
翻译:关于OpenGL ES 2.x(第二篇)
翻译:关于OpenGL ES 2.x(第二篇)
原文:All about OpenGL ES 2.x - (part 2 / 3)
我的朋友们,欢迎回来!
现在我们知道基本的3D世界和OpenGL的概念。是时候开始我们的快乐之旅!让我深入代码,然后能在屏幕上看到一些结果。这里我将展示用最好的体验怎样去构建
一个OpenGL应用。
如果你没有看过第一篇,你可以通过下面的链接去查看。
这个系列由3部分组成:
开始之前,我想说一声:谢谢你!
第一篇辅导分享篇幅远远超出我的想象。当我在网站上看到这个消息的时候,我惊呆了,说不出话来,真是太神奇了!因此,我要再次表示非常感谢你!
这里有一个小目录,方便你阅读:
前言
正如评论中提到的,下面提供一个PDF文件给那些喜欢以文件的方式阅读blog
还记得此系列第一部分,我们已经知道:
-
- OpenGL的逻辑由3个简单的概念组成:原语、缓冲及栅格化
-
- OpenGL工作在固定的或者可编程的管线中
-
- 可编程管线与着色器同义,着色有分为:顶点着色器和片段着色器
这里我们将基于C和Objective-C展示更多的代码。在一些部分我将特别指出关于iPhone和iOS。但一般情况代码对任意语言或平台通用。OpenGL ES是最简单OpenGL的API,我们将聚焦在这上面。如果你正在使用OpenGL或WebGL,你可以在此使用所有的代码和概念。
此篇辅导的代码仅在于说明功能和概念,不是真正的运行代码。下面有一个Xcode工程,其中有此篇辅导所有的概念和代码。我用Objective-C++创建了主要的类(CubeExample.mm)用来更清晰的向每位展示OpenGL ES 2.0如何工作,甚至你你都用不上Objective-C。这篇练习工程为iOS创建,更专门针对iPhone。
我将要用
gl + 函数名这样的语法使用OpenGL功能。几乎所有OpenGL的实现都使用gl或gl.的前缀。但如果你使用的编程语言没有使用这个,你可以忽略这段话。
在我们开始这篇辅导前另外一个重要的事情是关于OpenGL的数据类型。OpenGL作为一个跨平台和基于供应商的实现,许多数据类型从一种语言到别一种语言会发生改变。例如:C++中的一个浮点数可以精确的表示32位,但在JavaScript中一个浮点数可能只代表16位。为了避免这种类型的冲突,OpenGL总是用自己的数据类型。OpenGL的数据类型拥有前缀
GL,像GLfloat、GLint。下面是一个OpenGL数据类型的完整列表:
| OpenGL Data Type | Same As C | Description |
|---|---|---|
| GLboolean(1 bit) | unsigned char | 0 to 1 |
| GLbyte(8 bits) | char | -128 to 127 |
| GLubyte(8 bits) | unsigned char | 0 to 255 |
| GLChar(8 bits) | char | -128 to 127 |
| GLshort(16 bits) | short | -32768 to 32767 |
| GLushort(16 bits) | unsigned short | 0 to 65353 |
| GLint(32 bits) | int | -2147483648 to 2147483647 |
| GLuint(32 bits) | unsigned int | 0 to 4294967295 |
| GLfixed(32 bits) | int | -2147483648 to 2147483647 |
| GLsizei(32 bits) | int | -2147483648 to 2147483647 |
| GLenum(32 bits) | unsigned int | 0 to 4294967295 |
| GLdouble(64 bits) | double | -9223372036854775808 to 9223372036854775807 |
| GLbitfield(32 bits) | unsigned int | 0 to 4294967295 |
| GLfloat(32 bits) | float | -2147483648 to 2147483647 |
| GLclampx(32 bits) | int | Integer clamped to the range 0 to 1 |
| GLclampf(32 bits) | float | Floating-point clamped to the range 0 to 1 |
| GLclampd(64 bits) | double | Double clamped to the range 0 to 1 |
| GLintptr | int | pointer * |
| GLsizeiptr | int | pointer * |
| GLvoid | void | Can represent any data type |
关于数据类型还有一个重要信息:OpenGL ES不支持64位数据类型,因为嵌入式系统通常需要性能以及很少的设备支持64位处理器。在使用OpenGL数据类型时,你可以很容易且安全将你的OpenGL应用从C++转移到JavaScript,无须改变很多。
最后我们将介绍图形管线。我们将使用且讨论很多关于可编程管线,下面是一个图片说明:
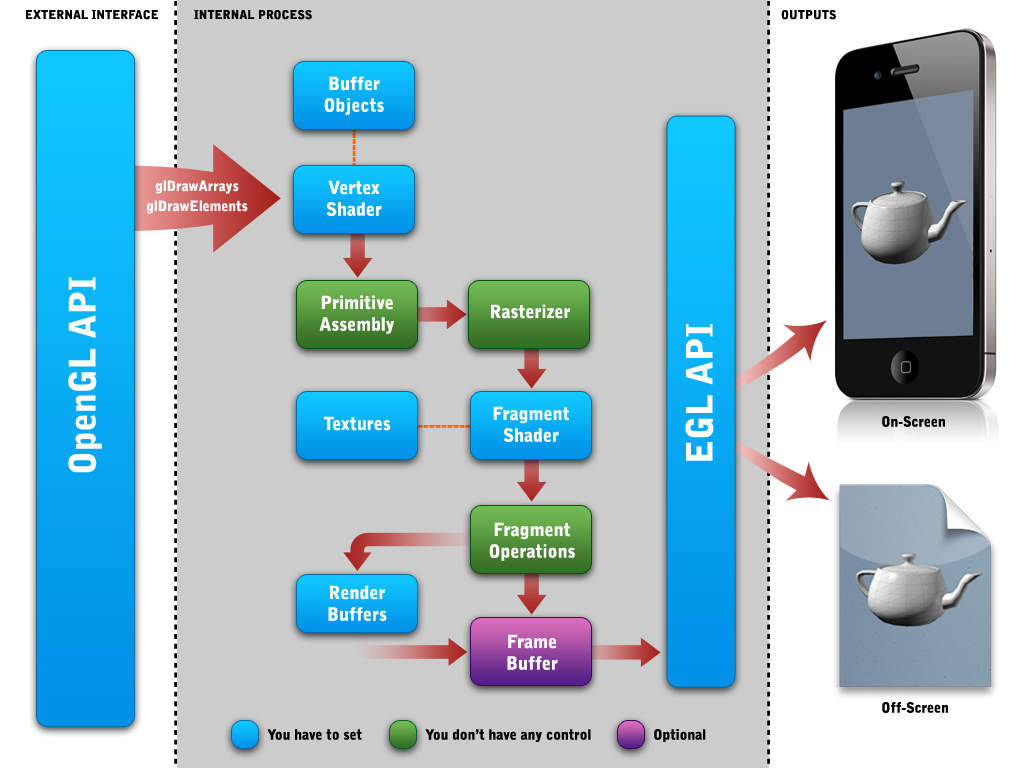
我们将会深入讨论上述图表中每一步。现在我想说的只有一件事,就是上述表中的“Frame Buffer”。“Frame Buffer”被标记为可选,因为你可以选择不直接使用它,但在OpenGL的内核内部总是则至少要使用一个
Frame Buffer和Color Render Buffer。
上面的图片中你注意到了EGL API?对于我们的OpenGL应用是非常重要的一步。在开始这篇指导前,我们至少要知道基本的概念和EGL API的组成。但是EGL是一个复杂的学科,我不能把它放在这里。所以我已经写了一篇文章去说明它。你可以在这里查看:EGL and EAGL APIs。我推荐你在继续这篇指导前先去阅读它。
OpenGL数据类型和可编程管线
如果你已经阅读或者已经了解EGL,让我们来到顺序第一部分,开始讨论关于
Primitives。
原语
你还记得第一部分中,当时我说过,原语是点、线、三角形?他们都是由一个或者更多的点在空间组成,也被叫做顶点。一个顶点有3个信息,X、Y、Z。一个3D点由一个顶点组成,一条3D线由两个顶点组成,一个三角形由三个顶点组成。正如OpenGL总是想要增加性能,所有信息应该在一个单一空间数组,更确切的说,是一个浮点值数组。像这样的数组:
GLfloat point3D = {1.0, 0.0, 0.5};,GLfloat line3D = {0.5, 0.5, 0.5, 1.0, 1.0, 1.0};,GLfloat triangle3D = {0.0, 0.0, 0.0, 0.5, 1.0, 0.0, 1.0, 0.0, 0.0};。
正如你所看到的,对OpenGL来说浮点数组在顶点之间是没有区别的,OpenGL会自动解析第一位作为X的值,第二位为Y的值,第三位为Z的值。OpenGL会循环解析每三值的一个序列。所有你需要做的是通知OpenGL是想构建一个点、一条线或者一个三角形。一个高级知识是可以自定义你想要的顺序,OpenGL可以使用第四个值,但这是属于更高级的话题。目前我们只假定总是XYZ。此坐标构建的一些东西会像下面这样
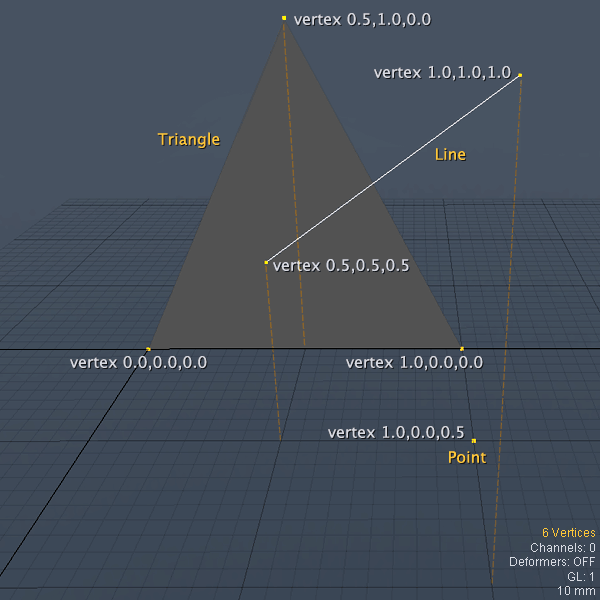
在这张图中,橙色虚线是为了标识让你更清楚的看清哪些顶点与平面相关。直到这里看起来都很简单!但马上有一个问题:我怎样将来自3DS Max或者Maya的3D模型转换到我的OpenGL的数组中?当我在学习OpenGL的时候,我认为应该存在某个3D格式的文件直接导入OpenGL。尽管OpenGL是最流行的图形库,也被最多的3D软件使用。我确信应该有某些3D文件可以直接导入。但我还是错了。不好的消息是,我已经学习了,且要告诉你:记住OpenGL专注于最重要且最难3D世界组成。所以它不应该对善变的事负责,如3D文件格式。存在如此多的3D格式文件,如:.obj,.3ds,.max,.ma,.fbx,.dae,.lxo,...对于OpenGL来说太多了,Khronos也担心这些。但Collada格式是来自Khronos?所以我应该期待将来某一天可以直接导入Collada文件?不会!接受这个事实,OpenGL不会处理3D文件!好的,我们需要从3D软件导入3D模型到我们的应用中?不幸的是,我的朋友,我要告诉你:你需要一个3D引擎或者第三方API。没有简单的途径去实现那些。如果你选择一个3D引擎,如PowerVR,SIO2,Olong,UDK,Ogre等其它,你会陷入它们的API和它们的OpenGL的实现。如果选择一个三方API只用来加载3D文件,你需要集成三方的类自己去实现OpenGL。另一种选择去为你3D软件搜索插件导出这件对像为.h文件。这.h只是个头文件以OpenGL数组格式包含3D对像。不幸的是,直至今天我才2个插件在做此事:一个是Blender用Phython实现的,另一个是Pearl实现。我还见过Maya, 3DS Max, Cinema 4D, LightWave, XSI, ZBrush 或 Modo的插件。我告诉还有另外一个机会,叫做NinevehGL!这里我不讨论,但我用纯Objective-C制作OpenGL ES 2.X的3D引擎。我提供给你整个引擎或分析一些类似于.obj .dae文件格式的API。无论你喜欢哪种,你可以查看此网址NinevehGL。NinevehGL优势是什么?简单!其它3D引擎要么太大要么太重。NinevehGL是免费的。OK,让我们更深入的了解原语。
网格和线的优化
OpenGL绘制一个3D点只有一种方式,但是一条线和一个三角形有三种方式:普通的、带和循环的线和普通,条形和扇形的三角形。根据绘制的模式,你可以增强你的渲染性能和节省应用的内存。但在稍后将讨论这些。当前,所有我们需要知道最复杂3D网格,你可以想像它是由一堆三角形组成。我们称这些三角形为面。让我用顶点数组创建一个3D立方体。
// Array of vertices to a cube
GLfloat cube3D[] =
{
0.50, -0.50, -0.50, // vertex 1
0.50, -0.50, 0.50, // vertex 2
-0.50, -0.50, 0.50, // vertex 3
-0.50, -0.50, -0.50, // vertex 4
0.50, 0.50, -0.50, // vertex 5
-0.50, 0.50, -0.50, // vertex 6
0.50, 0.50, 0.50, // vertex 7
-0.50, 0.50, 0.50, // vertex 8
}
浮点数的精度位数对OpenGL影响不大,但它可以节省很多内存和文件的大小(0.00是精度为2位,0.00000是精度为5位)。因此我喜欢用低精度的,2位非常不错。我不想使你变迷惑,但有些情况你必需要知道。一般情况下,网格有三个重要信息:顶点、纹理坐标和法线。一个好的方法是创建一个单一数组包含所有这些信息。称作数组结构。
一个简短的例子如下:
// Array of vertices to a cube
GLfloat cube3D[] =
{
0.50, -0.50, -0.50, // vertex 1
0.00, 0.33, // texture coordinate 1
1.00, 0.00, 0.00, // normal 1
0.50, -0.50, 0.50, // vertex 2
0.33, 0.66, // texture coordinate 2
0.00, 1.00, 0.00, // normal 2
}
你可以将这种构造技术用于任何你想作为顶点数据使用的信息。随之而来的一个问题:用这种方式我所有的数据只有一种格式,如GLfloat?是的,但后面我会告诉你这将不是一个问题,因为数据要处理的地方只接受浮点值,所有都是GLfloat。现在不要担心这些,在合适的时间你会理解。OK,现在我们有3D网格,让我们来配置3D应用,同时存储网格到OpenGL的缓存。
缓冲区
你还记得我在第一部分说过OpenGL是一个状态机就像港口的起重机一样?现在让我们对那个说明做一些改进。OpenGL像一个拥有几个手臂和钩子的港口起重机。因此它可以同时控制多个容器。

主要的有四个“手臂”:纹理手臂(double arm),缓冲对象手臂(double arm),渲染缓冲手臂和帧缓冲手臂。每个手臂一次只能控制一个容器。这点是非常重要的,我将会重复这点:每个手臂一次只能控制一个容器!纹理和缓冲对象手臂是双臂,可能控制两种不同的纹理和缓冲对象,但一次仍然只能控制一种容器。我们需要通知OpenGL起重机从港口抓起一个容器,我们可以通过容器的名字/id来通知到容器。回到代码中,通知OpenGL去抓取一个容器的命令是:glBind。因此,你每次看到glBind*的时候,这说明是OpenGL去抓取一个容器。对于这个规则只有一个例外,后面将会讨论。很好,在绑定一些东西到OpenGL之前,我们需要创建一些。我们使用glGen函数去生成容器的名字/id.
帧缓冲区
帧缓冲是一个渲染输出的临时存储。一旦我们渲染的在帧缓冲,可以选择在屏幕上呈现或者以图片文件的格式存储或者将输出作为一个快照。这是与帧缓存相关的函数:
// FrameBuffer Creation
GLvoid glGenFramebuffers(GLsizei n, GLuint *framebuffers)
* n: 表示一次有多少个帧缓冲的 names/ids 将会生成
* framebuffers: 一个指向变量的指针存储生成的 names/ids。如果生成的 name/id多于一个,此指针则指向数组的起始位置
GLvoid glBindFramebuffer(GLenum target, GLuint framebuffer)
* target: 值总是 GL_FRAMEBUFFER,这是OpenGL的内部约定
* framebuffers: 需要绑定的帧缓冲的name/id
在更深层次,当我们第一次绑定一个OpenGL对象时,它的创建过程将由内核自动完成。但这个过程不会产生一个 name/id 给我们。因此建议总是使用glGen*创建缓冲的 names/ids 而不是创建自己的 names/ids。听起来是还不迷惑?好的,让我们来看第一行代码,你马上就会清晰的明白:
GLuint frameBuffer;
// Creates a name/id to our frameBuffer
glGenFramebuffers(1, &frameBuffer);
// the real Frame Buffer Object will be created here,
// at the first time we bind an unused name/id
glBindFramebuffer(GL_FRAMEBUFFER, frameBuffer);
// We can suppress the glGenFramebuffers
// But in this case we'll need to manage the names/ids by ourselves
// In this case, instead the above code, we could write something like:
// GLint frameBuffer = 1;
// glBindFramebuffer(GL_FRAMEBUFFER, frameBuffer);
上面的代码创建了一个称为帧缓存的GLint类型的数据实例。然后我们将frameBuffer变量的内存位置通知给glGenFramebuffers,并表示该函数只生成一个 name/id(当然,我们一次可以生成多个names/ids)。最终我们将生成的frameBuffer绑定到OpenGL的内核。
渲染缓冲区
渲染缓存是一个为来自OpenGL渲染的临时图像存储。这是与渲染缓冲区相关的一对函数
// RenderBuffer Creation
GLvoid glGenRenderbuffers(GLsizei n, GLuint *renderbuffers)
* n: 代表有多少个渲染缓冲的 names/ids 将会被生成
* renderbuffers: 一个指针变量存储生成的 names/ids,如果是多个则指向数组首位
GLvoid glBindRenderbuffer(GLenum target, GLuint renderbuffer)
* target: 值一般都是GL_RENDERBUFFER,OpenGL的内部约定
* renderbuffer: 渲染缓存要绑定的 name/id
好的,现在在我们继续之前,你还记得第一部分我说过渲染缓冲区是一个临时存储,可以有三种类型。因此我们要指定一种渲染缓冲的类型和临时图像的一些属性。我们通过使用下面的函数设置渲染缓冲的属性:
// RenderBuffer Properties
GLvoid glRenderbufferStorage(GLenum target, GLenum internalformat, GLsizei width, GLsizei height)
* target: 值一般都是 GL_RENDERBUFFER,OpenGL的内部约定
* internalformat: 指定我们想要的渲染缓冲想要的类型,使用什么颜色格式的临时图像,此参数的值可能是:
- GL_RGBA4, GL_RGB5_A1, 或者 GL_RGB56渲染缓冲区的最终颜色
- GL_DEPTH_COMPONENT16渲染缓冲区的Z深度
- GL_STENCIL_INDEX 或者 GL_STENCIL_INDEX8 渲染缓冲区的模板倣
* width: 渲染缓冲区的宽度
* height: 渲染缓冲区的高度
你可能会问,我要把这些属性设置到哪些缓冲区?OpenGL如何知道哪些缓冲区是这些属性?在这里伟大的OpenGL状态机出现了!这些属性会被设置到最后的渲染缓冲区绑定。非常简单。看我如何设置3种渲染缓冲类型:
GLuint colorRenderbuffer, depthRenderbuffer, stencilRenderbuffer;
GLint sw = 320, sh = 480; // Screen width and height
// Generates the name/id, creates and configures the Color Render Buffer
glGenRenderbuffers(1, &colorRenderbuffer);
glBindRenderbuffer(GL_RENDERBUFFER, colorRenderbuffer);
glRenderbufferStorage(GL_RENDERBUFFER, GL_RGBA4, sw, sh);
// Generates the name/id, creates and configures the Depth Render Buffer
glGenRenderbuffers(1, &depthRenderbuffer);
glBindRenderbuffer(GL_RENDERBUFFER, depthRenderbuffer);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT16, sw, sh);
// Generates the name/id, creates and configures the Stencil Render Buffer
glGenRenderbuffer(1, &stencilRenderbuffer);
glBindRenderbuffer(GL_RENDERBUFFER, stencilRenderbuffer);
glRenderbufferStorage(GL_RENDERBUFFER, GL_STENCIL_INDEX8, sw, sh);
但在我们的立方体应用中不需要模板缓冲区,所以上面的代码我们可以优化为:
GLuint *renderbuffers;
GLint sw = 320, sh 480; // Screen width and heigth
// Let's create multiple names/ids at once.
// To do this we declared our variable as a pointer *renderbuffers
glGenRenderbuffers(2, renderbuffers);
// The index 0 will be our color render buffer
glBindRenderbuffer(GL_RENDERBUFFER, renderbuffers[0]);
glRenderbufferStorage(GL_RENDERBUFFER, GL_RGBA4, sw, sh);
// The index 1 will be our depth render buffer
glBindRenderbuffer(GL_RENDERBUFFER, renderbuffers[1]);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT16, sw, sh);
现在我们要跑会题。这步与你使用Cocoa Framework 有点不同。苹果不允许我们直接用OpenGL渲染到屏幕上,我们需要将输出到一个颜色渲染区,要求EAGL(EGL的苹果的实现)呈现缓冲区到设备的屏幕上。在这种情况下颜色缓冲区是托管的,设置他们的属性我们需要从EAGLContext调用renderbufferStorage:fromDrawable方法,同时通知一个CAEAGLLayer我们要展示的。是不是听起来迷惑?如果迷惑可以选停止此篇阅读,先查看Apple's EAGL。在那篇文章中,我解释了什么是EAGL和如何使用它。一旦你了解EAGL,你使用下面的代码去设置颜色渲染缓冲的属性,而不是用glRenderbufferStorage
// RenderBuffer Properties in case of Cocoa Framework
- (BOOL)renderbufferStorage:(NSUinteger)target fromDrawable:(id)drawable
* target: 值通常为GL_RENDERBUFFER,只是OpenGL内部的约定
* fromDrawable: 自定义的CAEAGLLayer实例
// Suppose you previously set EAGLContext *_context
// as I showed in my EAGL article
GLuint colorBuffer;
glGenRenderbuffers(1, &colorBuffer);
glBindRenderbuffer(GL_RENDERBUFFER, colorBuffer);
[_context renderbufferStorage: GL_RENDERBUFFER fromDrawable: myCAEAGLLayer];
当你调用renderbufferStorage:fromDrawable: 方法通知CAEAGLLayer,EAGLContext将会从图层拿到所有相关的属性,并合适的设置绑定到颜色渲染缓冲区。现在是时候将我们的渲染缓冲放置到之前创建的帧缓冲区。每一个帧缓冲区仅仅包含一个类型的渲染缓冲区。因此我们不可能拥有一个有两种颜色缓冲的帧缓冲区。为了将渲染缓冲附加到帧缓冲中,我们使用以下函数:
// Attach RenderBuffers to a FrameBuffer
GLvoid glFramebufferRenderbuffer(GLenum target, GLenum attachment, GLenum renderbuffertarget, GLuint renderbuffer)
* target: 值通常是GL_FRAMEBUFFER,内部约定
* attachment: 指定哪种类型的渲染缓冲附加到帧缓冲区中,值可能为:
- GL_COLOR_ATTACHMENT0:附加一个颜色缓冲区
- GL_DEPTH_ATTACHMENT:附加一个深度缓冲区
- GL_STENCIL_ATTACHMENT0:附加一个模板缓冲区
* renderbuffertarget: 值通常是GL_RENDERBUFFER,内部约定
* renderbuffer: 想要附加的渲染缓冲区的 name/id
同样的问题出现了:OpenGL是如何知道哪个帧缓冲附加这些渲染的缓冲区?使用状态机!最后一个帧缓冲区将会绑定接收到的附件。在我们继续之前,我们要讨论下帧缓冲与渲染缓冲如何结合。他们看起来像下面的图片:
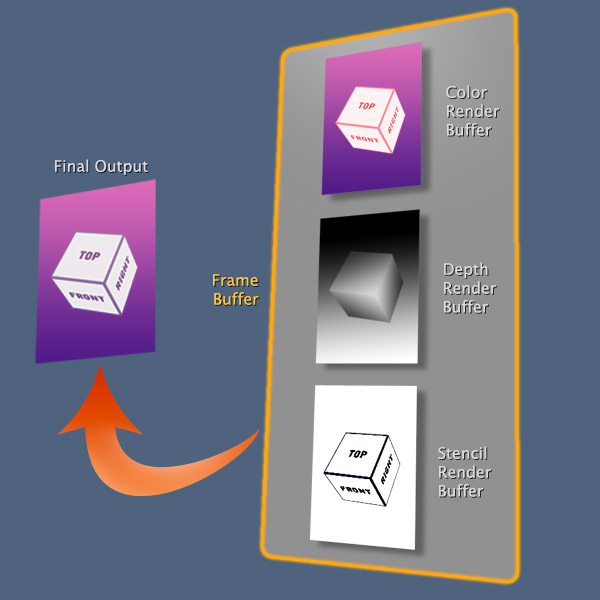
OpenGL内部总是工作在帧缓冲上。这被称为窗口系统提供的帧缓冲区,并且帧缓冲区的 name/id 0 被保留给它。我们控制的帧缓冲区称为应用程序创建的帧缓冲区。深度和模板渲染缓冲区是可选的。但颜色缓冲区总是启用的,同时OpenGL的核心总是使用颜色缓冲区,渲染缓冲区 name/id 0 为它保留。为了优化所有可选的状态,OpenGL给我们提供了一种方法去打开和关闭一些状态(理解每一个可选的GL特性)。为了做这些,我们使用如下函数:
// Turning ON/OFF the OpenGL' States
GLvoid glEnable(GLenum capability)
* capability: 哪种特征将被开启,它的值可能为:
- GL_TEXTURE_2D
- GL_CULL_FACE
- GL_DITHER
- GL_STENCIL_TEST
- GL_DEPTH_TEST
- GL_SCISSOR_TEST
- GL_POLYGON_OFFSET_FILL
- GL_SAMPLE_ALPHA_TO_COVERAGE
- GL_SAMPLE_COVERAGE
GLvoid glDisable(GLenum capability)
* capability: 哪种特性将被关闭,值同上面
一旦我们开启或者关闭此特性,这个指令将会影响整个OpenGL的状态机。一些人喜欢开启一个特性一会儿然后关闭,但这种做法不推荐。代价很大。最好的方式是开启一次且只关闭一次。如果真的需要,最少化在你的应用中去开启/关闭。让我们回到深度和模板缓冲区,如果你的应用中需要使用它们两个或者其中一个,尝试在需要的时候启用。在我们的立方体的例子中,我们可以这样写:
// Doesn't matter if this is before or after
// we create the depth render buffer
// The important thing is enable it before try
// to render something which needs to use it.
glEnable(GL_DEPTH_TEST);
稍后我们将深度讨论深度和模板测试的制作以及他们与片段着色器的关系。
缓冲对象
缓冲对象是对我们原语数组的优化的存储。有两种类型的缓冲对象,第一个是我们存储顶点的数组,因为缓冲对象也被熟知为顶点缓冲对象(VBO)。在你创建了缓冲对象后你就可以销毁原始数据,因为Buffer Object(BO)已经拷贝了一份。我们习惯称为VBO,但这种类型的缓冲对象可以在任何数组中持有,例如像法线数组、纹理坐标数组或者结构体数组。为了调整名字以符合正确的理念,人们称这种类型缓冲对象为Array Buffer Object(ABO)。另一种类型的缓冲对象是Index Buffer Object(IBO)。你还记得第一部分中的下标数组?click here to remember。因此IBO是存储此种类型的数组。通常数组的下标的数据类型是GLubyte或GLushort。一些设备已经支持到GLuint,但这个好像是一个扩展,是一个插件需要厂商去实现。多数只是支持默认的行为(GLubyte或GLushort)。因此我和设备总是限制你的数组的下标是GLushort。好的,现在创建这些缓冲区的步骤与帧缓冲和渲染缓冲非常相似。第一步你要创建一个或多个 names/ids,稍后绑定到一个缓冲对象上,然后你可以在其中定义属性和数据。
// Buffer Objects Creation
GLvoid glGenBuffers(GLsizei n, GLuint *buffers)
* n: 代表一次要创建多少个缓冲对像的 names/ids
* buffers: 一个指针指向创建的 names/ids,如果是数组则指向首位
GLvoid glBindBuffer(GLenum target, GLuint buffer)
* target: 定义哪种类型的缓冲对象,是VBO还是IBO,此值可能是
- GL_ARRAY_BUFFER: 将设置为VBO(或ABO)
- GL_ELEMENT_ARRAY_BUFFER: 将设置为一个IBO
* buffer: 要绑定的帧缓冲的 name/id
现在是时候完善关于港口起重机挂钩的说明了。缓冲对象钩事实上是一个双钩。因为它可以持有两个缓冲对象,每一种类型是:GL_ARRARY_BUFFER和GL_ELEMENT_ARRAY_BUFFER。好的,一旦你绑定了一个缓冲对象就要去定义它的属性或者说定义它的内容。由于缓冲对象钩是一个双钩,你可以同时绑定两个缓冲对象,你需要去命令OpenGL你想给哪个类型的缓冲对象设置属性。
// Buffer Objects Properties
GLvoid glBufferData(GLenum target, GLsizeiptr size, const GLvoid *data, GLenum usage)
* target: 指示要为何种类型的缓冲区设置属性,此参数可能为:GL_ARRAY_BUFFER 或 GL_ELEMENT_ARRAY_BUFFER
* size: 缓冲区的内存大小(以基本单位:bytes)
* data: 指向数据的指针
* usage: 使用类型,这是一个帮助OpenGL优化数据的技巧,可能有三种情况:
- GL_STATIC_DRAW: 这表示一个不可变的数据。只设置一次,并经常使用缓冲区
- GL_DYNAMIC_DRAQ: 这表示一个可变的数据。只设置一次,在多次使用时更新它的内容
- GL_STREAM_DRAW: 这表示一个临时数据。熟悉Objective-C,这个就像它的autorelease。你只设置一次,使用多次。稍后OpenGL自动清理和销毁此缓冲区
GLvoid glBufferSubData(GLenum target, GLintptr offset, GLsizeiptr size, const GLvoid *data)
* target: 指示哪种类型的缓冲你要设置属性,此值可能为GL_ARRAY_BUFFER或GL_ELEMENT_ARRAY_BUFFER
* offset: 这个数字表示你将开始对先前定义的buffer对象进行更改的偏移量,单位为:bytes
* size: 此数字代表加入之前定义的缓冲对象的变化大小,单位:bytes
* data: 指向数据的指针
现在让我们来理解这些函数的作用。第一个glBufferData,使用这个函数设置缓冲对象的内容和它的属性。如果你选择的使用类型是GL_DYNAMIC_DRAW,它说明你想稍后更新缓冲对象,为了做这些你需要使用第二个glBufferSubData。当你使用glBufferSubData时大小用的是之前定义的缓冲对象,因此你不能改变它。但是为了优化更新,你可以选择整个缓冲区对象的一小部分进行更新。就我个人而言,我不喜欢使用GL_DYNAMIC_DRAW,如果你停下来思考一下,你会发现在3D世界中并不存在这种行为效果,它只能通过改变原始顶点数据、法线数据或纹理坐标数据来实现。通过使用着色器,你可以改变几乎所有相关的数据。使用GL_DYNAMIC_DRAW当然比使用着色器的方法更昂贵。因此我的的建议是:尽可能的避免使用GL_DYNAMIC_DRAW!总是倾向于使用着色器功能来实现相同的行为。一旦正确的创建和配置了缓冲对象,使用起来很简单。所有我们需要去做的是绑定到期望的缓冲对象上。记住我们一次只能绑定一种类型的缓冲对象。当所有的缓冲对象在绑定状态时,所有的绘制命令都可使用它们。在使用之后就可以解除它们的绑定。现在我们来看看纹理。
纹理
哦,纹理在OpenGL中是一个大的话题。为了不增加本篇教程实际大小,就让我们来看看关于纹理的基本信息。更高级的话题我将放在本系列教程的第三部分或者另外的文章中。首先要告诉你的是2的幂(POT)。OpenGL仅仅只接收POT纹理。那是什么意思呢?那意味着所有纹理的宽和高的值都是2的幂。如2,4,8,16,32,64,128,256,512或1024像素。对于纹理,1024是一个更大的尺寸,通常表示纹理的最大的可能大小。因此在OpenGL中使用的所有纹理必须是尺寸像这样的:64 * 128,256 * 32,或者512 * 512。你不能使用200200或256100。这是一个优化GPU内部OpenGL处理的规则。另一个关于纹理的重要事情是OpenGL按顺序读取像素。通常图像文件格式化存储像素信息从左上角开始,逐行移动到右下角。像JPG、PNG、BMP、GIF、TIFF和其它格式的文件使用的是这种像素顺序。但在OpenGL中这个顺序颠倒了。在OpenGL中纹理读取像素从左下角开始,然后逐行向上到右上角结束。
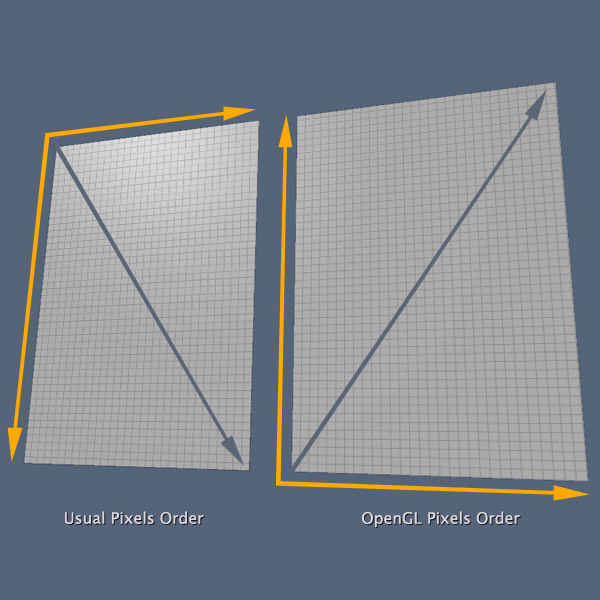
为了解决这个小问题,我们通常会在上传图像数据到OpenGL内核之前垂直翻转图像数据。如果你的编程语言允许你重新缩放图像,这相当于重新缩放高度为-100%。

简单讲一下逻辑,OpenGL中的纹理是这样工作的:你有一个图像文件,你必须从中提取二进制的颜色信息,以十六进制值。你也应该提取透明度信息,OpenGL支持RGB和RGBA两种格式。在这种情况下你需要从图像中提取十六进制+透明度信息。存储所有到像素数组。用这个像素数组(也叫做纹理,因为将被使用在)你可以构建一个OpenGL的纹理对象。如果需要,OpenGL将会拷贝你的数组并以优化的格式存储在GPU和帧缓冲区中。接下来是最复杂的部分,有些人用这种方法批评OpenGL。我个人认为这也可以更好,但这就是我们今天所拥有的。OpenGL有些东西叫做“纹理单元”,默认情况下OpenGL任何实现供应商必须支持到32纹理单元。这些单元代表了像素存储数组和实际渲染处理之间的临时链接。你将在着色器内部使用纹理单元,更特殊的是在片段着色器中。默认情况下每个着色器可以使用8纹理,一些供应商实现每个着色器支持16单位纹理。此外,OpenGL对着色器有限制,虽然每个着色器最多可以使用8个纹理单元,但对顶点和片段这对着色器最多只能使用8个纹理单位。困惑吗?如果你只在一个着色器使用纹理单元,你可以使用多达8个。但如果你正在使用纹理单元两个着色器(不同的纹理单元),你不能使用多于8个纹理单元的组合。OpenGL可以保留32个纹理单元,我们会在着色器中使用,但着色器只支持8个,这没有意义,对吧?嗯,关键是你可以设置32个纹理单元,并在许多着色器中使用它。但如果你要使用33个纹理单元,你需要从前面的32个中选一个重用。非常困惑!我明白,让我们用一个可视化的解释来澄清此观点:
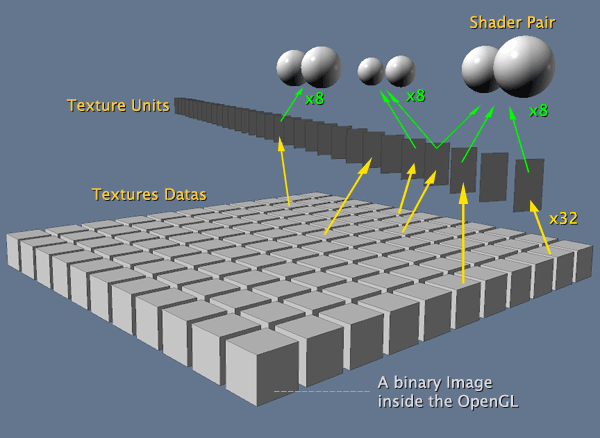
正如你在图中看到的一样,一个纹理单无可以被多对着色器使用多次。这个方法确实很困惑,让我们通过Khronos的角度来理解它:着色器真的很棒!一个Khronos开发者对另一个开发者说道,它们通过CPU处理的非常快!但是纹理数据仍然在CPU中,它们非常的大和信息很多!嗯,因此我们需要一个更快的方法让着色器访问纹理,像一座桥或者一些临时的东西。嗯,我们可以创建一个纹理单位可以直接让GPU处理,正如着色器。我们可以限制当前正运行在GPU上的纹理单位的数量。GPU的一个缓存,更快,更好!好的,为了进行设置,用户将一个纹理数据绑定到一个纹理单元,并指示它的着色器使用该单元!似乎很简单,我们就用变种方法。通常纹理单元被用在片段着色器中,但顶点着色器也可执行查找纹理。这不是通用情况,但在某些情况下非常有用。有两件重要的事要记住:一、你必须通过使用glActiveTexture()激活纹理单元,然后使用glBindTexture()绑定纹理的name/id。二、默认OpenGL支持到32纹理单位,你不能用槽数量高于支持的最大结构单位的供应商的实现,所以如果你不去持OpenGL实现超过16纹理单元,你可以使用纹理单元范围在0~15。当然OpenGL的纹理单元方法可能会更好,但正如我所说的,这是我们现在所拥有的。好的,代码与上面的其它的相似:你创建一个纹理对象、绑定纹理然后设置属性。下面是函数:
// Texture Creation
GLvoid glGenTextures(GLsizei n, GLuint *textures)
* n: 此数字代表一次有多少个纹理names/ids生成
* size: 一个指针变量指向生成的names/ids,如果有多个则指向数组的首位
GLvoid glBindTexture(GLenum target, GLuint texture)
* target: 此参数定义纹理的类型,是2D还是3D,值可能为:
- GL_TEXTURE_2D 设置为2D纹理
- GL_TEXTURE_CUBE_MAP 设置为3D纹理
* texture: 要绑定的纹理的 name/id
最奇怪的是3D纹理?我猜这是我第一次听到3D纹理,是什么东西!嗯,因为这个奇怪,OpenGL调用一个立方体映射3D纹理。听起来不错!总之,代表每个面都是一个2D纹理的立方体。那我们怎么才能拿到那些纹理呢?在立方体中心放置一个3D向量。这个主体需要更多的关注,因此我这里将跳过3D纹理,在这个系列的教程的第三部分讨论。现在专注于2D纹理。只使用GL_TEXTURE_2D。因此,在我们创建了一个2D纹理后,需要设置它的属性。Khronos团队称OpenGL内核为“服务”,当我们定义一个纹理数据他们说这是“上传”。为了上传纹理数据和设置某些属性:我们使用:
// Texture Properties
GLvoid glTexImage2D(GLenum target, GLint level, GLint internalformat, GLsizei width, GLsizei height, GLint border, GLenum format, GLenum type, const GLvoid *pixels)
* target: 对于2D纹理来说值是 GL_TEXTURE_2D
* level: 参数代表mip(Machine Instruction Processor: 机器指令处理器)映射级别。基础级别是0,目前只使用0.
* internalformat: 代表像素颜色的格式,值可能为:
- GL_RGBA: RGB+Alpha
- GL_RGB: 仅RGB
- GL_LUMINANCE_ALPHA: RED + Alpha,在这种模式下red代表光度
- GL_LUMINANCE:仅RED,在这种模式下red代表光度
- GL_ALPHA: 仅Alpha
* width: 图像的宽度,以像素为单位
* height: 图像的高度,以像素为单位
* border: 在OpenGL ES中此参数忽略。通常为0。这只是为了与桌面版本兼容而保留的一个内部常量。
* format: 要与 `internalformat`同样的值。这只是OpenGL内部的约定
* type: 代表像素格式的数据,值可能为:
- GL_UNSIGNED_BYTE: 代表每个像素4个bytes,因此你可以8位给r,8位给g,8位给b,8位给alpha,可以给所有的颜色格式使用
- GL_UNSIGNED_SHORT_4_4_4_4: 代表每个像素2个bytes,4位r,4位g,4位b,4位alpha,只给RGBA使用
- GL_UNSIGNED_SHORT_5_5_5_1: 代表每个像素2个bytes,5位r,5位g,5位b,1位alpha,只给RGBA使用
- GL_UNSIGNED_SHORT_5_6_5: 代表每个像素2个bytes,5位r,6位g,5位b,只给RGB使用
* pixels: 指向像素数组的指针
哇,这么多的参数!是的,但不难理解。首先,与其它的“钩子”行为一样,调用glTexImage2D给最后绑定的纹理设置属性。关于mip映射,是OpenGL另外一个特性用来优化渲染时间。简而言之,它所做的就是逐步创建原始纹理的较小副本,直到一个不重要的1*1像素副本。在后面的栅格化处理,OpenGL可以根据与视图相关的3D对象中最终大小选择原始或一个副本使用。目前,我们不需要担心这个特征,我也许会创建一篇文章专门讨论OpenGL的纹理。在处理映射后,我们设置颜色格式,图像尺寸,数据的格式及最终我们的像素的数据。每个像素2个bytes优化数据格式是最好的方式去优化你的纹理,你可以随时使用它。记住OpenGL中使用的颜色不能超出颜色的范围和设备的格式及EGL上下文。现在我们知道怎样去构建一个基础的纹理及它在OpenGL内怎样工作。接下来让我们看看栅格化。
栅格化
严格意义上的栅格化只是OpenGL将一个3D对象转换成2D图像的过程。每个可见区域的片段都会通过片段着色器处理。在此教程的开头查看可编程管线指令,你可以发现光栅化是图形管线中的一小步。那它为什么这么重要?我想说的是,栅格化之后的所有东西也是一个栅格化过程,因为之后所做的也是从一个3D对象构建一个最终的2对象。总之,栅格化实际上是从3D对象创建一个图像的过程。栅格化发生在场景中的每一个3D对象,同时将会更新帧缓冲区。在栅格化的过程中你可以通过多种方式进行干扰。
面消除
现在是时候讨论面剔除。正面和背面,OpenGL使用一些方法来查找和丢弃不可见的面。假想在3D平面上简单的平面。你想要仅一边的这个面板可见(因为它代表一面墙或地板)。默认情况下,OpenGL会渲染平面的两面。为了解决这个问题,你要使用面剔除。根据顶点的顺序,OpenGL可以决定哪个是网格的正面和背面(更精确它会计算正面和背面的角度),使用剔除你可以命令OpenGL忽略哪些面(甚至全部)。看下图:
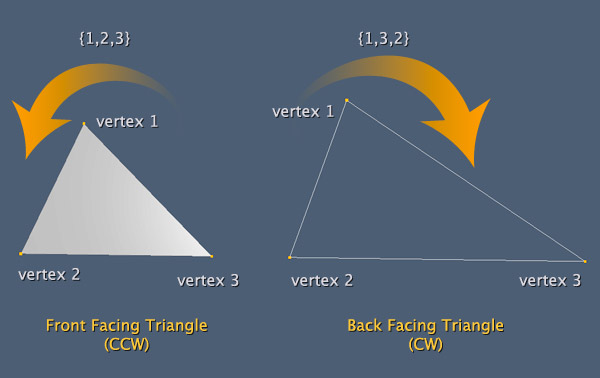
这个称为筛选的特性是完全灵活的,你至少有三种方式来做同样的事。上面的图只是展示一种方式,但最重要的理解如何工作。在上图的例子中,一个三角形由顶点1、顶点2、顶点3组成。左边的三角形构成的顺序是{1,2,3},右边形成的顺序是{1,3,2}。默认在面剔除的时候以逆时针方向为正面且不会被剔除。遵循这同样的行为,上图右边的图片,三角形以顺时针形成,被当作背面将会被剔除(在栅格化时被忽略)。为了使用这个特性,你需要使用glEnable函数且使用参数GL_CULL_FACE,默认行为如上面所述。如果你想自定义,可以使用这些函数:
// Cull Face properties
GLvoid glCullFace(GLenum mode)
* mode: 表明哪个面将被剔除。参数值可能为:
- GL_BACK: 忽略背面,默认行为
- GL_FRONT: 忽略正面
- GL_FRONT_AND_BACK:忽略正面和背面(不要问我为什么有人想剔除双面,即使知道这不会产生渲染,直到今天,我仍在试图找出这个愚蠢设置的原因)
GLvoid glFrontFace(GLenum mode)
* mode: 表明OpenGL如何定义正面(明显也包括背面),参数值可能为:
- GL_CCW: 指示OpenGL以逆时针方向形成正面三角形,默认行为
- GL_CW: 指示OpenGL以顺时针方向形成正面三角形
正如你所想的,如果你同时设置glCullFace(GL_FRONT)和glFrontFace(GL_CW)将同样获得默认行为。另一种方法改变默认行为是改变3D对象组成的顺序,这是非常费劲的,因为需要你去改变数组的索引。面剔除是栅格化发生的第一步,决定一个片段着色器下一步是否要处理。
片段操作
现在我们来完善下此篇教程顶部的可编程管线图表,尤其是片段着色器处理的后部分。
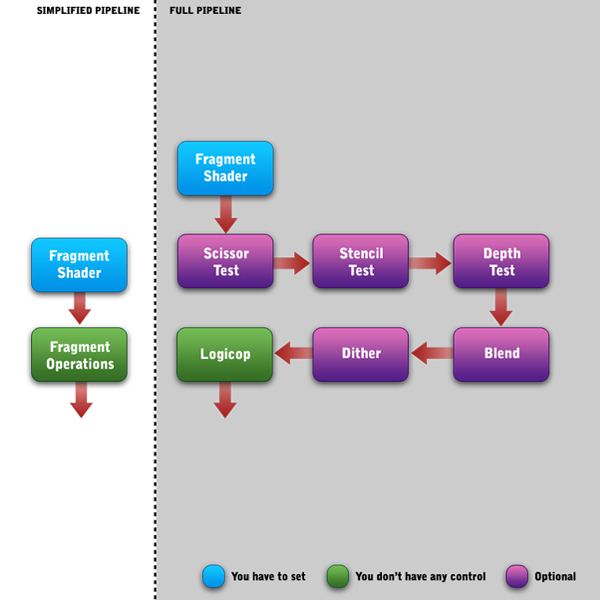
在片段着色器与剪刀测试之前存在一个小的省略步骤。所谓的“像素所有权测试”。这是内部的一个小步骤。将决定OpenGL内部的帧缓冲和当前EGL上下文之间像素的所有权。对我们来说这步不重要。你不能用它来做任何事,我告诉你,让你知道内部会发生什么。对于我们开发者,这步完全可以忽略。如你所看到的,只有Logicop这步你不能访问。Logicop是一个内部过程,它包括诸如钳们到0.0-1.0范围,在所有的每个片段操作之后处理帧缓冲区的最终颜色,额外的多采样和其它类型的内部事情。你不需要担心那个。我们只需专注于紫色的模块。紫色模块表明默认过程是不启用的,如果你想使用它们,需要你使用glEnable函数去启用它们每一个。你再看看glEnable参数,为了让这一点更清楚,简而言之,图中的紫色模块代表了以下参数和方法:
- Scissor Test: GL_SCISSOR_TEST - 裁剪图片,每个裁剪区域外面的片段将被忽略。
- Stencil Test: GL_STENCIL_TEST - 与遮罩类似,遮罩由一个黑白图像定义,其中白色像素代表可见区域。因此放在黑色区域的每个片段都将被忽略。这需要一个模板渲染缓冲区来工作。
- Depth Test: GL_DEPTH_TEST - 比较当前3D对象的Z的深度与之前已经渲染对象的Z的深度。片段的深度比另一个深将被忽略(就是说离观察者更远)。这将使用灰度图像来完成。这需要一个深度渲染缓冲区来工作。
- Blend: GL_BLEND - 混合新的片段与已经存在片段到颜色缓冲区
- Dither: GL_DITHER - 这是OpenGL的一个小技巧。在帧缓冲可用颜色有限的系统中,这上步可以优化颜色的使用,使其看起来比实际颜色更多。Dither没有配置,你只需要选择是不使用它。
对于它们每一个,OpenGL提供了几个函数像glScissor,glBlendColor,glStencilFunc设置过程。有超过10个函数,我不会在这里讨论它们,也许在另一篇文章中。这里要理解过程才是重要的事情。我已经告诉你了默认的行为,像模板缓冲区的黑色与白色,通过使用那些函数你可以自定义处理,像在模板缓冲区改变黑白颜色的行为。再回看最上面的可编程管线。每次你渲染一个3D对象,整个管线将从glDraw*直到帧缓冲区,但不进入EGL API。想象一个复杂的场景,游戏场景,比如《反恐精英》。你可以渲染几十个,甚至上百个3D对象来创建一个静态图像。当你渲染第一个3D对象时,帧缓冲开始被填充。如果子序列的3D对象片段被一个或多个片段操作忽略,那么被忽略的片段将不会被放在帧缓冲区中,但请记住,这个操作不会排队已经在帧缓冲区中的片段。最后的《反恐精英》是由许多的着色器、灯光、效果和3D对象组成的2D图像。因此每个3D对象都会处理自己的顶点着色器,也有可能处理自己的片段着色器,但这并不意味着它的结果将是真正可见的。现在你理解我为什么说栅格化处理不仅包含图中简单的一步。栅格化顶点着色器与帧缓冲区间的所有步骤。现在让我们来到最重要的部分:着色器!
着色器
我们到了!3D世界伟大的发明!如果你阅读本系列教程的第一篇且本教程读到这里,我想你应该对着色器有了很好的了解和它是干什么的。为了重新唤起我们的记忆,让我们记住一点:
- 着色器使用GLSL或GLSL ES,第一个的精简版
- 着色器成对工作,顶点着色器(Vertex Shade: VSH)和片段着色器(Fragment Shader: FSH)
- 着色器对处理每次提交的渲染命令,如:`glDrawArrays`或`glDrawElements`
- VSH处理每一个顶点,如果3D对象有8个顶点,那顶点着色器将会处理8次。VSH负责确定一个顶点的最终位置。
- FSH处理对象的每个可见的片段,记住FSH在图形管线中“片段操作”前被处理,因此OpenGL不知道哪个对象在哪个对象的前面,我的意思是在其它片段后面也会被处理。FSH负责决定片段的最终的颜色
- VSH和FSH必须独立编译,通过一个程序对象连接。你可以矸多个程序对象中重用着色器,但在每个程序对象只能连接一种类型的着色器(VSH&FSH)。
着色器和程序创建
好的,首先我们来讨论下创建一个着色对象的过程,写一些代码并编译它。像其它任何OpenGL的对象,我们首先创建一个 name/id给它,然后设置属性。与其它OpenGL对象相比较,额外的过程就是要编译。记住着色器要被CPU处理,同时优化OpenGL编译源代码到二进制格式的过程。另外,如果你有一个之前编译过的二进制文件着色器,你可以直接加载它,而不是加载源文件并编译。但现在让我们关注于编译过程。这些函数是着色器创建过程相关:
// Shader Object Creation
GLuint glCreateShader(GLenum type)
* type: 表明哪种类型的着色器将被创建。参数值可能为:
- GL_VERTEX_SHADER: 顶点着色器
- GL_FRAGMENT_SHADER: 片段着色器
GLvoid glShaderSource(GLuint shader, GLsizei count, const GLchar **string, const GLint *length)
* shader: 通过函数`glCreateShader`生成的着色器的 name/id
* count: 表明一次你传多少资源。如果上传仅一个着色资源,此值必须为1。
* string: 着色器的来源。此参数是一个二重指针,因为你可能传入一个C字符串数组,每个元素代表一个来源。指针数组的长度上面的`count`值要相同
* length: 一个指向数组指针,该数组的每个元素代表上面参数每个C字符串中字符的数量。此数组元素数量必须与上面参数`count`相同。此参数可以为`NULL`。在这种情况下,上面参数`string`中的每个元素都必须以null结尾。
GLvoid glCompileShader(GLuint shader)
* shader: 由函数`glCreateShader`生成的着色器的 name/id
如你所见,这步很简单。你创建了一个 name/id 着色器,将源代码上传到上面编译它。如果你上传源代码到一个已经有源代码在上面的,旧的源代码将会被完整的替换。一旦着色器已经被编译了,你不能再使用glShaderSource来改变源代码。每个着色器对象有一个GLboolean状态是否已经编译。如果变个着色器编译成功,这个状态会被设置成TRUE。在检查着色器是否正确的编译,这个状态在应用的调试状态下非常有用。与此检查一起,查询提供的信息日志是一个好办法。函数glGetShaderiv获取状态,函数glGetShaderInfoLog获取状态信息。我将不把函数和参数放在这里,我将在代码中简短的展示。重要的告诉你OpenGL names/ids 保留给着色器是一个单一的列表。如:你生成了一个 name/id 为1数字的VSH,将不会再被用到,如果现在创建一个FSH,它的name/id可能是2或其它。不可能VSH与FSH有一个同样的 name/id,反之亦然。当你有一对着色器正确编译,是时候创建一个程序对象将着色器放入其中。创建程序对象的过程与创建着色器的过程相似。首先创建一个程序对象,然后上传一些东西(目前情况下,是将编译的着色器放入其中),最终编译程序(这里我们不用“编译”这个词,用“链接”)。程序将要被链接什么?程序将要链接着色器对,同时链接它自身到OpenGL内核。这个过程非常重要,因为在这个过程中会发生许多对着色器的验证。正如着色器一样,程序也有一个链接状态和链接日志信息用来检查错误。一旦程序链接成功,你就可以确定:你的着色器将会正确的工作。下面是程序对象的函数:
// Program Object Creation
GLuint glCreateProgram(void)
* 此函数不需要参数。这是因为只存在一种类型的程序对象,不像着色器。此外,这个函数将直接返回 name/id ,而不是将内存位置取为一个变量,这种不同的行为是因为你不能一次创建多个程序对象,因此你不需要通知指针。
GLvoid glAttachShader(GLuint program, GLuint shader)
* program: 由`glCreateProgram`函数生成的程序的 name/id
* shader: 由`glCreateShader`函数生成的着色器的 name/id
GLvoid glLinkProgram(GLuint program)
* program: 由`glCreateProgram`函数生成的程序的 name/id
在glAttachShader函数中没有参数区分着色器是顶点还是片段着色器。你记得着色器的 names/ids 是单一列表,是吗?OpenGL会根据它们的唯一的 names/ids 自动区分着色器的类型。因此重要的部分你要调用glAttachShader两次,一次是给VSH,另一次给FSH。如果你连接两个VSH或FSH,程序不会被正确的链接,同样如果连接超过两个着色器,程序会链接失败。你可以创建多个程序,但当你调用一个glDraw*时OpenGL如何知道使用哪个程序?OpenGL的起重机没有手臂和挂钩程序对象,对吗?那OpenGL怎样知道?嗯,程序是我们的例外。OpenGL没有一个函数去绑定它,但程序与钩子一样一起工作。当你想使用一个程序调用这个函数:
// Program Object Usage
GLvoid glUseProgram(GLuint program)
* program: 由`glCreateProgram`函数生成的程序的 name/id
在调用上面的函数之后,每个子程序调用glDraw*函数将使用当前正在使用的程序。如其它的glBind*函数, name/id 0为OpenGL保留,如果你调用glUseProgram(0)这个将会解绑任意当前的程序。现在是代码时间,任何你创建的OpenGL应用将有类似下面的代码:
GLuint _program;
GLuint createShader(GLenum type, const char **source) {
GLuint name;
// Create a Shaer Object and returns its name/id.
name = glCreateShader(type);
// Uploads the source to the Shader Object
glShaderSource(name, 1, &source, NULL);
// Compiles the Shader Objetc
glCompileShader(name);
// If you are running in debug mode, query for info log.
// DEBUG is a pre-processing Macro defined to the compiler.
// Some languages could not has a similar to it.
#if define(DEBUG)
GLint logLength;
// Instead use GL_INFO_LOG_LENGTH we could use COMPILE_STATUS.
// I prefer to take the info log length, because it'll be 0 if the
// shader was successful compiled. If we use COMPILE_STATUS
// we will need to take info log length in case of a fail anyway.
glGetShaderiv(name, GL_INFO_LOG_LENGTH, &logLength);
if (logLength > 0) {
// Allocates the necessary memory to retrieve the message.
GLchar *log = (GLchar *)malloc(logLength);
// Get the info log message.
glGetShaderInfoLog(name, logLength, &logLength, log);
// Shows the message in console.
print("%s", log);
// Frees the allocated memory.
free(log);
}
#endif
return name;
}
GLuint createProgram(GLuint vertexShader, GLuint fragmentShader) {
GLuint name;
// Creates the program name/index.
name = glCreateProgram();
// Will attach the fragment and vertex shaders to the program object.
glAttachShader(name, vertexShader);
glAttachShader(name, fragmentShader);
// Will link the program into OpenGL's core.
glLinkProgram(name);
#if define(DEBUG)
GLint logLength;
// This function is different than the shaders one.
glGetProgramiv(name, GL_INFO_LOG_LENGTH, &logLength);
if (logLength > 0) {
GLchar *log = (GLchar *)malloc(logLength);
// This function is different than the shaders one.
glGetProgramInfoLog(name, logLength, &logLength, log);
printf("%s", log);
free(log);
}
#endif
return name;
}
void initProgramAndShaders() {
const char *vshSource = "...Vertex Shader source using SL...";
const char *fshSource = "...Fragment Shader source using SL...";
GLuint vsh, fsh;
vsh = createShader(GL_VERTEX_SHADER, &vshSource);
fsh = createShader(GL_FRAGMENT_SHADER, &fshSource);
_program = createProgram(vsh, fsh);
// Clears the shaders objects.
// In this case we can delete the shader because we
// will not use they anymore and once compiled,
// the OpenGL stores a copy of they into the program object.
glDeleteShader(vsh);
glDeleteShader(fsh);
// Later you can use the _program variable to use this program.
// If you are using an Object Oriented Programming is better make
// the program variable an instance variable, otherwise is better make
// it a static variable to reuse it in another functions.
// glUseProgram(_program);
}
在这里我做了一些简单的阐述,使它更易于重用,分离了创建OpenGL对象的函数。例如:为了避免重写着色器创建代码,我们可以简单调用函数createShader,并告之我们想要的着色器类型和它的来源。程序也是一样。当然如果你使用的是OOP语言,你可以更详细说明,为程序对象和着色器对象创建一个独立的类。这是关于着色器和程序创建的基本知识,但我们还有更多要看的。让我们来到着色器语言(Shader Language: SL)。我将特别讨论GLSL ES,它是面向嵌入式系统的OpenGL着色器语言的精简版本。
着色器语言
着色器语言与标准C相似。变量声明和函数语法也相同,
if-else和循语法也相同,SL甚至可以接收预编译宏,像:#if,#ifdef,#define等其它。着色器语言被设计的尽可能快。所以要小心使用循环和条件,他们使用非常广泛。记着色器通过GPU处理,浮点数的计算被优化。为了探索这一伟大的改进,SL拥有与3D世界一起工作独特的数据类型:
| SL's Data Type | Same as C | Description |
|---|---|---|
| void | void | Can represent any data type |
| float | float | The range depends on the precision |
| bool | unsigned char | 0 to 1 |
| int | char/short/int | The range depends on the precision |
| vec2 | - | Array of 2 float. {x, y}, {r, g}. |
| vec3 | - | Array of 3 float. {x, y, z}, {r, g, b}. |
| vec4 | - | Array of 4 float. {x, y, z, w}, {r, g, b, a}. |
| bvec2 | - | Array of 2 bool. {x, y}, {r, g}. |
| bvec3 | - | Array of 3 bool. {x, y, z}, {r, g, b}. |
| bvec4 | - | Array of 4 bool. {x, y, z, w}, {r, g, b, a}. |
| ivec2 | - | Array of 2 int. {x, y}, {r, g}. |
| ivec3 | - | Array of 3 int. {x, y, z}, {r, g, b}. |
| ivec4 | - | Array of 4 int. {x, y, z, w}, {r, g, b, a}. |
| mat2 | - | Array of 4 float. Represent a matrix of 2 * 2 |
| mat3 | - | Array of 9 float. Represent a matrix of 3 * 3 |
| mat4 | - | Array of 16 float. Represent a matrix of 4 * 4 |
| sampler2D | - | Special type to access a 2D texture |
| samplerCube | - | Special type to access a Cube texture(3D texture) |
所有向量数据类型(vec, bvec及ivec*)都可以通过 .语法或者数组下标[x]访问。在上面的表中,你可以看到序列{x, y, z, w}, {r, g, b, a}, {s, t, r, q}。
它们是向量元素的访问器。例如:.xyz可以代表vec4的前3个元素,但你不能在vec2中使用.xyz,因为超出了边界,在vec2中只能使用.xy。你也可以改变顺序获取你想要的结果,如:.yzx在vec4要查询第二个、第三个和第一个元素。有三个不同序列的原因是因为vec数据类型可以被用来代表向量(x, y, z, w),颜色(r, g, b, a),甚至可以代表纹理坐标(s, t, r, q)。重要的是你不能混合这些集合,如不能使用.xrt。下面的例子将帮助理解:
vec4 myVec4 = vec4(0.0, 1.0, 2.0, 3.0);
vec3 myVec3;
vec2 myVec2;
myVec3 = myVec4.xyz; // myVec3 = {0.0, 1.0, 2.0};
myVec3 = myVec4.zzx; // myVec3 = {2.0, 2.0, 0.0};
myVec2 = myVec4.bg; // myVec2 = {2.0, 1.0};
myVec4.xw = myVec2; // myVec4 = {2.0, 1.0, 2.0, 1.0};
myVec4[1] = 5.0; // myVec4 = {2.0, 5.0, 2.0, 1.0};
很简单吧。现在关于转换,你需要注意的一些事。SL使用一个被称作Prcision Qualifiers定义数据类型最大最小值的范围。精确限定符是一些小指令,你可以在任何变量声明前使用它。与任何数据范围一样,迹取决于硬件容量。下面的表是关于SL的最小范围。一些提供商可以增加范围:
| Precision | Floating Point Range | Integer Ranger |
|---|---|---|
| lowp | -2.0 to 2.0 | -256 to 256 |
| mediump | -16384.0 to 16384.0 | -1024 to 1024 |
| highp | -4611686018427387904.0 to 4611686018427387904.0 | -65536 to 65536 |
代替在每个变量前面声明一个标识符,你可以通过关键字precision定义一个全局标识符。当你需要在数据类型之间进行转换时,精度限定符可以提供帮助。如:将一个float转换为int,你应该使用一个 mediump float 和 lowp int,如果是将lowp float转换为lowp int,那所有的结果都将在 -2 到 2之间的整数。为了转换你必须使用内置的函数转换为期望的类型。下面的代码会提供帮助。
precison mediump float;
precision lowp int;
vec4 myVec4 = vec4(0.0, 1.0, 2.0, 3.0);
ivec3 myIvec3;
mediump ivec2 myIvec2;
// This will fail. Because the data types are not compatible.
// myIvec3 = myVec4.zyx;
myIvec3 = ivec3(myVec4.zyx); // This is OK
myIvec2.x = myVec3.y; // This is OK
myIvec2.y = 1024;
// This is OK too, but the myIvec3.x will assume its maximum value.
// Instead 1024, it will be 256, because the precisions are not equivalent here.
myIvec3.x = myIvec2.y;
直接在GPU上工作的一大优势浮点数运算的性能的提高。你可以做乘法或者浮点数的其它的运算非常简单。当然,矩阵类型、向量类型和浮点类型完全兼容,它们的维数是一致的。你可以在一行中进行复杂的计算,比如矩阵的乘法,像这些:
mat4 myMat4;
mat3 myMat3;
vec4 myVec4 = vec4(0.0, 1.0, 2.0, 3.0);
vec3 myVec3 = vec3(-1.0, -2.0, -3.0);
float myFloat = 2.0;
// A mat4 has 16 elements, could be constructed by 4 vec4
myMat4 = mat4(myVec4, myVec4, myVec4, myVec4);
// A float will multiply each vector value
myVec4 = myFloat * myVec4;
// A mat4 multiplying a vec4 will result in a vec4
myVec4 = myMat4 * myVec4;
// Using the accessor, we can multiply two vector of different orders
myVec4.xyz = myVec3 * myVec4.xyz;
// A mat3 produced by a mat4 will take the first 9 elements.
myMats = mat3(myMat4);
// A mat3 multiplying a vec3 will result in a vec3.
myVec3 = myMat3 * myVec3;
你也可以使用任意数据类型的数组,甚至像C一样构造的结构体。SL定义每个着色器必须有一个函数void main()。着色器的执行在从这个函数开始,像C一样。任何着色器没有这个函数将编译不过。SL中的函数工作确实像C一样。请记住,SL是一种内联函数,我的意思是,如果你在调用函数前编写了一个函数,那就没有问题,否则调用将会失败。如果你有很多函数在着色器中,void main()函数一定要写在最后。现在是时候要更深入和理解顶点和片段着色器到底做什么了。
顶点和片段结构
首先,让我们看下着色器管线,然后我将介绍属性(Attributes)、不变的(Uniforms)、变化的(Varying)和内置(Built-In)函数。
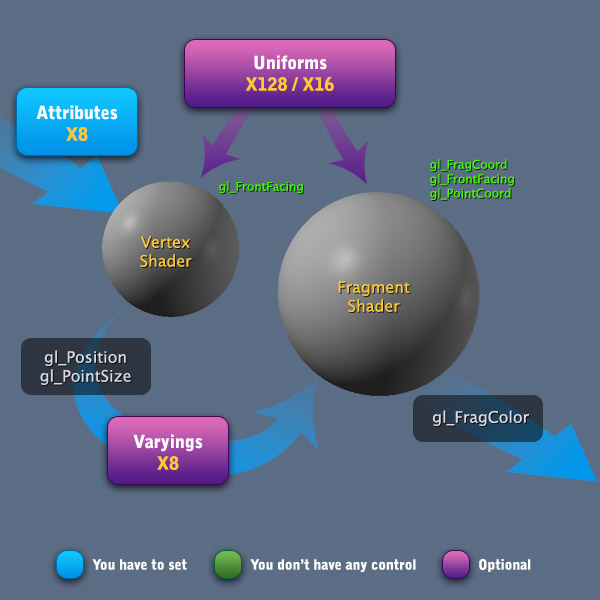
你的VSH应该总是有一个或多个属性,因为属性被用来构建3D对象的顶点,只有属性定义每个顶点。为了定义最终顶点的位置,你要使用内置的变量gl_Position。稍后,你将在FSH中设置内置变量gl_FragColor。属性、不变、变量构造了GPU处理和你的应用程序在CPU之间的桥梁。在渲染前(调用 glDraw* 函数),你可能在VSH中给属性设置一些值。这些值可以是所有顶点的常量或每个顶点不一样。默认情况下,任何实现OpenGL的可编程管线必须支持至少8个属性。你不能直接设置任意变量给FSH,你要做的设置一个输出变量给VSH,准备好你的FSH去接收那个变量。这一步是可选的,正如上图所见,但事实上,一个不接受任何变量的FSH是非常罕见的构造。默认下任何OpenGL可编程管线必须至少支持8个变量。另一种与着色器交流的方法是使用不变量,正如名字一样,不变量在整个着色器处理过程中是常量(所有顶点和片段)。对于不变量一个常用的情况下取样,你记得取样数据?它们被用来持有我们的纹理单元。你还记得纹理单元么?仅为了弄清这点,取样数据类型应该像int数据类型,但一个特殊保留的类型与纹理一起工作。就是它。每个着色器类型最小支持的不变量不同。VSH支持至少128个不变量,但FSH至少支持16个。现在关于内置的变量,OpenGL定义了一些变量,这是我们在每个着色器上必须要做的。VSH必须定义最终顶点的位置,这是通过变量gl_Position完成的,如果当前绘制的原语是一个3D点设置gl_PointSize是一个不错的办法。gl_PointSize将指示每个点将影响多少个片段,或者简单地说,3D点在屏幕上的大小。这对制作粒子效果非常有用,例如火。在VSH中有内置的只读变量,如gl_FrontFacing。这个变量是bool数据类型,它指示当前的顶点是否是正面。在FSH内置的输出变量是gl_FragColor。为了兼容OpenGL的桌面版本,gl_FragData也被使用。gl_FragData是一个与可绘制缓冲区相关的数组,但OpenGL ES内部只有一个可绘制缓冲区,这个变量必须总是以gl_FragData[0]使用。我的建议是忘记它,并专注于gl_FragColor。关于只读的内置变量,FSH有三个:gl_FrontFacing、gl_FragCoord和gl_PointCoord。gl_FrontFacing在VSH中是相等的,它是一个bool标记当前面是否是正面。gl_FragCoord是一个vec4数据类型,表明当前片段相对窗口的坐标(窗口在这里的意思是真正的OpenGL的视图)。gl_PointCoord在你渲染3D点的时候使用。假使当你指定gl_PointSize时,你可以使用gl_PointCoord来检索当前片段的纹理坐标。例如:一个点的尺寸总是以像素给定的正方形,那么大小16代表一个点由4*4像素形成。gl_PointCoord的范围是0.0-1.0,很像纹理坐标信息。最重要的内置输出变量是最终的值。所以你可以在VSH中多次改变gl_Position的值,最终的位置将是最终值。对gl_FragColor也是一样的。下面的表展示了内置的变量和类型:
| Built-In Variable | Precision | Data Type |
|---|---|---|
| Vertex Shader Built-In Variables | ||
| gl_Position | highp | vec4 |
| gl_FrontFacing | - | bool |
| gl_PointSize | mediump | float |
| Fragment Shader Built-In Variables | ||
| gl_FragColor | mediump | vec4 |
| gl_FrontFacing | - | bool |
| gl_FragCoord | mediump | vec4 |
| gl_PointCoord | mediump | vec2 |
是时候要构造一个真正的着色器。下面的代码使用两个纹理映射构建了一个顶点着色器和一个片段着色器。让我们从VSH开始吧。
precision mediump float;
precision lowp int;
uniform mat4 u_mvpMatrix;
attribute vec4 a_vertex;
attribute vec2 a_texture;
varying vec2 v_texture;
void main() {
// Pass the texture coordinate attribute to a varying.
v_texture = a_texture;
// Here we set the final position to this vertex.
gl_Position = u_mvpMatrix * a_vertex;
}
相应的FSH
precision mediump float;
precision lowp int;
uniform sampler2D u_maps[2];
varying vec2 v_texture;
void main() {
// Here we set the diffuse color to the fragment.
gl_FragColor = texture2D(u_maps[0], v_texture);
// Now we use the second texture to create an ambient color.
// Ambient color dosen't affect the alpha channel and changes
// less than half the natural color of the fragment.
gl_FragColor.rgb += texture2D(u_maps[1], v_texture).rgb * .4;
}
现在我们回到OpenGL API,准备好我们的属性和统一变量,记住我们不能直接控制变量,那么我们必须通过设置属性在VSH执行中发送给变量。
设置属性和统一量
为了识别着色器内的任何变量,程序对象定义了变量的位置(location与index相同)。一旦你知道属性或统一量的最终位置,可以使用那个位置设置它的值。为了设置统一量,OpenGL只给了我们一种方式:在链接之后,我们根据它在着色器中的名称检索到想要的统一位置。设置属性OpenGL只给了我们两种方式:可以在程序被链接后检索位置或者在程序链接之前定义位置。我将向你展示两种庐江,但在链接过程前设置位置是无用的,你将理解是为什么。让我们从无用的方法开始。你还记得glBindSomething等于“取一个容器”规则的例外么?好,就在这里。在程序链接前设置一个属性位置,我们使用一个以glBindSomething函数,但实际上OpenGL起重机臂在这个时候不会换取任何容器。这里的“绑定”一词与程序对象里的过程相关,在程序中的属性名和位置之间建立连接的过程。因此,函数是:
// Setting Attribute Location before the linkage
GLvoid glBindAttribLocation(GLuint program, GLuint index, const GLchar *name)
* program: 由glCreateProgram函数生成的程序的 name/id
* index: 我们想设置的位置
* name: 顶点着色器内部属性的名字
上面的方法必须在创建程序对象后但要在链接前调用。这是我不鼓励你这么做的第一个原因。是程序对象创建的中间过程。明显你可以为你的应用选择更好的方法。我更喜欢接下来这个。让我们看看怎样在链接过程后如何获取属性和统一量的位置。无论选择哪种方法,你必须在应用的每个着色器变量中持有位置。因为你将需要这些位置在稍后设置它的值。下面的函数在链接后使用:
// Getting Attribute and Uniform Location
GLint glGenAttribLocation(GLuint program, const GLchar *name)
* program: glCreateProgram生成的程序的 name/id
* name: 顶点着色器内部属性的名字
GLint glGetUniformLocation(GLuint program, const GLchar *name)
* program: glCreateProgram生成的程序的 name/id
* name: 顶点着色器内部统一量的名字
我们有了属性和统一量的位置,我们可以使用这些位置去设置我们想要的值。OpenGL给我们提供了28个不同的函数去设置我们的属性和统一量的值。这些函数独立分组,让你定义常量(统一量和属性)或动态值(仅属性)。为使用动态属性你需要启用它们一会儿。你可以询问统一量(一般总是常量)与常量属性间的区别。嗯,答案是:好问题!就像面剔除的GL_FRONT_AND_BACK,这是我不理解为什么OpenGL继续使用它。在统一量和常量属性上,或者在内存大小和这些影响上没有真正的区别。那我强烈的建议是:让属性只有动态值。如果你有一个常量值,使用统一量。此外,还有两件事情是使用统一量成为常数值的最佳选择:统一量在顶点着色器中可以使用128次,属性只能使用8次,另一个原因是属性不能是数组。我稍后解释这个事实。现在,尽管默认情况OpenGL使用属性作为常量,它们不是为这个目的而造的,是为动态而设计的。总之,我将展示如何设置动态属性、统一量甚至无用的属性常量。统一量可以使用任意的数据类型、结构体或数组。下面是设置统一量值的函数:
// Define the Uniforms Values
GLvoid glUniform{1234}{if}(GLint location, T value[N])
* location: 从glGetUniformLocation获取的统一量位置
* value[N]: 基于函数名字的最后一个字母,i=GLint, f=GLfoat想设置的值。你必须重复设置参数N次,根据函数名字中的{1234}
GLvoid glUniform{1234}{if}v(GLint location, GLsizei count, const T *value)
* location: 从glGetUniformLocation获取的统一量位置
* count: 要设置的数组的长度。可能是1,如果你想设置一个单一的统一量。值大于1表示想组数组设置值。
* value: 你想设置数据的指针。如果设置向量统一量(如vec3),每3个值的集合代表着色器中的一个vec3。数据类型必须匹配函数名字中的字母,i=GLint,f=GLfoat
GLvoid glUniformMatrix{234}fv(GLint location, GLsizei count, GLboolean transpose, const GLfloat *value)
* location: 从glGetUniformLocation获取的统一量位置
* count: 要设置的矩阵的数量。可能为1,如果你只想设置一个mat{234}进入着色器。值大于1说明你想给矩阵数组设置值,在着色器中的定义类似:mat{234}["count"]
* transpose: 此值必须为GL_FALSE,内部约定只为桌面兼容
* value: 你的数据指针
有很多疑问,让我一个一个解释。上面的代码展示了实际上有19个OpenGL函数。记号{1234}表明你必须要在函数名字中写一个数字,紧跟着的{if}表明你要选择一个字母写在函数名字中,最后的fv中的v表明无论如何你都要写一个。参数中的[N]表明你必须根据函数名字中的{1234}重复那个参数,下面是19个函数的完整列表
| 19 Functions |
|---|
| glUniform1i(GLint location, GLint x) |
| glUniform1f(GLint location, GLfloat x) |
| glUniform2i(GLint location, GLint x, GLint y) |
| glUniform2f(GLint location, GLfloat x, GLfloat y) |
| glUniform3i(GLint location, GLint x, GLint y, GLint z) |
| glUniform3f(GLint location, GLfloat x, GLfloat y, GLfloat z) |
| glUniform4i(GLint location, GLint x, GLint y, GLint z, GLint w) |
| glUniform4f(GLint location, GLfloat x, GLfloat y, GLfloat z, GLfloat w) |
| glUniform1iv(GLint location, GLsizei count, const GLint *v) |
| glUniform1fv(GLint location, GLsizei count, const GLfloat *v) |
| glUniform2iv(GLint location, GLsizei count, const GLint *v) |
| glUniform2fv(GLint location, GLsizei count, const GLfloat *v) |
| glUniform3iv(GLint location, GLsizei count, const GLint *v) |
| glUniform3fv(GLint location, GLsizei count, const GLfloat *v) |
| glUniform4iv(GLint location, GLsizei count, const GLint *v) |
| glUniform4fv(GLint location, GLsizei count, const GLfloat *v) |
| glUniformMatrix2fv(GLint location, GLsizei count, GLboolean transpose, const GLfloat *value) |
| glUniformMatrix3fv(GLint location, GLsizei count, GLboolean transpose, const GLfloat *value) |
| glUniformMatrix4fv(GLint location, GLsizei count, GLboolean transpose, const GLfloat *value) |
哇!从这个角度看,似乎有很多函数要学习,但相信我,不是这样的。我更喜欢那张表。如果我想设置一个不是矩阵数据类型统一量,我根据想要的使用glUniform{1234}{if},1=float/bool/int,2=vec2/bvec2/ivec2,3=vec3/bvec3/ivec3,4=vec4/bvec4/ivec4。很简单!如果我想设置一个数组,我只是把v(vector)放在我最后一个,我将用glUniform{1234}{if}v。如果最终我想设置一个矩阵数据类型,一个数组或不是,我确认根据我想要的2=mat2,3=mat3,4=mat4会用glUniformMatrix{234}fv。定义一个数组,你需要记住必须通过形参计数将数组的计数通知给上述函数之一。看起来更简单。对吗?这就是所有关于设置统一变量到着色器中。记住两件重要的事情:相同的统一量可以被两个着色器使用,要做到这一点,只要在两个中声明它。第二个是最重要的,统一量会被设置到当前使用的程序对象。因此你必须在开始使用一个程序前设置统一量和属性值给它。你记得为了使用程序对象,对吗?只用调用glUseProgram通知期望的name/id。现在让我们看怎样设置值到属性。属性仅可以使用数据类型float,vec2,vec3,vec4,mat2,mat3和mat4。属性不能被声明为数组或者结构体。跟随下面的函数来定义属性值。
// Define the Attributes Values
GLvoid glVertexAttrib{1234}f(GLuint index, GLfloat value[N])
* index: 通过glGetAttribLocation函数或定义glBindAttribLocation获取属性的位置
* value[N]: 想设置的值。你必须根据函数名字中{1234}重复此参数N次
GLvoid glVertexAttrib{1234}fv(GLuint index, const GLfloat *values)
* index: 通过glGetAttribLocation函数或定义glBindAttribLocation获取属性的位置
* values: 指向数组的指针,包含想设置的值。只有在数组中必要的元素将被使用,例如:设置一个vec3的情况下,如果你通知一个有四个元素,只会使用前面三个元素。如果着色器要自动填充,将使用vec4的恒等式,例如,在设置一个vec3的情况下,如果你通知一个2个元素的数组,第三个元素将会用0填充。对于矩阵,自动填充使用矩阵单位。
GLvoid glVertexAtribPointer(GLuint index, GLint size, GLenum type, GLboolean normalized, GLsizei stride, const GLvoid *ptr)
* index: 通过glGetAttribLocation函数或定义glBindAttribLocation获取属性的位置
* size: 每个元素的大小,值可能为:
- 1: 在着色器中设置float
- 2: 在着色器中设置vec2
- 3: 在着色器中设置vec3
- 4: 在着色器中设置vec4
* type: 指定在通知的数组中使用的OpenGL数据类型,值可能为:
- GL_BYTE
- GL_UNSIGNED_BYTE
- GL_SHORT
- GL_UNSIGNED_SHORT
- GL_FIXED
- GL_FLOAT
* normalized: 如果设置为true(GL_TRUE)将规范化浮点数据类型。规范的过程将转换浮点数的范围在0.0-1.0。如果设置为false(GL_FALSE),非浮点数据类型将被直接转换成浮点类型
* stride: 它表示已知数组中的元素的间隔。如果为0,数组中的元素将按顺序使用。如果此值大于0,数组中的元素将按步调使用。这个值必须以基础机器的单元(bytes)。
* ptr: 包含数据的数组的指针
上表与统一量的表示法规则相同。上面的表描述了9个函数,有8个设置常量,只有一个设置动态值。设置动态值的是glVertexAttribPointer。下面是完整的函数列表:
| 9 Functions |
|---|
| glVertexAttrib1f(GLuint index, GLfloat x) |
| glVertexAttrib2f(GLuint index, GLfloat x, GLfloat y) |
| glVertexAttrib3f(GLuint index, GLfloat x, GLfloat y, GLfloat z) |
| glVertexAttrib4f(GLuint index, GLfloat x, GLfloat y, GLfloat z, GLfloat w) |
| glVertexAttrib1fv(GLuint index, const GLfloat *values) |
| glVertexAttrib2fv(GLuint index, const GLfloat *values) |
| glVertexAttrib3fv(GLuint index, const GLfloat *values) |
| glVertexAttrib4fv(GLuint index, const GLfloat *values) |
| glVertexAttribPointer(GLuint index, GLint size, GLenum type, GLboolean normalized, GLsizei stride, const GLvoid *ptr) |
这里烦人的事情是常量值是着色器的默认行为,如果你想使用动态值属性,你需要临时启用这个特性。动态值为每个顶点设置。你要使用下面的函数去启用或禁用动态值的行为:
// Variable Values Feature
GLvoid glEnableVertexAttribArray(GLuint index)
* index: 通过glGetAttribLocation函数或定义glBindAttribLocation获取属性的位置
GLvoid glDisableVertexAttribArray(GLuint index)
* index: 通过glGetAttribLocation函数或定义glBindAttribLocation获取属性的位置
在使用glVertexAttribPointer定义每个顶点的值给属性,你必须启用期望的属性位置接收动态值,通过使用glEnableVertexAttribArray。对于前面显示的一对VSH和FSH,我们可以使用下面的代码来设置它们的值:
// Assume which _program defined early in another code example.
GLuint mvpLoc, mapsLoc, vertexLoc, textureLoc;
// Gets the locations to uniforms
mvpLoc = glGetUniformLocation(_program, "u_mvpMatrix");
mapsLoc = glGetUniformLocation(_program, "u_maps");
// Gets the locations to attributes
vertexLoc = glGetAttribLocation(_program, "a_vertex");
textureLoc = glGetAttribLocation(_program, "a_texture");
// ...
// Later, in the render time...
// ...
// Sets the ModelViewProjection Matrix.
// Assume which "matrix" variable is an array with
// 16 elements defined, matrix[16]
glUniformMatrix4fv(mvpLoc, 1, GL_FALSE, matrix);
// Assume which _texturel and _texture2 are two texture names/ids
// The order is very important, first you activate
// teh texture unit and then you bind the texture name/id
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, _texture1);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, _texture2);
// The {0, 1} correspond to the activated textures units.
int textureUnits[2] = {0, 1};
// Sets the texture units to an uniform
glUniform1iv(mapsLoc, 2, &textureUnits);
// Enables the following attributes to use dynamic values.
glEnableVertexAttribArray(vertexLoc);
glEnableVertexAttribArray(textureLoc);
// Assume which "vertexArray" variable is an array of vertices
// composed by several sequences of 3 elements (X, Y, Z)
// Something like {0.0, 0.0, 0.0, 1.0, 2.0, 1.0, -1.0, -2.0, -1.0, ...}
glVertexAttribPointer(vertexLoc, 3, GL_FLOAT, GL_FALSE, 0, vertexArray);
// Assume which "textureArray" is an array of texture coordinate
// composed by several sequences of 2 elements (S, T)
// Something like {0.0, 0.0, 0.3, 0.2, 0.6, 0.3, 0.3, 0.7, ...}
glVertexAttribPointer(textureLoc, 2, GL_FLOAT, GL_FALSE, 0, textureArray);
// Assume which "indexArray" is an array of indices
// Something like {1, 2, 3, 1, 3, 4, 3, 4, 5, 3, 5, 6, ....}
glDrawElements(GL_TRIANGLES, 64, GL_UNSIGNED_SHORT, indexArray);
// Disable the vertices attributes
glDisableVertexAttribArray(vertexLoc);
glDisableVertexAttribArray(textureLoc);
我仅仅展示怎样去已启用和禁用给属性动态值。如我前面所说,启用和禁用特性在OpenGL是非常广泛的任务,因此,你可能希望只启用一次属性的动态值,比如在获得其位置后,我更愿只启用一次。
使用缓冲对象
使用缓冲图像非常简单!所有你要做的就是再次绑定缓冲对象。你还记得缓冲对象钩子是一个双钩?因此你可以同时绑定一个GL_ARRAY_BUFFER和一个GL_ELEMENT_ARRAY_BUFFER。然后你调用glDraw*通知要启动的缓冲区对象的起始索引。你要通知起始索引而不是数组数据,因此开始的数字必须是指向void的指针。起始索引必须以基本机器单元(bytes)为单位。上面关于属性和统一量的代码,你可以写成这样:
GLuint arrayBuffer, indicesBuffer;
// Generates the name/ids to the buffers
glGenBuffers(1, &arrayBuffer);
glGenBuffers(1, &indicesBuffer);
// Assume we are using the best practice to store all informations about
// the object into a single array: vertices and texture coordinates
// So we could have an array of {x,y,z,s,t, x,y,z,s,t, ...}
// This will be our "arrayBuffer" variable.
// To the "indicesBuffer" variable we use a
// simple array{1,2,3, 1,3,4, ...}
// ...
// Proceed with the retrieving attributes and uniforms locations.
// ...
// ...
// Later, in the render time...
// ...
// ...
// Uniforms definitions
// ...
glBindBuffer(GL_ARRAY_BUFFER, arrayBuffer);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFFER, indicesBuffer);
int fsize = sizeof(float);
GLsizei str = 5 * fsize;
void * void0 = (void *)0;
void * void3 = (void *)3 * fsize;
glVertexAttribPointer(vertexLoc, 3, GL_FLOAT, GL_FALSE, str, void0);
glVertexAttribPointer(textureLoc, 2, GL_FLOAT, GL_FALSE, str, void3);
glDrawElements(GL_TRIANGLES, 64, GL_UNSIGNED_SHORT, void0);
如果你使用的是OOP语言,你可以用缓冲区对象和属性、统一量的概念创建优雅的结构。这些都是关于着色器和程序对象的基本的概念和说明。我们终于快到最后一部分。让我们看看总结使用EGL API渲染。
渲染
我会展示基本的渲染,渲染到设备的屏幕。在这个系列指导前你注意到,你可以渲染到离屏的面像一个帧缓冲区或一个纹理,然后保存到一个文件,或者创建一个图像在设备的屏幕上。
渲染前
我认为渲染中分为二步。第一步是渲染前,在这步中你需要清理前面渲染的遗留。这一点非常重要,因为在帧缓冲区要保持守恒。你记得帧缓冲区是什么吗?一组来自渲染缓冲区的图像。因此你做一个完整的渲染,图像在渲染缓冲区仍然存活即使最终图像已经呈现到期望的平面。渲染前步骤做的是清理所有渲染缓冲区。除非你因为某些原因想要,重用之前的图像到渲染缓冲区。清理帧缓冲区是非常简单。下面是将使用到的函数:
// Clearing the Render Buffers
Glvoid glClear(GLbitfield mask)
* mask: 代表你想清理的缓冲区,值可能为:
- GL_COLOR_BUFFER_BIT: 清除颜色缓冲区
- GL_DEPTH_BUFFER_NIT: 清除深度缓冲区
- GL_STENCIL_BUFFER_BIT: 清除模板缓冲区
现在你已经很清楚了,与一个起重机挂钩相关的每个指令都将影响最后一个对象绑定。那么在调用上面的函数之前,确保你已经绑定了期望的帧缓冲区。你可以一次性清理很多缓存,由于mask参数是位信息,你可以使用位运算|。像下面这样:
glBindFramebuffer(GL_FRAMEBUFFER, _frameBuffer);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
OpenGL也给我们提供了其它清理的函数。但上面的函数对任何情况都很好。渲染前的步骤在调用任意glDraw*之前调用。一旦渲染缓冲区被清理,就是绘制3D对象的时候。下一步就是绘制阶段,但不是我前面告诉你的两步渲染中的一步,只是绘制。
绘制中
在这篇教程前我已经展示了几次,但现在是时候深入挖掘了。在OpenGL中触发绘制由两个函数组成:
// Clearing the Render Buffers
GLvoid glDrawArrays(GLenum mode, GLint first, GLsizei count)
* mode: 此参数指定哪个原语将被渲染及它的结构组成。参数可能为:
- GL_POINT: 绘制点。点由3个值(x,y,z)的单一序列组成
- GL_LINES: 线由两个包含3个值的序列组成。
- GL_LINE_STRIP: 绘制一个线形成带。线由两个3个值(x,y,z)的序列组成
- GL_LINE_LOOP: 画出闭合的线,线由两个3个值的序列组成
- GL_TRIANGLES: 绘制三角形。三角形由3个值的3个序列组成
- GL_TRIANGLE_FAN: 绘制三角形形成扇形。三角形由3个值组成的3个序列组成
* first: 指定启用的顶点数组的起始索引
* count: 代表要绘制的顶点数。这个非常重要,代表顶点元素的数量,不是顶点数组中元素的数量,要注意不能混淆两者。例如:如果你绘制一个单一三角形,需要3个点,因为一个三角形由3个点组成。但如果你想绘制一个正方形(由两个三角形组成),这应该要6个点,因为由两个3个点的序列组成,总共6个元素,等等
GLvoid glDrawElements(GLenum mode, GLsizei count, GLenum type, const GLvoid *indices)
* mode: 此参数指定哪个原语将被渲染及它的结构组成。参数可能为:
- GL_POINT: 绘制点。点由3个值(x,y,z)的单一序列组成
- GL_LINES: 线由两个包含3个值的序列组成。
- GL_LINE_STRIP: 绘制一个线形成带。线由两个3个值(x,y,z)的序列组成
- GL_LINE_LOOP: 画出闭合的线,线由两个3个值的序列组成
- GL_TRIANGLES: 绘制三角形。三角形由3个值的3个序列组成
- GL_TRIANGLE_FAN: 绘制三角形形成扇形。三角形由3个值组成的3个序列组成
* count: 代表要绘制的顶点数。这个非常重要,代表顶点元素的数量,不是顶点数组中元素的数量,要注意不能混淆两者。例如:如果你绘制一个单一三角形,需要3个点,因为一个三角形由3个点组成。但如果你想绘制一个正方形(由两个三角形组成),这应该要6个点,因为由两个3个点的序列组成,总共6个元素,等等
* type: 表示在索引数组中使用的OpenGL的数据类型,值可能为:
- GL_UNSIGNED_BYTE: 表示GLubyte
- GL_UNSIGNED_SHORT: 表示GLushort
我知道有许多问题。首先要介绍这些函数是怎样工作。这里定义了可编程管线中的最重要的事情之一,VSH将被执行的次数。这是由参数count决定。如果你指定128给它,当前使用的程序将处理VSH128次。当然GPU会尽可能优化处理这个过程,但总而言之,你的VSH将会处理128次去处理所有你定义的属性和统一量。也是为什么我说要注意顶点元素的数量和顶点数组中的元素数量的区别。非常简单,你应该有一个200个元素的顶点数组,但由于一些原因,你只需要构建一个三角形,此时count应该是3,而不是200。如果你正在使用索引数组,这将更加有用。你应该有8个元素在顶点数组中,但索引数组指定24个元素,在这种情况下count应是24。总之,就是你想要绘制的顶点数量的元素。如果你在使用glDrawArrays,参数count的工作方式就像初始步幅到你的每个顶点属性。例如,你设置为2,在顶点着色器的值将从你在glVertexAttribPointer中指定的数组索引2开始,而不是默认以0开始。如果你使用glDrawElements第一个参数的工作方式就像初始步幅到索引数组,而不是直接到你的每个顶点值。type表明数据类型,实际上它是一个优化提示。如果你的索引数组元素少于255个元素,使用GL_UNSIGNED_BYTE非常不错。有此OpenGL的实现支持第三种数据类型:GL_UNSIGNED_INT,但这个不常见。现在我们讨论下构建模式,这个由mode定义。这是一个在你的网格结构中使用的提示。但这个模式不是对所有的网格有用。下面的图可以帮助你理解:
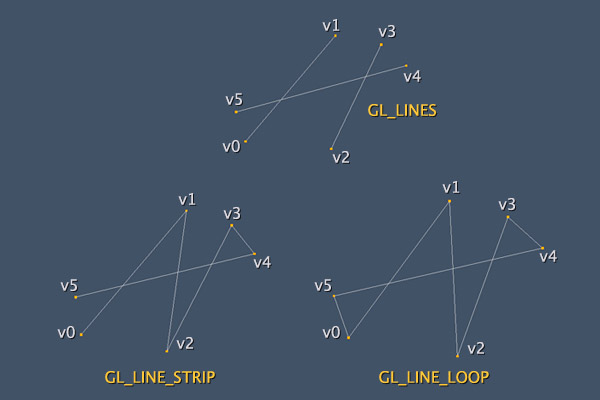
上面的图展示当我们使用一种绘制线的模式发生了什么。在上图的所有绘制由点序列{v0,v1,v2,v3,v4,v5}顶点数组组成,假设每个顶点有不同的x,y,z的坐标。如我前面所说,唯一的模式兼容任何类型的绘制是GL_LINES,其它模式是为一些特定情况做好优化的。优化?是的,使用GL_LINES绘制的线是3条,使用GL_LINE_STRIP绘制的线是5条,使用GL_LINE_LOOP是6条,使用同样的顶点数组和同样的VSH循环。绘制三角形的模式相似:
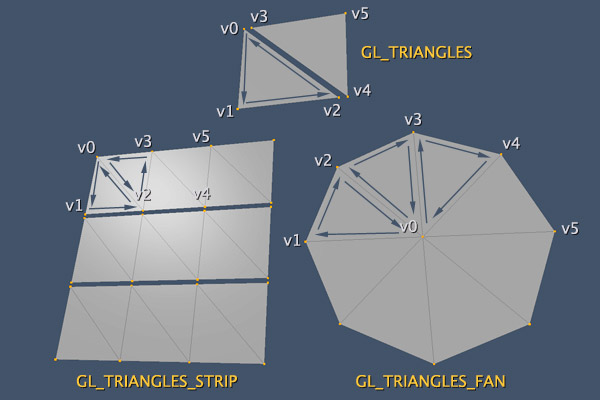
上图展示使用一种三角形绘制模式发生的。图中所示的所有图形都是以{v0,v1,v2,v3,v4,v5}的序列作为顶点数组,假设每个顶点对x,y,z坐标都有唯一的值。这是也是一样,同样的事,基础的GL_TRIANGLES对所有的网格有效,其它的模式为某些特定的情况优化。使用GL_TRIANGLES_STRIP我们需要重用上个最后形成的线,在上面的例子,我们必须用一个如数组{0,1,2, 0,2,3, 3,2,4,...}绘制。使用GL_TRIANGLES_FAN我们必须回到第一个顶点,图片我们可使用{0,1,2, 0,2,3, 0,3,4, ...}作为索引数组。我的建议是尽可能使用GL_TRIANGLES和GL_LINES。STRIP\LOOP\FAN的优化增益可能通过优化OpenGL在其它领域的绘制得到,使用其它技术,如减少网格多边形的数量或优化着色器的处理来实现。
渲染
最后的步骤是呈现最终的帧缓冲结果到屏幕上,即使你没有显示的使用帧缓冲区。我已经在我的EGL文章中解释了这点。如果你错过它点击此处,如果你使用Objective-C点击此处。这里就不重复。但是我想要记住的是,对于那些正在使用EAGL API的人,在调用presentRenderbuffer:GL_RENDERBUFFER前,你必须绑定颜色缓冲区,很明显你也要绑定帧缓冲区。这是因为渲染缓冲区在帧缓冲“里面”,你还记得它吗?最终的代码可能如下:
- (void) makeRender {
glBindFramebuffer(_framebuffer);
glBindRenderbuffer(_colorRenderbuffer);
[_context presentRenderbuffer: GL_RENDERBUFFER];
}
无论谁在使用EGL API,步骤就是在调换内部的缓冲区,使用glSwapBuffers函数。在我有EGL文章中我也解释了这点。好的,这是渲染的基本原理。OpenGL也提供了其它如多采样,这是一种特殊的渲染来产生抗锯齿图像。这是一个更高级的讨论。会在下一个部分出现。这篇教程已经很长了,让我们进入最后的结论各最终的版本。
总结
到这里,我不知道你花了多长时间来阅读这篇教程,但我得承认读起来很累。因此,我非常感谢你的阅读。现在,如我们所使用的,让我们记住所有的东西:
- 首先我们认识了OpenGL的数据类型和可编程管线
- 你的网格(原语)数据必须是一个数组信息。应该是被优化格式的结构数组
- OpenGL的工作原理像一个拥有多个钩子手臂的港口起重机。四个重要的钩子:帧缓冲、渲染缓冲、缓冲对象和纹理
- 帧缓冲持有3个缓冲对象:颜色、深度和模板。它们从OpenGL渲染形成图像
- 在上传到OpenGL前纹理必须有指定的格式(一个指定像素顺序和每个像素的颜色字节)。一旦OpenGL的纹理被创建,你需要激活将要在着色器处理的纹理单元。
- 栅格化是一个很大的过程,其中包含几个测试和每个片段的操作。
- 着色器成对使用,且必须在程序对象的里面。着色器使用它们自己的语言,被称为:GLSL或GLSL ES。
- 你可以仅在VSH中属性定义动态值(每个顶点值)。统一量总是常量且可以同时在两个着色器中使用。
- 你需要在绘制新的东西前清除缓冲区
- 你想渲染的每个3D对象可以调用glDraw*函数
- 最终的渲染步骤是使用 EGL API(或 在iOS中的EAGL API)
我最后建议你再查看最重要的点,如果你还有疑问,可以提问,在下面留言,如果能帮助到你我会非常高兴。
下一步
这篇是关于OpenGL的中等维度介绍。使用这些知识你可以创建3D应用。我认为这是学习OpenGL一半。在下一个部分,一篇高级教程,我会讨论这里跳过的所有:3D纹理,多采样,离屏渲染,每个片段深度操作及一些更好的练习开发我有3D引擎。
可能我会在此系列第三部分前写另外2篇教程。一个关于纹理,复杂的二进制图像和像PVR纹理格式的压缩。另一个关于ModelViewProjection矩阵,四元素和矩阵运算,它更像是一篇数学文章,谁喜欢,谁就会欣赏。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号