
数据分析-机器学习面试题
1.数据处理时缺失指怎么处理
1)删除样本或删除字段(缺失比例超过80%以上)
2)用中位数、平均值、众数等填充(平均数:数据分布近似于正态分布,中位数:数据分布近似于偏态分布,众数:特征值为离散值)
3)插补:同类均值插补、多重插补、极大似然估计
4)用其它字段构建模型,预测该字段的值,从而填充缺失值(注意:如果该字段也是用于预测模型中作为特征,那么用其它字段建模填充缺失值的方式,并没有给最终的预测模型引入新信息)
5)onehot,将缺失值也认为一种取值
6)压缩感知及矩阵补全
2.L1和L2的区别

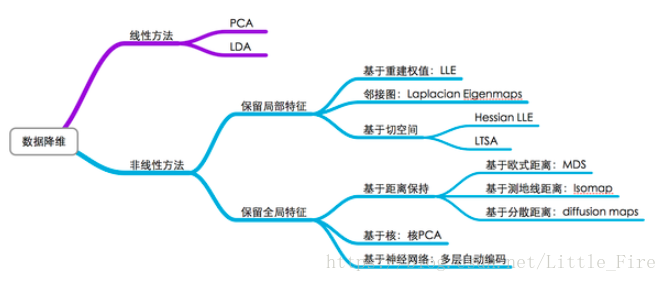
3.高维数据如何降维
1)减少预测变量的个数;
2)确保这些变量是相互独立的;
3) 提供一个框架来解释结果。
4.特征处理,连续型和非连续性,给了个例子,年龄和user_id两个特征如何处理
连续型:
1)特征归一化:线性放缩到[-1,1],放缩到均值0,方差1.按照特征的行处理数据。目的是在于样本向量在点乘运算或者其他核函数计算相似性时,拥有统一的标准。
2) 特征标准化:
0-1 标准化:
x(标准化)=(x-最小值)/(最大值-最小值)
按照列处理,通过求Z-score的方法,将样本的特征值转化到同一量纲下。
x(标准化)=(x-均值)/标准差
3)连续变量离散化(有监督离散方法:决策树):二值化处理 : 将细粒度的度量转化为粗粒度的度量,使得特征的差异化更大。取整:
4) 特征多项式的交互:捕获特征之间的相关性
5) 数据分布的倾斜处理:
log变化: log 变化倾向与拉高那些落在较低范围内的自变量取值,压缩那些落在较高的幅度范围内的自变量的取值,log 变化能给稳定数据的方差,使得数据的分布接近正太分布并使得数据与分布的均值无关。Box_Cox 也有相似的效果,出现负数,使用常数进行偏移。
6) 缺失值处理
数据补全(用0替换 ,平均数替换 ,众数替换 ,预测模型替换),删除缺失行,不处理
离散型:
1) onehot 编码: 可以将离散特征扩展到欧式空间,离散特征的某个取值就对应欧式空间的某个点。特征之间的距离计算或相似度计算是非常重要的,常用的距离或者相似性计算都是在欧式空间的相似度计算,计算余弦相似性,基于的是欧式空间。onehot 会让距离的计算更加合理。
2 )dummy encoding 哑变量编码
3 )label-encoding 标签编码
4 )count-Encoding 频数编码 (可以去量纲化,秩序,归一化)
将分类变量替换为训练集中的计数,对线性和非线性算法都很有用,可以对异常值敏感,可以添加对数转化,适用于计数,用1替换看不见的变量,可能会发生冲突: 相同的编码,不同的变量。
5 )Target encoding 二分类 用目标变量中的某一类的比例来编码
为每个分类变量提供唯一的数字ID,适用于非线性基于树的算法,不增加维度,
6 )Hash encoding :
避免及其稀疏的数据
基于书的方法不需要进行特征的归一化,例如随机深林,bagging和boosting等,基于参数或距离的模型,都需要归一化。
5.LR了解吗,如何解决过拟合问题
1)增大正则化
2)减小模型复杂度(减少特征数量)
3)解决数据不平衡的问题
6.如何评估模型结果,我把分类和回归分别解释,介绍各种评估方式的不足,还问了ROC曲线横纵坐标
http://www.360doc.com/content/19/1126/10/58682131_875542901.shtml
7.Random Forest & GBDT 的区别, max depth哪个倾向于更深一点
RandomForest 与 GBDT 的异同:
相同点:
1)都由很多棵树组成
2)最终的结果是由多棵树一起决定的
不同点:
1)RandomForest中的树可以是分类树,也可以是回归树,而GBDT只能由回归树(CART)组成,这也说明GBDT各个树相加是有意义的
2)RandomForest中的树是并行生成的,而GBDT是串行生成的,GBDT中下一颗树要去拟合前一颗树的残差,所以GBDT中的树是有相关关系的,而RandomForest中的树的相关性依赖于Boostrap生成的样本子集的相关性
3)RandomForest 对异常值不敏感,GBDT敏感
4)RandomForest是通过降低模型方差来提高性能的,而GBDT是通过降低偏差来提高性能
8.Logistic regression 的Loss Function是什么,为什么不用和LR一样的loss
9.如何预测今年12月底的每日投稿量(如何建模,需要用什么数据)
10.逻辑回归拟合的好坏怎么看,ROC的横轴纵轴是什么
(1)直接对模型的拟合优劣进行检验(2)对模型的一个或者几个参数进行显著性检验
如图所示,La 表示系数β似然最大时的似然方程最大值;Lb表示截距似然最大时的似然方程最大值;Lc表示La的理论最大值,等于1。这就是拟合优度,越接近1代表模型拟合优度越好。
横轴:FPR 纵轴:TPR
11.决策树熟悉吗?过拟合怎么办?逻辑回归过拟合怎么办?
决策树结构:根部节点+非叶子节点(测试条件)+分支(测试结果)+叶子节点(分类后的分类标记)
优点:速度快,准确度高,可处理连续和离散变量,无需参数假设,可处理高维数据(特征值较多的数据)
缺点:容易过拟合,忽略了属性之间的相关性
减缓过拟合:缩小树结构的规模
逻辑回归过拟合解决:
1)减少特征值
2)特征值数量不变的情况下,引入正则化惩罚项,缩小最适参数的值
12.你觉得数据分析和算法有什么区别
数据挖掘就是从海量数据中找到隐藏的规则,数据分析一般要分析的目标比较明确。
有一些人总是不及时向电信运营商缴钱,如何发现它们?
数据分析:通过对数据的观察,我们发现不及时缴钱人群里的贫困人口占82%。所以结论是收入低的人往往会缴费不及时。结论就需要降低资费。
数据挖掘:通过编写好的算法自行发现深层次的原因。原因可能是,家住在五环以外的人,由于环境偏远不及时缴钱。结论就需要多设立一些营业厅或者自助缴费点,普及网络缴费
13.准确率和召回率的定义
准确率precision:查准率,预测为正样本的样本中,真正为正样本的占比
召回率recall:查全率=真正率,真正为正样本的样本中,预测正确的有多少
14.梯度下降有了解吗
15.讲一下交叉验证
CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标.
16.smote过采样做法,会出现什么问题
1)过采样单纯重复了正例(少例),可能放大噪声,风险是过拟合。
2)欠采样抛弃了大部分反例(多例),浪费数据,模型偏差较大。另一种做法是反复欠采样,把多例分成不重叠的N份,分别与少例组合,训练N个模型,然后组合。缺点是训练多个模型开销大,组合时可能有额外错误,少例被反复利用,风险是过拟合。
3)SMOTE相较于一般的过采样,降低了过拟合,是soft 过采样,抗噪能力强,缺点是运算开销大,可能会生成异常点。
17.过采样,一个样本点复制多次会导致的问题
过采样对少数类样本进行了多次复制, 扩大了数据规模, 增加了模型训练的复杂度, 同时也容易造成过拟合
18.GBDT 与 XGBOOST的比较:
1)传统的GBDT以CART树作为基分类器,而XGBOOST还支持线性分类器,此时的线性分类器自带正则项
2)传统的GBDT在优化时,只用到了loss function的一阶导信息,而XGBOOST对loss function做了Taylor展开,用到了二阶导信息
3)XGBOOST在loss function中引入了正则项,防止过拟合,正则项里包含叶节点数以及每个叶节点上的score的L2的平方和在计算划分增益时,如果gain < gamma, 不划分,gain> gamma,划分,这相当于决策树的预剪枝。 gamma是叶节点个数的参数
4)XGBOOST还借用了RandomForest中的列抽样思想,也支持在划分节点时,只考虑部分属性(现状sklearn中的GBDT也实现了列抽样)
5)XGBOOST可以自动学习出缺失值的分裂方向,论文中的default direction
(具体做法时,遍历的尝试将所有的缺失值分裂到所有方向{left or right},split and default directions with max gain)
6)XGBOOST实现了并行化,这个并行化是特征粒度上的并行化:划分节点时,每个特征并行计算,同时每个特征的划分节点也是并行计算(这是加速最猛的处理)
7)XGBOOST提出了block的概念,简单的说将排序后的特征值放在block中,以后划分特征的时候,只需要遍历一次即可,因为决策树在处理属性值时,需要将属性值先排序,这是最耗时的步骤,而block预先存储了排序的特征值,在后续过程中可以重复利用这个结构中的数据,同时,计算每个特征的划分增益可以并行处理了
Collecting statistics for each column can be parallelized,giving us a parallel algorithm for split finding!!
8)贪心算法在选择最佳划分方式时需要遍历所有的划分点子集,在数据非常大时,这会非常低效,xgboost提出了近似直方图计算,根据数据的二阶导信息进行排序,提出一些候选划分点子集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号