HDFS租约实践
一、租约详解
Why租约
HDFS的读写模式为 "write-once-read-many",为了实现write-once,需要设计一种互斥机制,租约应运而生
租约本质上是一个有时间约束的锁,即:在一定时间内对租约持有者(也就是客户端)赋予一定的权限
HDFS租约模型
<Lease>
Lease和DFSClient的对应关系为一对一(即:在Hdfs-Server端,为每个DFSClient建立一个Lease),Lease包含的主要信息有:
* holder:租约持有者(即:DFSClient)
* lastUpdate:上次续约时间
* paths:该租约持有的文件路径
* softLimit和hardLimit
> 当前时间减去Lease的lastUpdate超过softLimit,允许其它DFSClient抢占该Client持有的filepath(softLimit的默认值为1min)
> 当前时间减去Lease的astUpdate超过hardLimit,允许LeaseManager强制将该租约回收销毁(hardLimit的默认值为1hour)
<LeaseManager>
顾名思义,LeaseManager是租约的管理者,运行于HDFS-Server端,其主要功能特性有:
* 维护了DFSClient和Lease的映射关系(参见leases属性)
* 维护了filePath和Lease的映射关系(参见sortedLeasesByPath属性)
* 对租约进行生命周期和状态的管理:
> 创建租约或正常情况下的销毁租约
> 赋予(或撤销)FilePath权限给租约(撤销FilePath,如:执行文件流的close方法)
> 接受续约请求,对租约进行续约处理(即:更新Lease的lastUpdate字段)
> 对超过hardLimit的租约进行销毁处理(参见:LeaseManager.Monitor类)
<LeaseRenewer>
顾名思义,LeaseRenewer是租约的续约者,运行于HDFS-Client端,其主要功能特性有:
* LeaseRenewer维护了一个DFSClient列表和一个定时线程,循环不断的为各个DFSClient进行续约操作
* LeaseRenew本质上是一个heartbeat,方便对超时的DFSClient进行容错处理
* 从client到server端续约的主流程如下:LeaseRenewer -> DFSClient -> NameNodeRpcServer -> FSNamesystem -> LeaseManager
* 其它细节此处不再阐述,直接看源码即可
<FSNamesystem>
LeaseManager用来管理租约,那么,FSNamesystem用来协调租约,其主要功能特性有:
* FSNamesystem中和租约相关最核心的一个方法是recoverLeaseInternal,startFile方法、appendFile方法和recoverLease方法都会调用该方法,该方法主要功能有:
> 验证ReCreate
如果待操作的文件path已经存在于该DFSClient的Lease的paths列表中,则抛AlreadyBeingCreatedException,
提示 "current leaseholder is trying to recreate file"
> 验证OtherCreate
如果待操作的文件path已经存在于其它DFSClient的Lease的paths列表中,此时有两种策略:如果那个DFSClient的Lease的softLimit已经过期,
系统会尝试进行Lease-Recovery,然后把path从那个DFSClient的Lease的paths中remove掉,这样新的Client便获取了该path的占有权限;
如果那个DFSClient的Lease的softLimit还未过期,则抛AlreadyBeingCreatedException,提示 "because this file is already being created by ... on ..."
> 验证Recovery
这个比较简单,如果待操作的文件还处于租约的Recovery状态,则抛异常RecoveryInProgressException,提示稍后重试
> ForceRecovery
recoverLeaseInternal方法提供了force参数,如果force为true,系统会强制进行Lease-Recovery,具体功能见recoverLease方法的注释即可,如下:
* Immediately revoke the lease of the current lease holder and start lease
* recovery so that the file can be forced to be closed.
force recovery的使用场景下文会有介绍
Recovery机制
recovery是一种容错机制,主要分为block的recovery和lease的recovery,此处不详述,具体可参考下面的链接:
http://blog.cloudera.com/blog/2015/02/understanding-hdfs-recovery-processes-part-1/
二、场景介绍
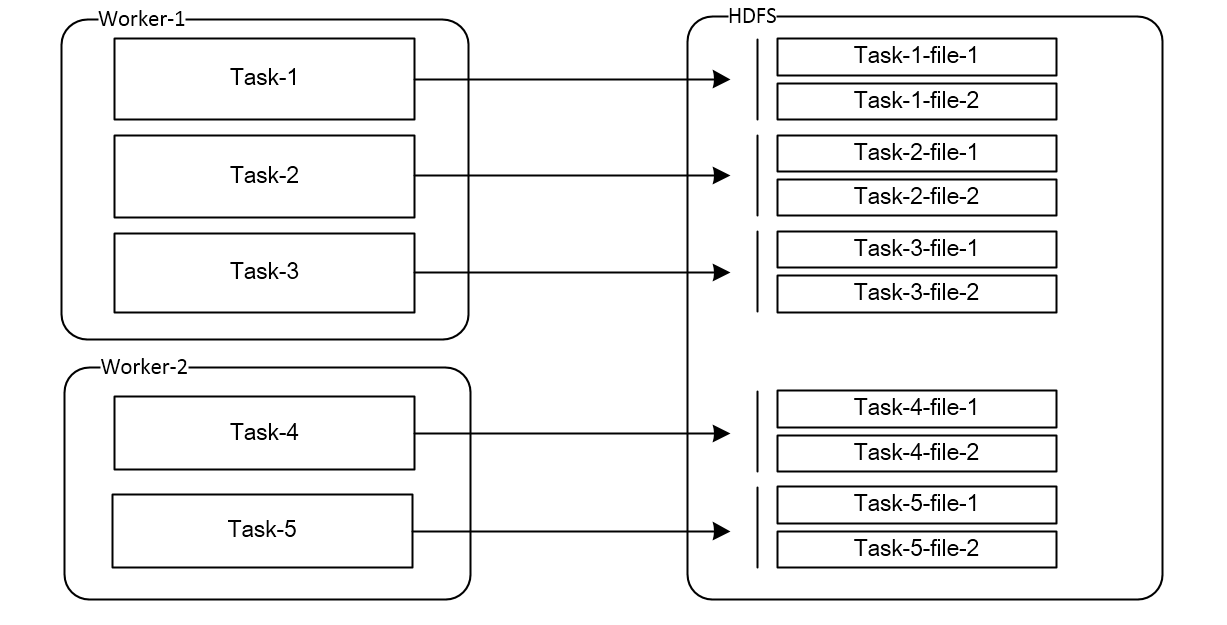
如上图所示,我们的应用场景介绍如下:
* Worker:一个Worker是一个进程,每个Worker负责运行一批Task
* Task:Task负责把抓取到的数据源源不断的实时同步到Hdfs,每个Task负责管理Hdfs中的N个文件(如上图,Task-1在hdfs中对应了Task-1-file-1和Task-1-file-2)
* (Re-)balance:Task和Worker之间的关系是动态的(即:Task在Worker上是平均分配的),当新Worker加入,现有Worker退出、新增Task和删除Task的时候,会触发Rebalance,Task重新分配。比如上图中,增加一个Worker-3,Reblance完成之后的结果为:worker-1运行Task-1和Task-2,worker-2运行Task-3和Task-4,worker-3运行Task-5
三、设计方案
结合租约的特点和我们的场景需求,需要进行针对性的设计,才能避免触发【租约异常】,下面以问答的形式阐述核心设计方案
一个进程内如何同时访问多个hadoop集群?
若要一个进程内同时访问多个hadoop集群,那就需要针对每个集群分别创建各自的FileSystem实例,需要做的有两点:
* 其一:保证针对这多个集群的Configuration实例中的 "fs.defaultFS" 的配置是不同的
* 其二:HADOOP_USER_NAME属性不能通过System.setProperty方法设置,应该调用FileSystem的get方法时动态传入
对文件流应该怎样管理?
Ps:DFSClient是一个进程级实例,即对应同一个hadoop集群,在一个worker进程中只有一个DFSClient
一个文件对应了一个文件流,创建文件流时FSNamesystem会把流对应的path放到Lease中,关闭文件流时FSNamesystem会把流对应的path从Lease中移除,对文件流的管理需要保证以下几个原则
* 其一:流的生命周期应该和Task保持一致,Task运行过程中流随用随创建,Task关闭时把其占有的所有流也关闭,这样才能保证在发生Reblance后,不会出现租约被其它DFSClient占用的问题
* 其二:超时不用的流要及时清理,保证其它使用者有机会获取权限,比如发生日切之后,所有的数据都写到新文件中了,前一天的文件不会再有写入操作,那么应该及时关闭前一天的文件流
如何解决Other-Create问题?
何时会触发Other-Create问题?
其一:Worker宕机,其负责的Task漂移到其它Worker,漂移后的Task便会收到Other-Create异常,只有当超过softLimit之后,异常才会解除,即恢复时间需要1分钟
其二:其它程序原因,如:在发生Reblance时,Task会先被关闭再漂移,如果Task在关闭的过程中流关闭的有问题(比如触发了超时),也可能会触发Other-Create异常
如何应对?
Other-Create异常中包含了other-Dfsclient的IP信息,我们可以调用other-worker提供的接口,远程关闭出问题的流,如果关闭失败或者访问出现超时(宕机的时候会超时),再进行force recovery操作
如何解决Re-Create问题?
流关闭时可能会出现异常,如果出现异常,需要进行force recovery操作,否则的话租约将一直不可释放,一直报Re-Create异常
四、源码解析
【设计方案】部分的描述比较抽象,下面我们结合源码进行更详细的介绍,所有的关键描述都放到了源码注释里,直接看注释即可
package com.ucar.hdfs.lease.demo; import com.ucar.hdfs.lease.demo.stream.FileStreamHolder; import com.ucar.hdfs.lease.demo.stream.FileStreamToken; import com.ucar.hdfs.lease.demo.util.FileLockUtils; import com.ucar.hdfs.lease.demo.util.HdfsConfig; import com.ucar.hdfs.lease.demo.util.RemoteUtil; import org.apache.hadoop.fs.FSDataOutputStream; import java.text.MessageFormat; import java.util.List; import java.util.concurrent.locks.ReentrantLock; /** * 一个Demo类,可以自己写一些单元测试类,验证租约相关的原理 */ public class TaskDemo { private final FileStreamHolder fileStreamHolder; private final HdfsConfig hdfsConfig; private final String filePathPrefix; public TaskDemo(FileStreamHolder fileStreamHolder, HdfsConfig hdfsConfig, String filePathPrefix) { this.fileStreamHolder = fileStreamHolder; this.hdfsConfig = hdfsConfig; this.filePathPrefix = filePathPrefix; } public void start() { fileStreamHolder.start(); } public void stop() { fileStreamHolder.close(); } public void writeData(String fileName, List<String> content) throws Exception { String hdfsFilePath = this.hdfsConfig.getHdfsAddress() + filePathPrefix + fileName + ".txt"; ReentrantLock lock = FileLockUtils.getLock(hdfsFilePath); FileStreamToken fileStreamToken = null; try { lock.lock(); fileStreamToken = fileStreamHolder.getStreamToken(hdfsFilePath, this.hdfsConfig); writeDataInternal(fileStreamToken.getFileStream(), content); } catch (Exception e) { if (fileStreamToken != null) { // 出现异常的时候,必须把流回收一下,否则的话异常会持续不断的报,并且无法自动恢复 // 我们曾经遇到过的根本无法自动恢复的异常有: /* Caused by: java.net.ConnectException: Connection timed out at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) ~[na:1.8.0_121] at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717) ~[na:1.8.0_121] at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) ~[na:na] at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) ~[na:na] at org.apache.hadoop.hdfs.DFSOutputStream.createSocketForPipeline(DFSOutputStream.java:1610) ~[na:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.transfer(DFSOutputStream.java:1123) ~[na:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.addDatanode2ExistingPipeline(DFSOutputStream.java:1112) ~[na:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1253) ~[na:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:594) ~[na:na] */ /* Caused by: java.io.IOException: Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try. (Nodes: current=[xxx:50010, xxx:50010], original=[xxx:50010, xxx:50010]). The current failed datanode replacement policy is DEFAULT, and a client may configure this via 'dfs.client.block.write.replace-datanode-on-failure.policy' in its configuration. at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.findNewDatanode(DFSOutputStream.java:1040) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.addDatanode2ExistingPipeline(DFSOutputStream.java:1106) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1253) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.processDatanodeError(DFSOutputStream.java:1004) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:548) ~[hadoop-hdfs-2.6.3.jar:na] */ /* Caused by: java.net.SocketTimeoutException: 70000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/xxx:36061 remote=/xxx:50010] at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164) ~[hadoop-common-2.6.3.jar:na] at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161) ~[hadoop-common-2.6.3.jar:na] at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131) ~[hadoop-common-2.6.3.jar:na] at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:118) ~[hadoop-common-2.6.3.jar:na] at java.io.FilterInputStream.read(FilterInputStream.java:83) ~[na:1.8.0_121] at java.io.FilterInputStream.read(FilterInputStream.java:83) ~[na:1.8.0_121] at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:2205) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.transfer(DFSOutputStream.java:1142) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.addDatanode2ExistingPipeline(DFSOutputStream.java:1112) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1253) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.processDatanodeError(DFSOutputStream.java:1004) ~[hadoop-hdfs-2.6.3.jar:na] at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:548) ~[hadoop-hdfs-2.6.3.jar:na] */ fileStreamHolder.close(hdfsFilePath); } else { //可能是Other-Create异常,尝试远程关闭 RemoteUtil.tryRemoteClose(hdfsFilePath, e); } throw new RuntimeException(MessageFormat.format("Data Append failed for file - {0}.", hdfsFilePath), e); } finally { if (fileStreamToken != null) { fileStreamToken.setLastUpdateTime(System.currentTimeMillis()); } if (lock != null) { lock.unlock(); } } } private void writeDataInternal(FSDataOutputStream fsOut, List<String> transferData) throws Exception { StringBuffer sb = new StringBuffer(); for (String row : transferData) { sb.append(row); sb.append("\n"); } byte[] bytes = sb.toString().getBytes("UTF-8"); fsOut.write(bytes); fsOut.hsync(); } }
package com.ucar.hdfs.lease.demo.util; import org.apache.hadoop.hdfs.protocol.AlreadyBeingCreatedException; import org.apache.hadoop.ipc.RemoteException; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.regex.Matcher; import java.util.regex.Pattern; public class RemoteUtil { private static final Logger logger = LoggerFactory.getLogger(RemoteUtil.class); private static final String RECREATE_IDENTIFIER = "because this file is already being created by"; public static void tryRemoteClose(String hdfsFilePath, Exception e) { try { if (e instanceof RemoteException) { RemoteException re = (RemoteException) e; String className = re.getClassName(); if (className.equals(AlreadyBeingCreatedException.class.getName()) && e.getMessage().contains(RECREATE_IDENTIFIER)) { logger.info("stream remote close begin for file : " + hdfsFilePath); colseInternal(hdfsFilePath, parseIp(e.getMessage())); logger.info("stream remote close end for file : " + hdfsFilePath); } } } catch (Exception ex) { logger.error("stream remote close failed for file : " + hdfsFilePath, ex); } } static void colseInternal(String hdfsFilePath, String address) { //TODO // 远程调用其它进程,进行流关闭操作 // 此处应该进行更细致的处理 // 1. 如果流关闭失败了,我们也应该执行一下FileSystem的recoverLease方法 // 2. 如果访问超时了,那么应该出现了宕机的情况,虽然通过softLimit会自动恢复,但是如果实时性要求高,应该也执行一下FileSystem的recoverLease方法 // 3. 或者根据自己的场景,压根儿就不远程关闭,强制执行recoverLease方法也行 } private static String parseIp(String message) { Pattern p = Pattern.compile("\\[.*?\\]"); Matcher m = p.matcher(message); String ip = null; while (m.find()) { ip = m.group().replace("[", "").replace("]", ""); } return ip; } }
package com.ucar.hdfs.lease.demo.util; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import java.net.URI; /** * e.g. * * hdfsAddress -> hdfs://hadoop2cluster * zkUrl -> 192.168.0.1,192.168.0.2,192.168.0.3 * zkPort -> 2181 * hadoopUser -> hadoop * haNameNode1 -> namenode01.10101111.com:8020 * haNameNode2 -> namenode02.10101111.com:8020 * hdfsPacketSize -> 20971520 * */ public class HdfsConfig { private volatile String hdfsAddress; private volatile URI hdfsUri; private volatile String zkUrl; private volatile String zkPort; private volatile String hadoopUser; private volatile String haNameNode1; private volatile String haNameNode2; private volatile Long hdfsPacketSize; private volatile Configuration configuration; public HdfsConfig(String hdfsAddress, String zkUrl, String zkPort, String hadoopUser, String haNameNode1, String haNameNode2, long hdfsPacketSize) { this.hdfsAddress = hdfsAddress; this.zkUrl = zkUrl; this.zkPort = zkPort; this.hadoopUser = hadoopUser; this.haNameNode1 = haNameNode1; this.haNameNode2 = haNameNode2; this.hdfsPacketSize = hdfsPacketSize; this.hdfsUri = URI.create(this.hdfsAddress); this.buildConfiguration(); } private void buildConfiguration() { this.configuration = HBaseConfiguration.create(); this.configuration.set("fs.defaultFS", this.hdfsAddress); this.configuration.set("dfs.support.append", "true"); this.configuration.set("hbase.zookeeper.quorum", this.zkUrl); this.configuration.set("hbase.zookeeper.property.clientPort", this.zkPort); this.configuration.set("dfs.client-write-packet-size", String.valueOf(hdfsPacketSize)); // 高可用设置 String key = hdfsUri.getAuthority(); this.configuration.set("dfs.nameservices", key); this.configuration.set(String.format("dfs.ha.namenodes.%s", key), "nn1,nn2"); this.configuration.set(String.format("dfs.namenode.rpc-address.%s.nn1", key), this.haNameNode1); this.configuration.set(String.format("dfs.namenode.rpc-address.%s.nn2", key), this.haNameNode2); this.configuration.set(String.format("dfs.client.failover.proxy.provider.%s", key), "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"); } public String getHdfsAddress() { return hdfsAddress; } public URI getHdfsUri() { return hdfsUri; } public String getZkUrl() { return zkUrl; } public String getZkPort() { return zkPort; } public String getHadoopUser() { return hadoopUser; } public String getHaNameNode1() { return haNameNode1; } public String getHaNameNode2() { return haNameNode2; } public Configuration getConfiguration() { return configuration; } public long getHdfsPacketSize() { return hdfsPacketSize; } }
package com.ucar.hdfs.lease.demo.util; import com.google.common.cache.*; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.ReentrantLock; public class FileLockUtils { private static final Logger logger = LoggerFactory.getLogger(FileLockUtils.class); private static final LoadingCache<String, ReentrantLock> lockCache = CacheBuilder .newBuilder() .expireAfterAccess(24, TimeUnit.HOURS) .removalListener(new RemovalListener<Object, Object>() { @Override public void onRemoval(RemovalNotification<Object, Object> notification) { logger.info(String.format("Lock for [%s] was removed , cause is [%s]", notification.getKey(), notification.getCause()) ); } }) .build(new CacheLoader<String, ReentrantLock>() { @Override public ReentrantLock load(String key) throws Exception { return new ReentrantLock(); } }); public static ReentrantLock getLock(String hdfsFilePath) { return lockCache.getUnchecked(hdfsFilePath); } }
package com.ucar.hdfs.lease.demo.stream; import com.google.common.cache.CacheBuilder; import com.google.common.cache.CacheLoader; import com.google.common.cache.LoadingCache; import com.ucar.hdfs.lease.demo.util.HdfsConfig; import org.apache.hadoop.fs.FileSystem; import java.util.concurrent.TimeUnit; public class FileSystemManager { private static final LoadingCache<HdfsConfig, FileSystem> fileSystemCache = CacheBuilder .newBuilder() .expireAfterAccess(24, TimeUnit.HOURS) .build(new CacheLoader<HdfsConfig, FileSystem>() { @Override public FileSystem load(HdfsConfig hdfsConfig) throws Exception { // FileSystem一共有两个get方法,需要调用这个get方法才能支持"一个进程内同时访问多个hadoop集群" return FileSystem.get( hdfsConfig.getHdfsUri(), hdfsConfig.getConfiguration(), hdfsConfig.getHadoopUser()); } }); public static FileSystem getFileSystem(HdfsConfig hdfsConfig) { return fileSystemCache.getUnchecked(hdfsConfig); } }
package com.ucar.hdfs.lease.demo.stream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hdfs.DistributedFileSystem; public class FileStreamToken { private volatile String pathString; private volatile Path path; private volatile DistributedFileSystem fileSystem; private volatile FSDataOutputStream fileStream; private volatile long lastUpdateTime; public FileStreamToken(String pathString, Path path, DistributedFileSystem fileSystem, FSDataOutputStream fileStream) { this.pathString = pathString; this.path = path; this.fileSystem = fileSystem; this.fileStream = fileStream; this.lastUpdateTime = System.currentTimeMillis(); } public String getPathString() { return pathString; } public void setPathString(String pathString) { this.pathString = pathString; } public Path getPath() { return path; } public void setPath(Path path) { this.path = path; } public DistributedFileSystem getFileSystem() { return fileSystem; } public void setFileSystem(DistributedFileSystem fileSystem) { this.fileSystem = fileSystem; } public FSDataOutputStream getFileStream() { return fileStream; } public void setFileStream(FSDataOutputStream fileStream) { this.fileStream = fileStream; } public long getLastUpdateTime() { return lastUpdateTime; } public void setLastUpdateTime(long lastUpdateTime) { this.lastUpdateTime = lastUpdateTime; } }
package com.ucar.hdfs.lease.demo.stream; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.Set; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; public class FileStreamKeeper { private static final Logger logger = LoggerFactory.getLogger(FileStreamKeeper.class); private static final long CLOSE_CHECK_PERIOD = 60000;// 单位ms private static final long STREAM_LEISURE_LIMIT = 60000;//单位ms private static ScheduledExecutorService executorService; private static List<FileStreamHolder> holders = new ArrayList<>(); //定时关闭不用的流 public static void start() { executorService = Executors.newScheduledThreadPool(1); executorService.scheduleAtFixedRate( FileStreamKeeper::leisureCheck, CLOSE_CHECK_PERIOD, CLOSE_CHECK_PERIOD, TimeUnit.MILLISECONDS ); logger.info("File Stream Keeper is started."); } public static void closeStreamLocal(String hdfsFilePath) { if (holders != null && !holders.isEmpty()) { holders.stream().forEach(h -> { Set<Map.Entry<String, FileStreamToken>> set = h.getTokens().entrySet(); for (Map.Entry<String, FileStreamToken> entry : set) { try { if (hdfsFilePath.equals(entry.getKey())) { h.close(entry.getKey()); return; } } catch (Throwable t) { logger.error("stream close failed for file : " + entry.getKey()); } } }); } } static synchronized void register(FileStreamHolder fileStreamHolder) { holders.add(fileStreamHolder); } static synchronized void unRegister(FileStreamHolder fileStreamHolder) { holders.remove(fileStreamHolder); } private static void leisureCheck() { try { if (holders != null && !holders.isEmpty()) { holders.stream().forEach(h -> { logger.info("timer stream close begin."); Set<Map.Entry<String, FileStreamToken>> set = h.getTokens().entrySet(); for (Map.Entry<String, FileStreamToken> entry : set) { try { FileStreamToken vo = entry.getValue(); if (vo.getLastUpdateTime() + STREAM_LEISURE_LIMIT < System.currentTimeMillis()) { h.close(entry.getKey());//超时关闭 } } catch (Throwable t) { logger.error("timer stream close failed for file : " + entry.getKey()); } } logger.info("timer stream close end."); }); } } catch (Throwable t) { logger.error("something goes wrong when do leisure check.", t); } } }
package com.ucar.hdfs.lease.demo.stream; import com.ucar.hdfs.lease.demo.util.FileLockUtils; import com.ucar.hdfs.lease.demo.util.HdfsConfig; import org.apache.hadoop.fs.CommonConfigurationKeysPublic; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hdfs.DistributedFileSystem; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.locks.ReentrantLock; import java.util.concurrent.locks.ReentrantReadWriteLock; public class FileStreamHolder { private static final Logger logger = LoggerFactory.getLogger(FileStreamHolder.class); private final Map<String, FileStreamToken> tokens; private final ReentrantReadWriteLock readWriteLock; private volatile boolean running; public FileStreamHolder() { this.tokens = new ConcurrentHashMap<>(); this.readWriteLock = new ReentrantReadWriteLock(); } public void start() { this.running = true; FileStreamKeeper.register(this); logger.info("FileStreamHolder is started."); } public void close() { try { this.readWriteLock.writeLock().lock(); this.running = false; if (this.tokens.size() > 0) { this.tokens.keySet().forEach(this::close); } } finally { FileStreamKeeper.unRegister(this); this.readWriteLock.writeLock().unlock(); } logger.info("FileStreamHolder is closed."); } public FileStreamToken getStreamToken(String pathString, HdfsConfig hdfsConfig) throws Exception { try { this.readWriteLock.readLock().lock(); if (!running) { throw new RuntimeException("FileStreamHolder has closed, StreamToken gotten failed."); } return getStreamTokenInternal(pathString, hdfsConfig); } finally { this.readWriteLock.readLock().unlock(); } } private FileStreamToken getStreamTokenInternal(String pathString, HdfsConfig hdfsConfig) throws Exception { DistributedFileSystem hadoopFS = (DistributedFileSystem) FileSystemManager.getFileSystem(hdfsConfig); ReentrantLock lock = FileLockUtils.getLock(pathString); try { lock.lock(); FileStreamToken token = tokens.get(pathString); if (token == null) { FSDataOutputStream fileStream; Path path = new Path(pathString); if (!hadoopFS.exists(path)) {
//create方法最终会调用server端FSNamesystem的startFile方法 fileStream = hadoopFS.create(path, false, hdfsConfig.getConfiguration().getInt(CommonConfigurationKeysPublic.IO_FILE_BUFFER_SIZE_KEY, CommonConfigurationKeysPublic.IO_FILE_BUFFER_SIZE_DEFAULT), (short) 3, 64 * 1024 * 1024L); logger.info("stream create succeeded for file : " + pathString); } else {
//append方法最终会调用server端FSNamesystem的appendFile方法 fileStream = hadoopFS.append(path); logger.info("stream append succeeded for file : " + pathString); } token = new FileStreamToken(pathString, path, hadoopFS, fileStream); tokens.put(pathString, token); } return token; } finally { lock.unlock(); } } public void close(String pathString) { ReentrantLock lock = FileLockUtils.getLock(pathString); try { lock.lock(); FileStreamToken vo = tokens.get(pathString); if (vo != null) { try { vo.getFileStream().close(); logger.info("stream close succeeded for file : " + pathString); } catch (Throwable e) { logger.error("stream close failed for file : " + pathString, e); try { //流关闭失败的时候,必须执行一下recoverLease方法(即:force recovery) //出现异常,流肯定不能接着用了,我们也不知道服务端究竟有没有感知到关闭操作 //如果没有感知到close动作,租约一直没有被release,将导致Re-Create问题 vo.getFileSystem().recoverLease(vo.getPath()); logger.info("lease recover succeeded for file : " + pathString); } catch (Exception ex) { logger.error("lease recover failed for file : " + pathString, ex); } } finally { //不管有没有异常,我们都需要进行remove //没有异常,说明流关闭成功(严格意义上讲,没有异常也不代表流关闭成功了,假设第一次关的时候出异常了,没有进行处理,随后再次执行close,就不会报异常,具体可参考流的close方法),正常remove没有问题 //有异常,说明流关闭失败,关了一半儿,流已经有问题了,不能再用了,必须remove掉,不remove的话,后续接着用会报ClosedChannelException异常 /*Caused by: java.nio.channels.ClosedChannelException at org.apache.hadoop.hdfs.DFSOutputStream.checkClosed(DFSOutputStream.java:1622) at org.apache.hadoop.fs.FSOutputSummer.write(FSOutputSummer.java:104) at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:58) at java.io.DataOutputStream.write(DataOutputStream.java:107) at java.io.FilterOutputStream.write(FilterOutputStream.java:97) at com.ucar.datalink.writer.hdfs.handle.RdbEventRecordHandler.writeData(RdbEventRecordHandler.java:246) at com.ucar.datalink.writer.hdfs.handle.RdbEventRecordHandler.doWriteData(RdbEventRecordHandler.java:221) at com.ucar.datalink.writer.hdfs.handle.RdbEventRecordHandler.toWriteData(RdbEventRecordHandler.java:187)*/ tokens.remove(pathString); } } } finally { if (lock != null) { lock.unlock(); } } } Map<String, FileStreamToken> getTokens() { return tokens; } }
五、参考资料
http://blog.csdn.net/androidlushangderen/article/details/48012001
https://www.tuicool.com/articles/meuuaqU
https://www.tuicool.com/articles/IJjq6v
http://blog.cloudera.com/blog/2015/02/understanding-hdfs-recovery-processes-part-1/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号