用Elasticsearch做大规模数据的多字段、多类型索引检索
本文同时发布在我的个人博客
之前尝试了用mysql做大规模数据的检索优化,可以看到单字段检索的情况下,是可以通过各种手段做到各种类型索引快速检索的,那是一种相对简单的场景。
但是实际应用往往会复杂一些 —— 各类索引(关键词匹配、全文检索、时间范围)混合使用,还有排序的需求。这种情况下mysql就有点力不从心了,复杂的索引类型,在多索引检索的时候对每个字段单独建索引于事无补,而联合索引无法在如此复杂的索引类型下建起来。
用ElasticSearch来解决这个场景的问题就要简单的多了。那么如何用elastic来解决这个问题呢? 还是带着业务需求来实践一遍吧:
①检索字段有7个,4个关键词匹配,1个特殊要求的a=b&c=d的分段全文检索,1个中文全文检索,1个时间范围
②数据量很大,需要支持3个月数据的检索,最好能按月建索引,方便冷备、恢复
1. ElasticSearch Demo Server/Client 环境搭建
为了快速学习elasticsearch的api,可以在本地快速搭建一个demo环境
1.1 elasticsearch server
step1.安装jdk1.8
https://www.oracle.com/technetwork/java/javase/downloads/index.html 官网下载安装、配置好环境变量即可
step2.安装elasticsearch
https://www.elastic.co/cn/downloads/elasticsearch 同样的,官网下载对应平台的包,这个甚至不需要,直接加压,就可以在bin目录下看到服务的启动文件
我使用的是windows平台版本的,运行bin目录下elasticsearch.bat,稍等片刻,访问 http://localhost:9200
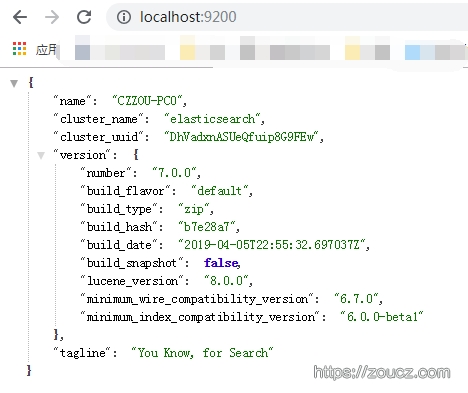
看到此截图说明elasticsearch demo server启动成功。
step3.安装中文分词器
文章开头的需求中提到,有需要中文分词全文索引的字段,所以需要额外安装一下中文分词器。
https://github.com/medcl/elasticsearch-analysis-ik/tree/v7.0.0 上官网下载对应elasticsearch版本tag的ik源码包,比如我使用的最新版本7.0.0,ik也需要下载对应版本的。
elasticsearh是用java写的,需要安装maven以编译此项目。http://maven.apache.org/download.cgi官网下载对应平台的安装包,编译或解压,配置好环境变量。
解压ik代码压缩包,在其根目录运行mvn clean && mvn compile && mvn package,编译打包
将target/releasa下生成的编译好的文件,解压到elasticsearch/plugin/ik目录下,重启elasticsearch,启动成功则说明安装成功(或者直接在github下载对应的release版本)。ik分词器没办法直接测试,需要先建好index,再在index下的分词器中测试,在后文进行。
1.2 elasticsearch client
elasticsearch server以http协议接口的方式提供服务,官方提供了客户端的nodejs sdk :https://github.com/elastic/elasticsearch-js,文档在这里https://www.elastic.co/guide/en/elasticsearch/client/javascript-api/current/api-reference.html#_index
用法这里先不赘述。
2.ElasticSearch使用
正如官网所说,elasticsearch是一个简单的引擎,同时也是一个复杂的引擎,提供不同级别的配置以实现不同复杂度的需求。网上elastic入门的文章,大多以比较简单的方式介绍入门级别的使用,但是真正用到产品中的时候,还是要思考一些问题: 如何配置索引字段、如何发起检索请求、如何添加额外配置。带着这些问题通读一遍官网文档,再来真正使用它,相对来说是比较好一点的。
2.1创建Index
写入数据之前,首先得考虑如何创建各种不同类型的index,以满足分词、检索、排序、统计的需求,官方文档对这块的描述在这里:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html,真正开始创建index之前,推荐把mapping的文档通读一遍,这样才知道如何选择合适的type。
2.1.1 Keyword类型字段
首先是4个关键词索引的字段,比较简单,直接创建keyword类型的property就可以了:
const { Client } = require('@elastic/elasticsearch')
const client = new Client({ node: 'http://localhost:9200' })
client.indices.create({
index: "asrtest1",
include_type_name: false,
body:{
"mappings" : {
"properties" : {
"id" : { "type" : "keyword" },
"app_key" : { "type" : "keyword" },
"guid" : { "type" : "keyword" },
"one_shot" : { "type" : "keyword" }
}
}
}
}).then((data)=>{
console.log("index create success:")
}).catch((err)=>{
console.error("index create error:", err)
})
2.1.2 Date类型字段
然后是1个日期字段,这里日期的格式是格式化后的 2019-04-15 14:54:01或者毫秒数,参考mapping文档中date类型字段的说明,向上面创建的index中插入date类型的字段,并指定字段的格式化方法:
client.indices.putMapping({
index: "asrtest1",
include_type_name: false,
body:{
"properties" : {
"log_time" : {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
}
}).then((data)=>{
console.log("add success:", data)
}).catch((err)=>{
console.error("add error:", err)
})
2.1.3 自定义分词Text类型字段
然后是1个特殊要求的a=b&c=d的分段全文检索, 为了达到这个目标,我们需要使用一个分词器,仅使用&分词。
这里需要参考两处文档,一处是mapping文档中text类型字段说明,另一处是整个analysis部分的文档(描述了分词器的组成部分、工作原理、如何自定义分词器等)
一个analyzer由Character Filters、Tokenizers、Token Filters三部分组成,我们可以自己实现一个自定义分词器toenizer用于此需求,也可以直接使用内置的pattern analyzer,两者没啥区别,这里图简单就用一下内置的Pattern Analyzer:
//1. 关闭asrtest1index
client.indices.close({index:"asrtest1"}).then(function () {
//2. 为index添加pattern analyzer
return client.indices.putSettings({
index: "asrtest1",
body:{
"analysis": {
"analyzer": {
"qua_analyzer": {
"type": "pattern",
"pattern": "&"
}
}
}
}
})
}).then(()=>{
//3. 为index添加text类型的qua字段,并应用pattern analyzer
return client.indices.putMapping({
index: "asrtest1",
include_type_name: false,
body:{
"properties" : {
"qua" : {
"type": "text",
"analyzer": "qua_analyzer",
"search_analyzer":"qua_analyzer"
}
}
}
})
}).then(()=>{
//4. 打开asrtest1
return client.indices.open({index:"asrtest1"})
}).then(()=>{
console.log("add qua success")
}).catch((err)=>{
console.error("add error:", err.message, err.meta.body)
})
这里有个小插曲,直接putSettings的时候,报这个错,所以上面的代码中先关闭index,再添加,再open

至此自定义分词的qua字段添加完毕,好了,测试一下:
client.indices.analyze({
"index":"asrtest1",
"body":{
"analyzer" : "qua_analyzer",
"text" : "a=b&c=d&e=f&g=h"
}
}).then((data)=>{
console.log("analyzer run success:", data.body.tokens)
}).catch((err)=>{
console.error("analyzer run error:", err)
})
[{token:'a=b',start_offset:0,end_offset:3,type:'word',position:0},
{token:'c=d',start_offset:4,end_offset:7,type:'word',position:1},
{token:'e=f',start_offset:8,end_offset:11,type:'word',position:2},
{token:'g=h',start_offset:12,end_offset:15,type:'word',position:3}]
结果是符合预期的。
2.1.3 中文分词Text类型字段
elasticsearch通过插件的形式来支持中文分词,在1.1小节中,我们已经安装了elasticsearch提供的中文分词插件,现在来应用并测试一下。
添加text中文分词字段:
client.indices.putMapping({
index: "asrtest1",
include_type_name: false,
body:{
"properties" : {
"text" : {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_max_word"
}
}
}
}).then((data)=>{
console.log("add success:", data)
}).catch((err)=>{
console.error("add error:", err)
})
测试中文分词引擎:
client.indices.analyze({
"index":"asrtest1",
"body":{
"analyzer" : "ik_max_word",
"text" : "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
}
}).then((data)=>{
console.log("analyzer run success:", data.body.tokens)
}).catch((err)=>{
console.error("analyzer run error:", err)
})
[{token:'中韩',start_offset:0,end_offset:2,type:'CN_WORD',position:0},
{token:'渔',start_offset:2,end_offset:3,type:'CN_CHAR',position:1},
{token:'警',start_offset:3,end_offset:4,type:'CN_CHAR',position:2},
{token:'冲突',start_offset:4,end_offset:6,type:'CN_WORD',position:3},
{token:'调查',start_offset:6,end_offset:8,type:'CN_WORD',position:4},
{token:'韩',start_offset:9,end_offset:10,type:'CN_CHAR',position:5},
{token:'警',start_offset:10,end_offset:11,type:'CN_CHAR',position:6},
{token:'平均',start_offset:11,end_offset:13,type:'CN_WORD',position:7},
{token:'每天',start_offset:13,end_offset:15,type:'CN_WORD',position:8},
{token:'扣',start_offset:15,end_offset:16,type:'CN_CHAR',position:9},
{token:'1',start_offset:16,end_offset:17,type:'ARABIC',position:10},
{token:'艘',start_offset:17,end_offset:18,type:'COUNT',position:11},
{token:'中国',start_offset:18,end_offset:20,type:'CN_WORD',position:12},
{token:'渔船',start_offset:20,end_offset:22,type:'CN_WORD',position:13}]
结果是符合预期的。
2.2 按月自动建索引
2.1小节中分步骤分析了每个字段应该如何建立索引,而业务场景下有个需求是按月建索引。可以选择跑个定时脚本,每个月去自动创建下一个月的index,也有更简单的选择 —— 插入数据的时候,如果发现索引名称不存在,则自动创建索引,elasticserch提供了这样的功能。为了实现这个目标,需要看两个部分的文档: 集群的自动index创建配置、index模板。
首先创建一个index模板:
client.indices.putTemplate({
"name": "asrtemp",
"include_type_name": false,
"body":{
"index_patterns" : ["asr*"],
"settings": {
"analysis": {
"analyzer": {
"qua_analyzer": {
"type": "pattern",
"pattern": "&"
}
}
}
},
"mappings": {
"properties": {
"id" : { "type" : "keyword" },
"app_key" : { "type" : "keyword" },
"guid" : { "type" : "keyword" },
"one_shot" : { "type" : "keyword" },
"log_time" : {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"qua" : {
"type": "text",
"analyzer": "qua_analyzer",
"search_analyzer":"qua_analyzer"
},
"text" : {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_max_word"
}
}
}
}
}).then((data)=>{
console.log("add template success:", data)
}).catch((err)=>{
console.error("add template error:", err)
})
修改集群配置,设置自动创建索引时只应用此模板(也可以修改此配置,默认是应用所有满足pattern的模板):
client.cluster.putSettings({
body:{
"persistent": {
"action.auto_create_index": "asrtemp"
}
}
})
写入一个document,指定一个不存在但是满足template中index_patterns的index:
client.create({
id:"testid1",
index:"asrtest2",
body:{
"id":"testid1",
"app_key":"dc6aca3e-bc9f-45ae-afa5-39cc2ca49158",
"guid":"4ccaee22-5ce3-11e9-9191-1b9bd38b79e0",
"one_shot":"0",
"log_time":"2019-05-14 09:13:20",
"qua":"key1=asd.asda.asf&key2=2.0.20.1&key3=val3&testk=testv",
"text":"明天武汉的天气好不好啊"
}
}).then((data)=>{
console.log("create success:", data)
}).catch((err)=>{
console.error("create error:", err)
})
写入成功,查询一下新生成的index的信息:
client.indices.get({
index: "asrtest2"
}).then((data)=>{
console.log("get success:", data.body.asrtest2.mappings,data.body.asrtest2.settings)
}).catch((err)=>{
console.error("get error:", err)
})
{ properties:
{ app_key: { type: 'keyword' },
guid: { type: 'keyword' },
id: { type: 'keyword' },
log_time: { type: 'date', format: 'yyyy-MM-dd HH:mm:ss||epoch_millis' },
one_shot: { type: 'keyword' },
qua: { type: 'text', analyzer: 'qua_analyzer' },
text: { type: 'text', analyzer: 'ik_max_word' } } }
{ index:
{ number_of_shards: '1',
provided_name: 'asrtest2',
creation_date: '1555319547412',
analysis: { analyzer: [Object] },
number_of_replicas: '1',
uuid: '_GcwsE4vSBCDW0Pv35w0uA',
version: { created: '7000099' } } }
与模板是一致的,自动创建成功。
2.3检索请求
请求时,需要做到:①各种字段交叉组合检索 ②支持分页统计count、offset ③支持按时间排序 ④延时不能太长。下面首先插入几百万条模拟数据,然后实践一下上面的三个检索需求。
2.3.1 模拟数据
为了快速大批量插入数据,应该使用elasticsearch提供的bulk api来进行数据插入的操作,关键代码:
function mockIndex(index){
var indexName = "asrtest2"
if(index >= 4000000){
console.log(`index mock done!`)
return;
}
if(index % 10000 == 0){
console.log(`current num:${index}`)
}
var mockDataList = []
for(var i=0;i<500;i++){
var mock = getOneRandomData(index++)
mockDataList.push({ "index" : { "_index" : indexName, "_id" : mock.id } })
//mock: {app_key,log_time,guid,qua,id, text, one_shot"}
mockDataList.push(mock)
}
client.bulk({
index:indexName,
body: mockDataList
}).then(()=>{
mockIndex(index)
}).catch((err)=>{
console.error("bulk error:",err.message)
})
}
mockIndex(0)
2.3.2 条件检索
模拟数据灌满后,测试一下多索引联合检索,并设置排序字段、获取count、观测性能、验证结果的正确性。此处建议通读elasticsearch文档Search APIs、 Query DSL(elastic自己造的一种抽象语法树)。
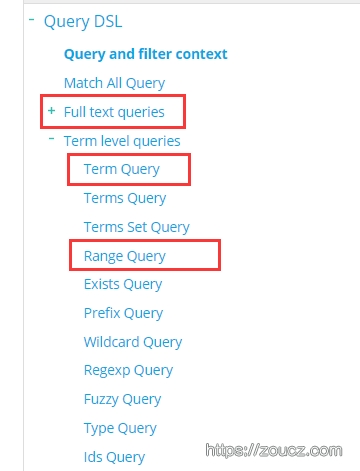
在这些部分可以看到,各个类型的字段应该如何生成检索条件
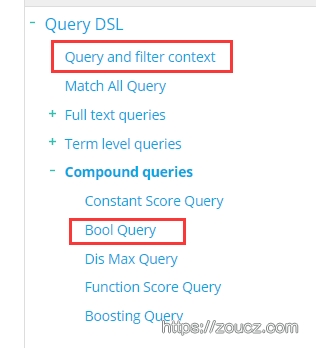
这些部分可以看到如何将各个字段的检索条件合理组成一个复合检索参数
这些部分可以看到如何使用字段排序、如何设置返回结果数量、偏移量。
最后,根据文档的说明,写一个测试检索代码:
client.search({
index: "asrtest1",
from: 0,
size: 10,
sort: "log_time:asc",
body:{
"query": {
"bool": {
//测试query和filter
//"must": [
// { "match_phrase": { "qua": "SDK=39.60.17160906"}},
// { "match_phrase": { "text": "舞麟" }}
//],
"filter": [
{ "match_phrase": { "qua": "SDK=39.60.17160906"}},
{ "match_phrase": { "text": "舞麟" }},
//id和guid是unique字段
//{ "term": { "id": "c2e86a41-5f73-11e9-b3d0-45c4efcbf90f" }},
//{ "term": { "guid": "2081359c-5f72-11e9-b3d0-45c4efcbf90f" }},
{ "term": { "app_key": "faf1e695-9a97-4e8f-9339-bdce91d4848a" }},
{ "term": { "one_shot": "1" }},
{ "range": { "log_time": { "gte": "2019-04-15 08:00:00" }}}
]
}
}
}
}).then((data)=>{
console.log("timecost:", data.body.took)
console.log("total:", data.body.hits.total)
console.log("hits:", data.body.hits.hits)
}).catch((err)=>{
console.log("error:", err)
})
变换各种条件查询,条件查询、排序、返回条数、偏移、总数等都是符合预期的。
如果有细心看上面的代码,可以发现query条件中有注释掉的must部分,这是因为我面临的业务场景下不需要对document进行score计算,只需要过滤结果,所以将所有的条件塞到filter中,elastic内部会有一些缓存策略,提高效率。经测试,将两个match_phase条件放到must中,400W条数据检索平均耗时在30—40ms,而放到filter中后,平均仅为7—8ms。
减少条件,只保留时间限制,发现:
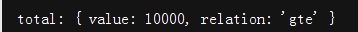
至少应该有两百多万条结果,这里total只有10000条。
可以通过修改index的settings,index.max_result_window属性,来修改这个数量。
但是!文档中提到" Search requests take heap memory and time proportional to from + size and this limits that memory",还有这篇文档,这里可以看到es就不适合用于大规模数据的完全遍历!想要使用es完美解决所有问题,得一口老血喷在屏幕上!
这里虽然没办法直接查询到大offset数据,但是可以通过Count API查询到真实总数,然后通过其它的search方法来达到分页的目标,好在elasticsearch也是考虑了这一点,提供了Search After API来应对这种场景。
说白了就是使用了另一种分页模式,需要业务自己维护上下文,通过传入上一次查询的最后一个结果作为起点,再往后面去查询结果。
修改查询代码:
client.search({
index: "asrtest1",
size: 10,
sort: "log_time:desc,id:desc",
body:{
"query": {
"bool": {
"filter": [
{ "range": { "log_time": { "gte": "2019-04-15 08:20:00" }}}
]
}
}
}
}).then((data)=>{
console.log("first 10 result:", data.body.hits.hits)
let last = data.body.hits.hits.slice(-1)[0].sort
return client.search({
index: "asrtest1",
size: 10,
sort: "log_time:desc,id:desc",
body:{
"query": {
"bool": {
"filter": [
{ "range": { "log_time": { "gte": "2019-04-15 08:20:00" }}}
]
}
},
"search_after": last,
}
})
}).then((data)=>{
console.log("second 10 result:", data.body.hits.hits)
}).catch((err)=>{
console.log("error:", err)
})
这样,就可以查到任意多的结果,又不会把集群搞死了。
本文基于一个简单的业务场景大致实践了一遍elasticsearch的使用,而实际上集群的搭建、运维,是一个非常复杂的工作,而很多云服务上都提供了包装好的PAAS服务,如腾讯云ElasticSearch Service,直接购买接入即可。
