
使用Urllib(2)--浏览器伪装
- 由上一个爬取到内存中的例子爬取京东的标题,轻而易举的就爬下来了,接下来我们将网址换一个例如:https://www.qiushibaike.com/
-
import urllib.request import re #ignore小细节自动略过,大大减少出错率 #将数据爬到内存中 #http://www.jd.com url = "https://www.qiushibaike.com/" data = urllib.request.urlopen(url).read().decode("utf-8","ignore") pat = "<title>(.*?)</title>" #re.S模式修正符,网页数据往往是多行的,避免多行的影响 print(re.compile(pat,re.S).findall(data))
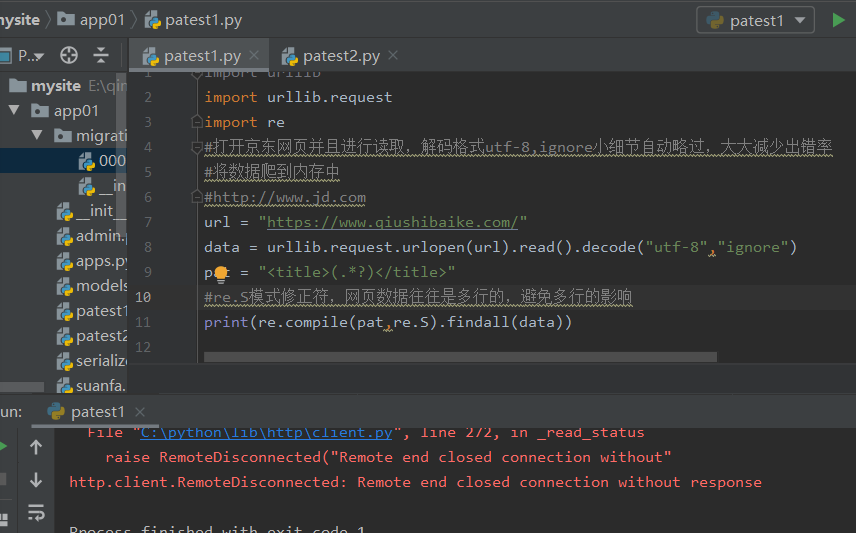
- 报错信息表示:远程关闭了我们的链接,有可能IP被封了,也有可能爬虫被识别了(这是大多数)
-
- 浏览器伪装
- 上述报错信息,而后用浏览器还能进行浏览,这就证明我们的IP没有被封,如果想要继续访问,我们就可以进行浏览器伪装,对方看你是不是浏览器,如果是通过
-
import urllib.request import re #浏览器伪装 #建立opener对象,opener可以进行设置 opener = urllib.request.build_opener() #构建元祖User-Agent,键值 UA = ("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36") #将其放入addheaders属性中 opener.addheaders = [UA] #将opener安装为全局 urllib.request.install_opener(opener) url = "http://www.qiushibaike.com" pat = "<title>(.*?)</title>" data = urllib.request.urlopen(url).read().decode("utf-8","ignore") print(re.compile(pat,re.S).findall(data))

本文来自博客园,作者:手可摘星辰/*,转载请注明原文链接:https://www.cnblogs.com/u-damowang1/p/12724245.html

