最新状态,然后发送TimeoutNow请求,触发target节点立即选主。这个过程不能无限制的block当前leader的写入过程,这样会影响服务,需要为transfer leadership设置一个超时时间,超时之后如果发现term没有发生变化,说明target节点没有追上数据并选主成功,transfer就失败了。
在facebook的hydrabase中跨IDC复制方案中,通过设置不同的election_timeout来设置不同IDC的选主优先级,election_timeout越小选主成功概率越大。
- setpeer
RAFT只能在多数节点存活的情况下可以正常工作,在实际中可能会存在多数节点故障只存在一个节点的情况,这个时候需要提供服务并及时修复数据。因为已经不能达到多数,不能写入数据,也不能做正常的节点变更。libRAFT需要提供一个SetPeer的接口,设置每个节点看到的复制组节点列表,便于从多数节点故障中恢复。比如只有一个节点S1存活的时候,SetPeer设置节点列表为{S1},这样形成一个只有S1的节点列表,让S1继续提供读写服务,后续再调度其他节点进行AddPeer。通过强制修改节点列表,可以实现最大可用模式。
- 指定节点进行Snapshot
RAFT中每个节点都可以做snapshot,但是做snapshot和apply日志是互斥的,如果snapshot耗时很长就会导致apply不到最新的数据。一般需要FSM的数据支持COW,这样才能异步完成Snapshot Save,并不阻塞apply。实际中很多业务数据不支持COW,只能通过lock等方式来进行互斥访问,这个时候进行snapshot就会影响服务的可用性。因此,需要指定某个follower节点进行snapshot,完成之后通知其他节点来拖Snapshot,并截断日志。
- 静默模式
RAFT的Leader向Follower的心跳间隔一般都较小,在100ms粒度,当复制实例数较多的时候,心跳包的数量就呈指数增长。通常复制组不需要频繁的切换Leader,我们可以将主动Leader Election的功能关闭,这样就不需要维护Leader Lease的心跳了。复制组依靠业务Master进行被动触发Leader Election,这个可以只在Leader节点宕机时触发,整体的心跳数就从复制实例数降为节点数。社区还有一种解决方法是MultiRAFT,将复制组之间的心跳合并到节点之间的心跳。
- 节点分级
在数据复制和同步的场景中,经常有增加Follower来进行分流的需求,比如bigpipe的common broker。对于级联的broker并没有强一致性复制的需求,这个时候可以对节点进行分级。将RAFT复制组中的节点定为Level0,其他Level不参与RAFT复制,但是从上一层节点中进行异步复制Log。当K>=0时,Level K+1从Level K中进行异步复制。每个节点可以指定上一层Level的某个节点作为复制源,也可以由Leade或者是由外部Master进行负载均衡控制。
性能优化
原始的RAFT设计中依然有些性能不尽如人意的地方,需要在实现libRAFT过程进行改进。
- 流水线复制
Leader跟其他节点之间的Log同步是串行batch的方式,每个batch发送过程中之后到来的请求需要等待batch同步完成之后才能继续发送,这样会导致较长的延迟。这个可以通过Leader跟其他节点之间的PipeLine复制来改进,有效降低更新的延迟。
- Leader慢节点优化
RAFT中Client的读写都通过Leader完成,一旦Leader出现IO慢节点,将会影响服务质量,需要对读写进行分别优化。 写入的时候Leader需要先将Log Entry写到本地,然后再向其他节点进行复制,这样写入的延迟就是IO_Leader + Min(IO_Others),IO延迟较高。其实RAFT的模型要求的是一条LogEntry在多数节点上写入成功即可认为是Committed状态,就可以向状态机进行Apply,可以将Leader写本地和复制异步进行,只需要在内存中保存未Committed的Log Entry,在多数节点已经应答的情况下,无需等待Leader本地IO完成,将内存中的Log Entry直接Apply给状态机即可。即使会造成持久化的Base数据比Log数据新,因为节点启动都是先加载上一个Snapshot再加载其后的Log,对数据一致性也不会造成影响。 对于读取,在Single Client的模型下面,可以将最后写入成功的多数节点列表返回给Client,这样Client从这几个节点中就可以进行Backup Request了,就可以跳过Leader进行读取了,Client的读取中带上CommittedId,这样即使Follower节点还没有收到Leader的心跳或者是下一个AppendEntries,也可以将Log Entry转换为Committed,并Apply到状态机中,随后将Read也发往状态机。
- 本地IO Batch写入
传统的元信息复制需求,需要对每一条更新都进行fsync,保证刷到磁盘上。如果针对每一条Log Entry都进行fsync将会比较费,可以采用类似网络Batch发送的的方式进行本地磁盘IO Batch写入,来提高吞吐。
multi-raft
建立多个raft region,用来增加数据处理能力,以及缓解每个raft中的log一致性问题
shardctrler,其实它就是一个高可用的集群配置管理服务。它主要记录了当前每个 raft 组对应的副本数个节点的 endpoint 以及当前每个 shard 被分配到了哪个 raft 组这两个 map。
客户端的每一次请求都可以通过询问 shardctrler 来路由到对应正确的数据节点
所有涉及修改集群分片状态的操作都应该通过 raft 日志的方式去提交,这样才可以保证同一 raft 组内的所有分片数据和状态一致。
在 6.824 的框架下,涉及状态的操作都需要 leader 去执行才能保持正确性,否则需要添加一些额外的同步措施,而这显然不是 6.824 所推荐的。因此配置更新,分片迁移,分片清理和空日志检测等逻辑都只能由 leader 去检测并执行。
我们不仅不能在配置更新时同步阻塞的去拉取数据,也不能异步的去拉取所有数据并当做一条 raft 日志提交,而是应该将不同 raft 组所属的分片数据独立起来,分别提交多条 raft 日志来维护状态。因此,ShardKV 应该对每个分片额外维护其它的一些状态变量。
分片迁移协程负责定时检测分片的 Pulling 状态,利用 lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去拉取数据。
注意这里使用了 waitGroup 来保证所有独立地任务完成后才会进行下一次任务。此外 wg.Wait() 一定要在释放读锁之后,否则无法满足 challenge2 的要求。
在拉取分片的 handler 中,首先仅可由 leader 处理该请求,其次如果发现请求中的配置版本大于本地的版本,那说明请求拉取的是未来的数据,则返回 ErrNotReady 让其稍后重试,否则将分片数据和去重表都深度拷贝到 response 即可。
在 apply 分片更新日志时需要保证幂等性:
- 不同版本的配置更新日志:仅可执行与当前配置版本相同地分片更新日志,否则返回 ErrOutDated。
- 相同版本的配置更新日志:仅在对应分片状态为 Pulling 时为第一次应用,此时覆盖状态机即可并修改状态为 GCing,以让分片清理协程检测到 GCing 状态并尝试删除远端的分片。否则说明已经应用过,直接 break 即可。
分片清理协程负责定时检测分片的 GCing 状态,利用 lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去删除分片。
注意这里使用了 waitGroup 来保证所有独立地任务完成后才会进行下一次任务。此外 wg.Wait() 一定要在释放读锁之后,否则无法满足 challenge2 的要求。
在删除分片的 handler 中,首先仅可由 leader 处理该请求,其次如果发现请求中的配置版本小于本地的版本,那说明该请求已经执行过,否则本地的 config 也无法增大,此时直接返回 OK 即可,否则在本地提交一个删除分片的日志。
在 apply 分片删除日志时需要保证幂等性:
- 不同版本的配置更新日志:仅可执行与当前配置版本相同地分片删除日志,否则已经删除过,直接返回 OK 即可。
- 相同版本的配置更新日志:如果分片状态为 GCing,说明是本 raft 组已成功删除远端 raft 组的数据,现需要更新分片状态为默认状态以支持配置的进一步更新;否则如果分片状态为 BePulling,则说明本 raft 组第一次删除该分片的数据,此时直接重置分片即可。否则说明该请求已经应用过,直接 break 返回 OK 即可。
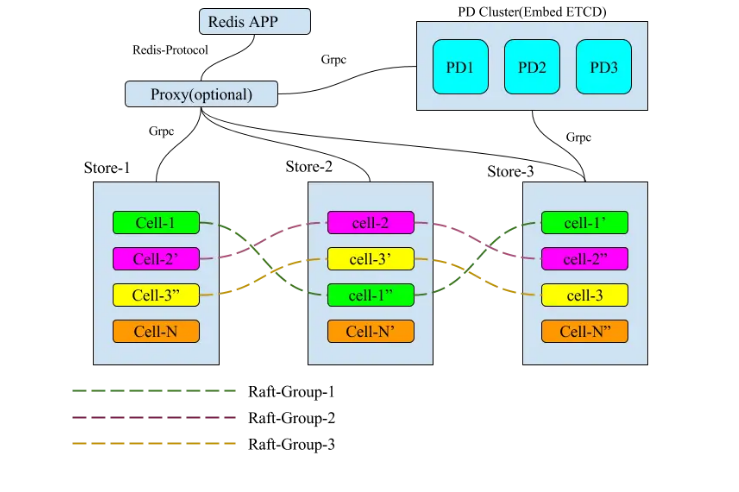
Elasticell-Multi-Raft实现 - 知乎 (zhihu.com)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
· Manus的开源复刻OpenManus初探