40.项目案例之利用爬虫技术获取需要帐号密码登录的网页中的数据
近期公司需要开发一个能够读取设备内部网页信息,我想到了用爬虫的方法来获取相关数据,具体代码如下:
#!/usr/bin/env python3 # -*- coding: UTF-8 -*- import requests import time class GetData(): # 初始化变量 def __init__(self, url): self.url = url # 要用帐号密码登录,首先需要在先通过浏览器登录网页,然后在浏览器中查看Cookie值,将其放在请求头中 self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0", "Cookie": "user_choose=block" } self.login() # 首先先用Session方法来登录网页 self.get_data() # 登录完成后,我们就可以去登录里面其它的网址了 # 登录主页,将Cookie写入session对象中 def login(self): self.session = requests.Session() response = self.session.get(self.url, headers=self.headers) # 用session对象的post来获取Ajax接口数据 def get_data(self): get_url = "http://192.168.1.12/boafrm/formCpReportMonitor" resp = self.session.post(get_url, headers=self.headers) text = resp.text return text if __name__ == '__main__': while True: main_url = 'http://192.168.1.12/index/index.htm' data = GetData(main_url) print('-'*50) print(data.get_data()) time.sleep(1)
要完成上面程序正常运行:
1.首先,我们需要用帐号密码来完成正常的登录操作,登录完成后在浏览器中找到Cookie信息:

2.然后,然后将该cookie信息放在程序的请求头headers中:
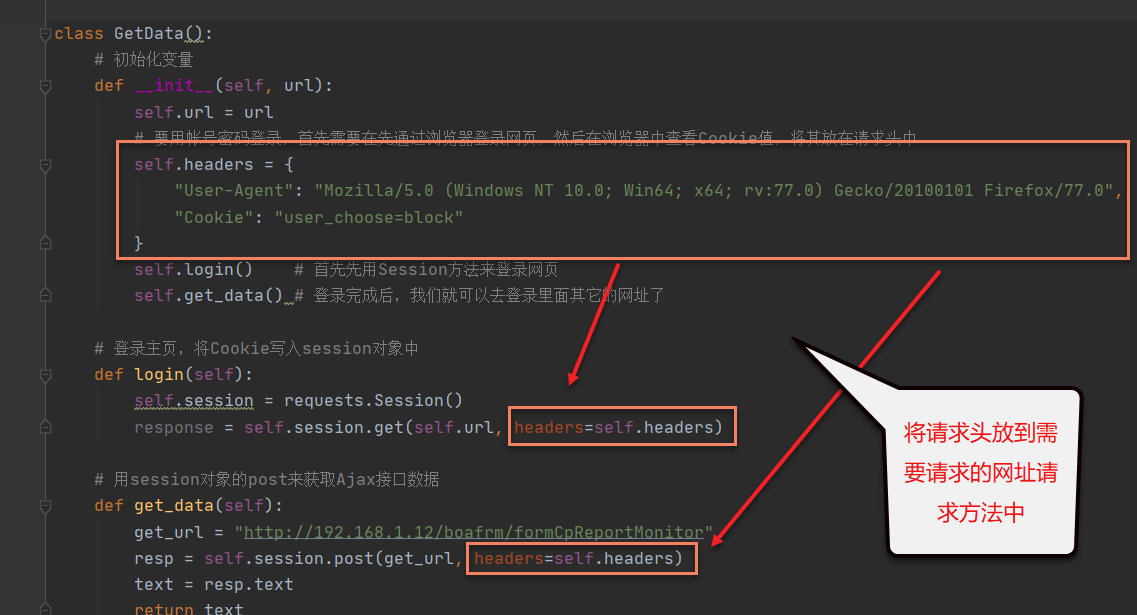
3.由于我们登录的网站是用GET请求的,所以我们代码中也需要用get请求,并且首次请求时,我们需要带请求头访问,所以我们用requests.Session()中的get来访问。
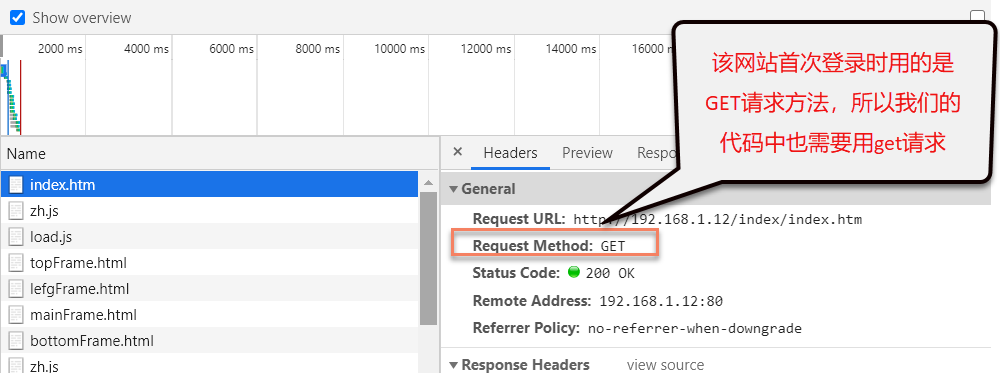
4.最后,由于我发现需要获取的数据是动态实时数据,所以是用了Ajax,那我就找那个利用Ajax技术的网址接口,我是这要查找的,用浏览器中的箭头工具在网页中查找对应的超链接文本,然后在下面的代码中会定位到相应的代码,在该代码中就可以找到对应的网页,然后打开该网页,再按F12,在浏览器下面的工具中可以看到实时刷新的网址,此时,我们点击最下面的一个,然后看右侧的请求头,
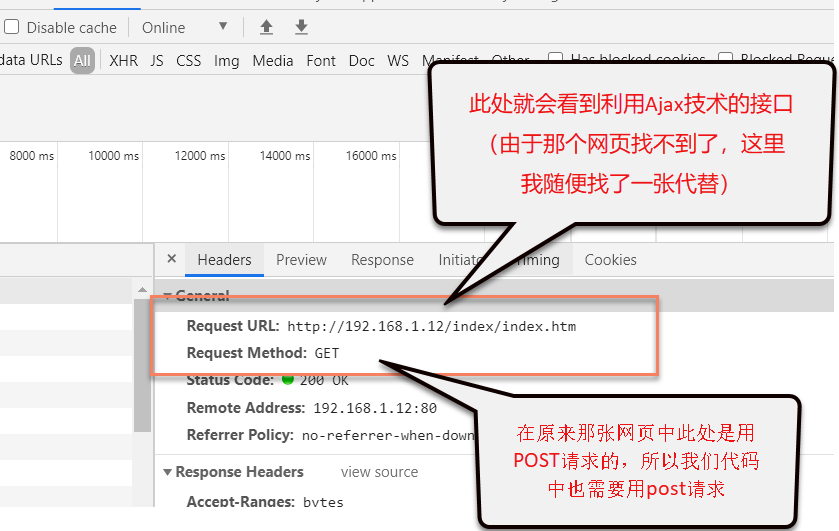

按以上方法就能正确抓取到需要的数据了。
如有问题可以添加如下公众号进行交流。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号