
数据的分布和映射
数据的分布和映射是数据分析中的两个重要概念。它们帮助我们理解数据的特征,并为后续的数据处理和分析提供基础。
数据的分布
定义:数据的分布描述了数据集中每个值出现的频率或概率。它提供了数据集的形状、中心趋势和离散程度的信息。
目的:通过分析数据的分布,我们可以了解数据的特征,比如数据是否对称、是否有异常值、数据的集中趋势等。
常见分布类型:
- 离散分布:数据只能取特定的、可数的值。例如,抛掷一个骰子的结果就是一个离散分布,可能的值是1、2、3、4、5和6。
- 连续分布:数据可以取一个区间内的任何值。例如,人的身高或体重就是连续分布,因为它们可以取无限多的值。
常见的数据分布:
- 均匀分布:每个值出现的概率相同。

- 二项分布:描述了在固定次数的独立实验中成功次数的分布,每次实验有两种可能的结果。

- 正态分布:也称为高斯分布,是一种对称的、钟形的连续分布,其均值、中位数和众数相同。

- 指数分布:描述了在泊松过程中事件之间的时间间隔。

- 泊松分布:描述了在固定的时间或空间间隔内事件发生的次数。

数据映射
数据映射是将数据从一个格式或结构转换到另一个格式或结构的过程。它在数据集成、数据迁移、ETL(提取、转换、加载)等场景中起着至关重要的作用。
在数据映射中,源数据和目标数据之间的对应关系被明确定义。源数据是原始数据集,而目标数据是转换后的数据集。映射规则指定了如何从源数据字段提取值,并将其转换为适合目标数据模型的格式。
数据映射通常涉及以下几个步骤:
- 识别源和目标数据结构:首先,需要明确源数据和目标数据的结构和格式。这包括数据类型、字段名称、数据长度等。
- 定义映射规则:根据源和目标数据结构,定义映射规则。这些规则指定了如何从源数据字段提取数据,并将其转换为目标数据字段。
- 数据转换:应用映射规则,将源数据转换为目标数据格式。这可能涉及数据类型转换、数据清洗、数据合并等操作。
- 验证和测试:在数据映射完成后,进行验证和测试以确保数据正确转换,并满足目标数据模型的要求。
常见的数据映射方法:
- 数据清洗:去除或纠正数据集中的错误、不一致或不完整的数据。
- 数据转换:将数据从一种格式或结构转换为另一种,例如,将非结构化数据转换为结构化数据。
- 归一化:将数据缩放到一个特定的范围,通常是0到1,以便于比较和处理。
- 标准化:将数据转换为具有特定均值和标准差的分布,通常是均值为0,标准差为1的正态分布。
数据映射的工具和技术包括手动编码、使用数据映射软件、或者利用ETL工具等。手动编码适合简单的数据映射任务,而数据映射软件和ETL工具提供了更高级的功能,如图形界面、自动化处理等,以应对复杂的映射需求。
总之,数据映射是确保数据在不同系统和格式之间正确转换的关键步骤,它直接影响数据的一致性、完整性和可用性。
以下是对医疗花费预测的数据分布和映射
代码说明
-
导入库:
import pandas as pd import matplotlib.pyplot as plt import seaborn as snspandas用于数据处理和分析。matplotlib.pyplot用于绘制基本图形。seaborn是基于matplotlib的高级可视化库,提供更美观的图表。
-
读取CSV文件:
train_df = pd.read_csv('D:/迅雷下载/第6章 医疗花费预测(1)/第6章 医疗花费预测/train.csv') test_df = pd.read_csv('D:/迅雷下载/第6章 医疗花费预测(1)/第6章 医疗花费预测/test.csv')- 使用
pd.read_csv读取训练和测试数据集。
- 使用
-
查看数据结构:
print("Train Data Head:") print(train_df.head()) print("\nTest Data Head:") print(test_df.head())- 打印数据集的前几行,以便了解数据的结构和内容。
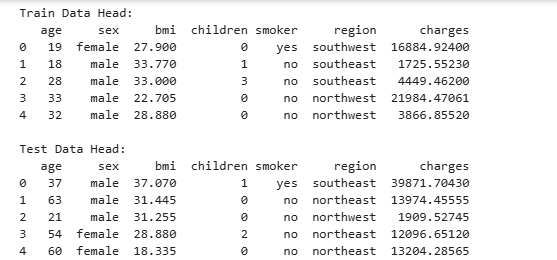
- 打印数据集的前几行,以便了解数据的结构和内容。
-
绘制年龄分布图:
plt.figure(figsize=(10, 6)) sns.histplot(train_df['age'], bins=20, kde=True) plt.title('Age Distribution') plt.xlabel('Age') plt.ylabel('Frequency') plt.show()- 使用
seaborn的histplot绘制年龄的直方图,并添加核密度估计(KDE)曲线。
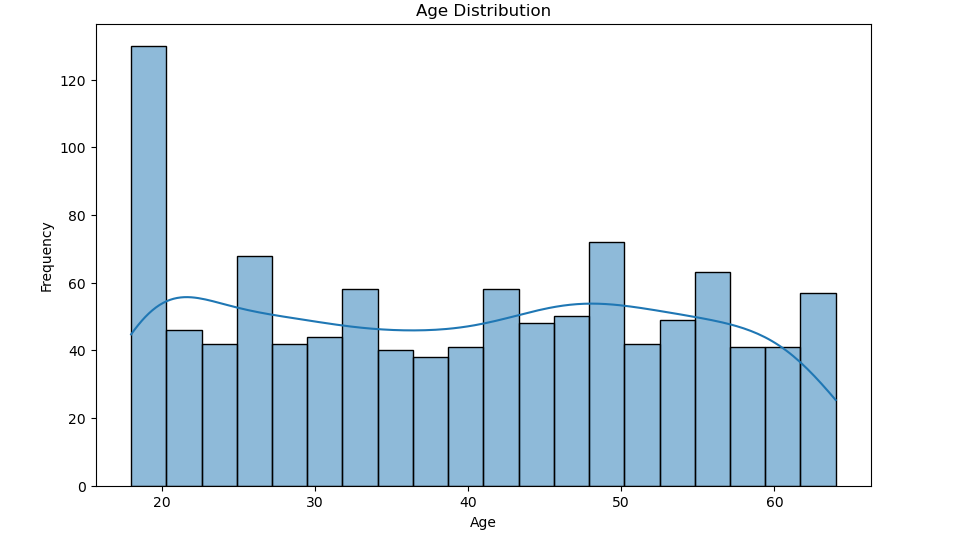
- 使用
-
绘制BMI分布图:
plt.figure(figsize=(10, 6)) sns.histplot(train_df['bmi'], bins=20, kde=True) plt.title('BMI Distribution') plt.xlabel('BMI') plt.ylabel('Frequency') plt.show()- 同样的方法绘制BMI的分布图。
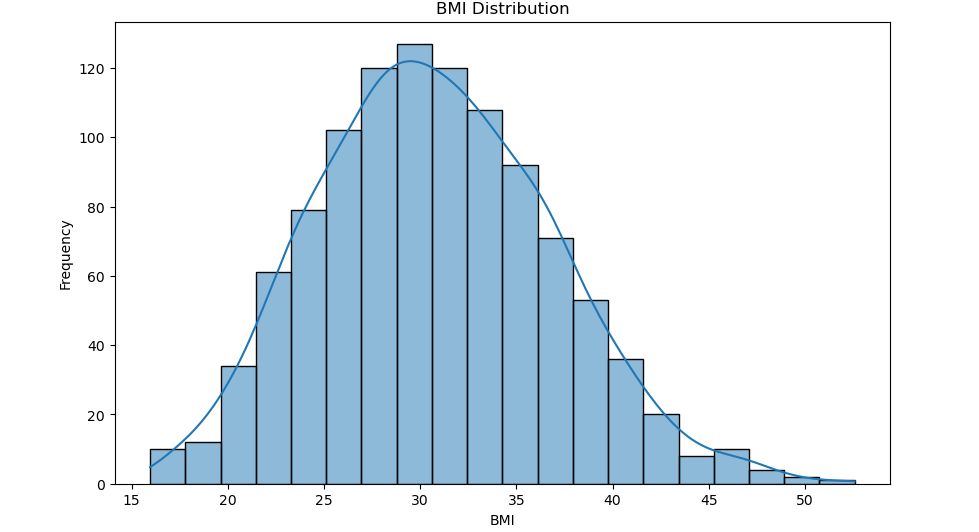
- 同样的方法绘制BMI的分布图。
-
绘制费用分布图:
plt.figure(figsize=(10, 6)) sns.histplot(train_df['charges'], bins=20, kde=True) plt.title('Charges Distribution') plt.xlabel('Charges') plt.ylabel('Frequency') plt.show()- 绘制医疗费用的分布图。
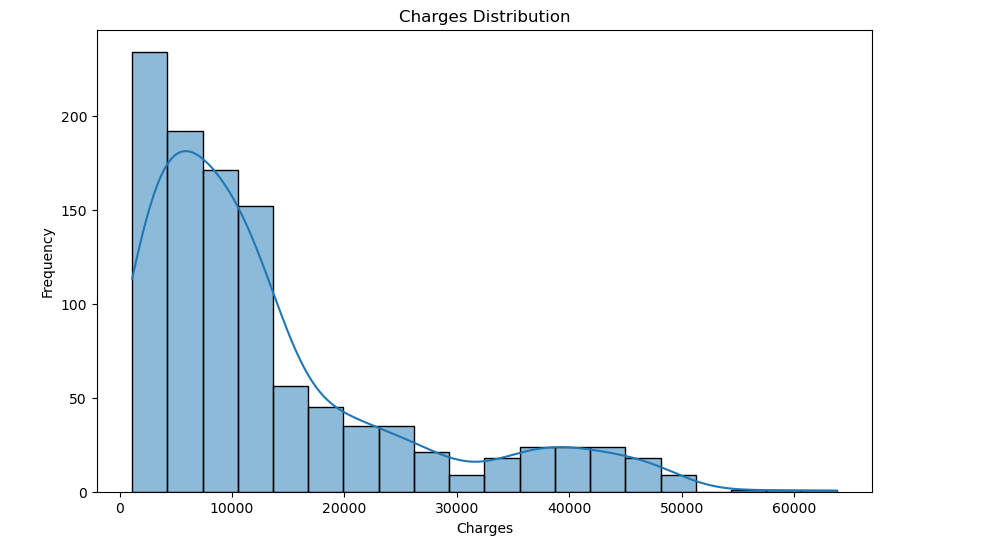
- 绘制医疗费用的分布图。
-
数据映射:
train_df['sex'] = train_df['sex'].map({'male': 0, 'female': 1}) test_df['sex'] = test_df['sex'].map({'male': 0, 'female': 1}) train_df['smoker'] = train_df['smoker'].map({'yes': 1, 'no': 0}) test_df['smoker'] = test_df['smoker'].map({'yes': 1, 'no': 0}) region_mapping = {'northeast': 0, 'northwest': 1, 'southeast': 2, 'southwest': 3} train_df['region'] = train_df['region'].map(region_mapping) test_df['region'] = test_df['region'].map(region_mapping)- 将性别、吸烟状态和区域信息映射为数值,以便后续分析和建模。
-
查看映射后的数据:
print("\nTrain Data Head (After Mapping):") print(train_df.head()) print("\nTest Data Head (After Mapping):") print(test_df.head())- 打印映射后的数据集前几行以确认映射成功。

- 打印映射后的数据集前几行以确认映射成功。
-
绘制性别分布图:
plt.figure(figsize=(10, 6)) sns.countplot(x='sex', data=train_df) plt.title('Sex Distribution') plt.xlabel('Sex (0: Male, 1: Female)') plt.ylabel('Count') plt.show()- 使用
countplot绘制性别的分布图。
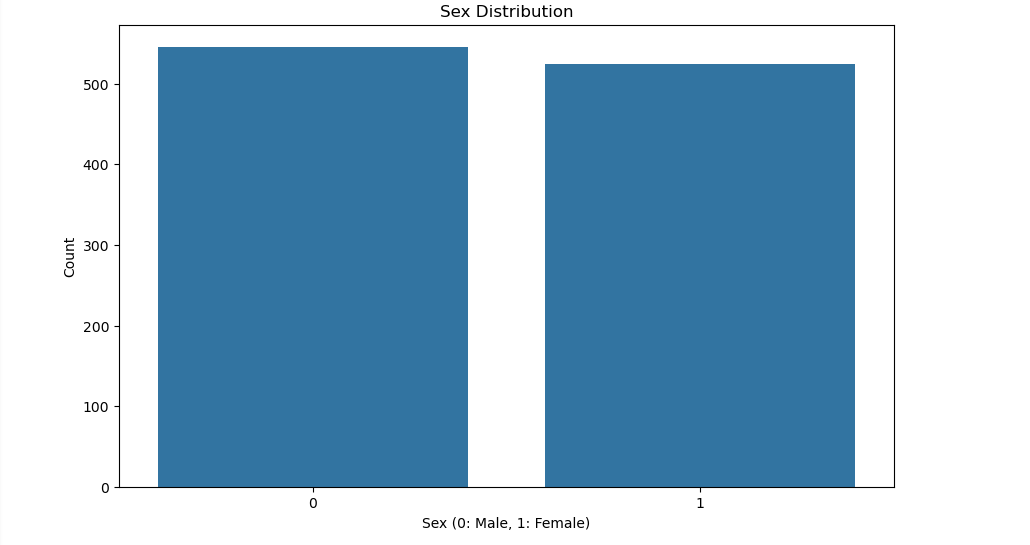
- 使用
-
绘制吸烟状态分布图:
plt.figure(figsize=(10, 6)) sns.countplot(x='smoker', data=train_df) plt.title('Smoker Distribution') plt.xlabel('Smoker (0: No, 1: Yes)') plt.ylabel('Count') plt.show()- 绘制吸烟状态的分布图。
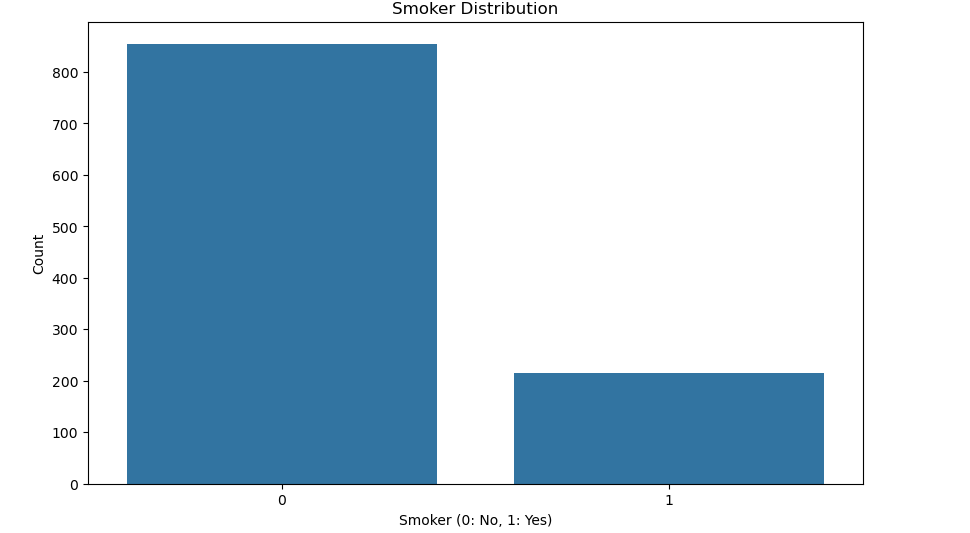
- 绘制吸烟状态的分布图。
-
绘制区域分布图:
plt.figure(figsize=(10, 6)) sns.countplot(x='region', data=train_df) plt.title('Region Distribution') plt.xlabel('Region (0: Northeast, 1: Northwest, 2: Southeast, 3: Southwest)') plt.ylabel('Count') plt.show()- 绘制不同区域的分布图。

这个示例展示了如何使用Python进行数据分析与可视化,涵盖了数据读取、数据结构查看、数据分布分析和数据映射等步骤。通过这些可视化图表,可以更直观地理解数据的特征和分布情况,为后续的分析和建模打下基础。
- 绘制不同区域的分布图。
总结
数据的分布和映射是处理和分析数据的基础。理解数据的分布可以帮助我们更好地理解数据的特性,而数据的映射则确保数据以适合分析的形式存在。通过这些步骤,我们可以更有效地进行数据分析或构建机器学习模型。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?