

Atomic底层原理
JDK提供了一些原子操作的类,在java.util.concurrent.atomic下面。如AtomicBoolean,AtomicInteger,AtomicLong都是用原子的方式来更新指定类型的值。
Unsafe类包含了大量多的对C代码的操作,包括了很多直接内存分配和原子操作的调用,都存在安全隐患,所以标记为unsafe。
AtomicInteger是一个标准的乐观锁实现,sun.minc.Unsafe是JDK提供的乐观锁的支持
为什么需要Atomic类?
实例代码
public class Dome01 {
private Integer count = 0;
private static int min = 10;//每次加10次
private static int max = 100;//有100个线程同时加
public Integer getCount() {
return count;
}
public void addCount(){
for (int i = 0; i < min; i++) {
count++;
}
}
@Test
public void testInteger(){
Long temp = System.currentTimeMillis();
Dome01 dome01 = new Dome01();
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < max; i++) {
executorService.execute(()->{
dome01.addCount();
});
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("testInteger --- >"+dome01.getCount() +"---- 执行时间 ---- "+(System.currentTimeMillis() - temp));
executorService.shutdown();
}
}
执行结果:每次都不一样,往往达不到预期想要的值,而且并发量越大相差的越远。
我们可以看出Integer类型的count在高并发的情况并不能保证线程安全。我们一共执行了1000次,但结果往往是一个小于1000的值。原因在于count++并不是一个原子性操作(读取--运算--赋值)。
如何解决
加锁
synchronized
Lock lock = new ReentrantLock();
public synchronized void addCount(){
for (int i = 0; i < min; i++) {
count++;
}
}
既然是因为count++不是原子操作造成的,那么最容易想到的就是使用synchronized对方法进行加锁,但是我只想保证count++是原子操作,使用synchronized有种高射炮打蚊子的感觉。
ReentrantLock
Lock lock = new ReentrantLock();
public void addCount(){
for (int i = 0; i < min; i++) {
lock.lock();
count++;
lock.unlock();
}
}
进一步优化,只对count++操作进行加锁,但是虽然比synchronized性能要好些,但是还有一种杀鸡用牛刀的感觉。
使用CAS
虽然使用synchronized和ReentrantLock都可以解决这个问题,但是总是感觉不够理想,于是引入了CAS。
什么是CAS
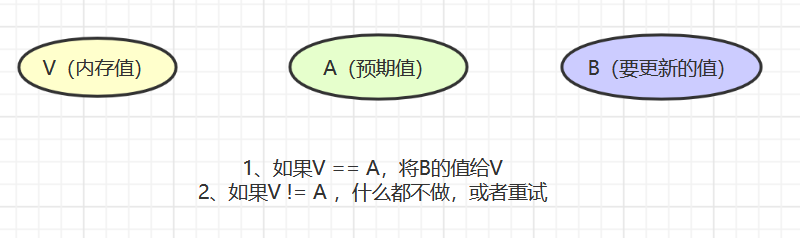
CAS是一种乐观锁实现,有三个值 V 表示当前内存的值、A 表示预期的旧值、 B 表示将要更新的新值。
CAS的核心原理在于当要更新值得时候就进行compareAndSwap,而这个compareAndSwap操作是一个native方法,底层是用C/C++写的。最终调用的是cmpxchg方法,其保证了CAS操作的原子性。
compxchg(&a,a,b);//调用compxchg函数
//伪代码
bool cmpxchg(int *v,int a,int b){
lock();
if(*v == a){
*v = b;
return true;
}else{//也可以进行自旋
return false;
}
unlock();
}
以上是个人猜测的cmpxchg函数的实现,不然的话,根本无法保证线程安全
假设在多线程环境下,有A,B两个线程同时执行了第一行。同时调用了compxchg(&a,a=10,b=20),由于加了lock只有个线程能执行,线程A判断 if(*v(10) == a(10))成功,然后将*v值修改为20,线程A执行结束释放lock;线程B进入开始执行判断 if(*v(20)==a(10))失败。这样既保证了cas操作的原子性,又保证了线程安全。由于Java没有指针这个函数用Java是实现不了的,这就是C语言的魅力。
CAS解决
现在可以使用CAS来轻量级的解决上面问题。很多复杂的直接对内存的操作Java做不到的,不过JDK提供了一个Unsafe包,里面分装了很多强大的操作。
到此就很优雅的解决了上面提到的count++非原子性的,为了避免重复造轮子,所以JDK将这些CAS操作都分装到了Atomic类中了。
Atomic类有哪些?
Atomic类都放在java.util.concurrent.atomic下面的,如图:前面12个是JDK8之前的,后面5个是JDK8之后的。

基本类型
使用原子的方式更新基本类型
- AtomicInteger:整形原子类
- AtomicLong:长整形原子类
- AtomicBoolean:布尔原子类
数组类型
使用原子的方式更新数组中某个元素
- AtomicIntegerArray:整形数组原子类
- AtomicLongArray:长整形数组原子类
- AtomicReferenceArray:引用类型数组原子类(数组中存放对象)
引用类型
使用原子的方式更新某个对象
- AtomicReference:引用类型原子类
- AtomicStampedReference:AtomicReference的扩展版,增加了一个参数stamp标记,这里是为了解决了AtomicInteger和AtomicLong的操作会出现ABA问题。
- AtomicMarkableReference :与AtomicStampedReference差不多,只不过第二个参数不是用的int作为标志,而用boolean类型做标记
对象的属性修改类型
使用原子的方式更新某个类中某个字段
- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
- AtomicReferenceFieldUpdater:原子更新引用类型字段的更新器
LongAdder
是什么?
LongAdder同样是原子类,AtomicInteger在高并发场景下,会大量自旋带来性能浪费,于是引入了LongAdder类,解决大量自旋的问题。
原理是什么?
由于AtomicInteger类在高并发场景下,会有大量线程要修改同一个值,但同一时刻只有一个线程可以修改成功。其他线程就会自旋来等待。当有大量自旋操作时,是对CPU资源的一种浪费。
LongAdder内部维护了一个Call[]数组,将核心的数据vulue分离到数组的各个位置,每个线程访问时,通过哈希等算法映射到其中一个数字进行运算。而最终的运算结果,则是对Call[]数组中的所有值进行累加求和
总的来说,就是将一个值,分散为不同的值,在并发的时候可以分散压力,在高并发下,可以减少自旋次数,可以显著的提升性能。
ABA问题
举个通俗点的例子,你倒了一杯水放桌子上,干了点别的事,然后同事把你水喝了,然后觉得不太好,又给你重新倒了一杯水,你回来看水还在,拿起来就喝,如果你不管水中间被人喝过,只关心水还在,这就是ABA问题。
如何解决ABA问题
可以加一个版本号,每次修改的时候版本号加一,这样就不存ABA的问题了,我在更新之前,除了要确保值没有被修改还要确保版本号没被修改。
思考
我引入了版本号之后,还有必要判断值是原来的值吗?直接根据版本号不就知道了值有木有修改了吗?
个人想法
我们的本意是修改值,重点在于保证值得正确修改,如果把注意点偏移到版本号上,有本末倒置的嫌疑。而且若真的要根据版本号来判断值是否被修改,还需要维护版本号更新的安全性。

