集群的升级
现在是2022年11月29日,CKA的考试环境用的是v1.25.1,我目前的环境是v1.23.13,为了保持跟考试环境一致,这里对集群版本做个升级。
1.1 k8s升级说明
-
k8s的更新迭代很快,大约三个月就发布一个大版本,如v1.23,1.24等等。
-
beta版本是公测版本,alpha是内测版本。
-
官方升级建议按小版本升级,如v1.23.1升级到v.1.23.2,不推荐跨大版本升级。
-
需要注意:二进制可以跨大版本升级,但是kubeadm只能小版本逐个升级,如v1.23.5可以直接升级到v1.23.14再升级到v1.24.0,不能直接从v1.23.5升级到v1.24.0。
-
v1.16版本之前apiversion的版本是extensions/v1beta1,于v1.16版本之后弃用,升级的话需要注意apiversion,有可能升级之后不能进行增删改查,需要手动改etcd里的数据。
参考资料:apiversion的版本说明 -
升级顺序:etcd→master组件→node组件
-
多看官方的github的CHANGELOG查看升级改动,英文不好可以看docker的中文社区,k8s中文社区
1.2 升级Etcd集群
视频中是v1.18升级到v1.19,如下是v1.18升级到v1.19升级过程。
查看现在的etcd的版本
#v1.19版本查看命令etcdctl -v
$ etcdctl -v
#v1.23.13查看命令
$ etcdctl version
etcdctl version: 3.5.1
API version: 3.5
升级流程
- 备份etcd数据
- 下载新版etcd包
- 停止从节点的etcd
- 替换etcd和etcdctl
- 启动etcd
- 再升级主节点的etcd
升级注意事项
-
升级前要在测试环境中测试一遍,因为升级过程中可能会遇到突发事件,比如各个版本的配置文件参数有改动,需要查看CHANGELOG。
-
一定要注意,要在非业务时间段升级,一般在晚上升级。
-
升级kubelet,还需要将业务进行漂移,不进行漂移会造成pod重启,因为升级kubelet之后容器的hash值会变,hash值一变,kubelet就会重启容器。解决的办法很复杂,会涉及到修改k8s源码。这些后续都会讲到。
-
大部分服务器都是x86_64架构的,可使用
uname -m查看,不要下错文件了。
视频中升级etcd
视频中是k8s v1.19版本,etcdv3.3.8升级到etcdv3.4.7
etcd集群使用的双向认证,查看或使用etcd需要指定证书文件
需要注意,同版本的etcd,命令有可能不一样,需要查看帮助文档
查看etcd集群状态
$ etcdctl \
--ca-file /etc/kubernetes/pki/etcd/etcd-ca.pem \
--key-file /etc/kubernetes/pki/etcd/etcd-key.pem \
--cert-file /etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379

这里的三个ip地址是etcd部署所在节点的服务器地址
isleader=true表示是主节点,其他为从节点,可以看到19为主,18,20为从节点
先升级从节点,备份数据
#查看etcd帮助,会发现默认使用的是v2的命令如ETCDCTL_API=2,需要改为3版本
$ etcdctl -h
$ export ETCDCTL_API=3
#改为3版本后,证书指定命令会发生改变,查看etcd状态命令如下
$ etcdctl \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379 member list
备份数据
#查看备份命令帮助
$ etcdctl \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379 snapshot -h
#save就是备份,restore回滚,status状态
#备份数据
$ etcdctl \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379 snapshot save 20221129-1740.db
登录master02关闭etcd服务
master02节点是192.168.1.18
systemctl stop etcd
#查看状态,发现节点192.168.1.18变为不健康
$ etcdctl \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379 endpoint health

解压etcd
#在master01上解压etcd软件
tar xf etcd-v3.4.7-linux-amd64.tar.gz
#登录master02查看etcd位置
$ which etcd
/usr/local/bin/etcd
$ cd /usr/local/bin/etcd
#备份,只在一台服务器上备份即可
mkdir bak
cp * bak/
#回到master01
cd etcd-v3.4.7-linux-amd64
scp etcd* k8s-master02:/usr/local/bin/
scp etcd* k8s-master03:/usr/local/bin/
#回到master02
etcd -v #可以看到版本已经是3.4.7,成功了
# 3.3.18到3.4.7版本有个参数有改动
vim /etc/etcd/etcd.config.yml
...
log-output: [ 'default' ] #改成这样
...
#重启成功
systemctl restart etcd
tail -f /var/log/messages
#回到master01查看日志会发现提示版本过高,因为我们升级了master02的etcd的版本
tail -f /var/log/messages
#来到master03节点
systemctl stop etcd
vim /etc/etcd/etcd.config.yml
...
log-output: [ 'default' ] #改成这样
...
systemctl restart etcd
#回到master01查看etcd集群状态
$ etcdctl \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379 endpoint health
#查看节点状态,可以看到都是健康的
kubectl get node
#以同样的方式升级主节点
#主节点stop掉会重新选主
systemctl stop etcd
vim /etc/etcd/etcd.config.yml
...
log-output: [ 'default' ] #改成这样
...
cd etcd-v3.4.7-linux-amd64
scp etcd* /usr/local/bin/
systemctl restart etcd
#查看etcd集群状态,发现已经启动成功
$ etcdctl \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--endpoints https://192.168.1.19:2379,https://192.168.1.18:2379,https://192.168.1.20:2379 endpoint health
etcd3.3.18到3.4.7版本有个参数有改动,如果没有修改log-output参数,启动etcd会报错,错误如下

提示版本过高的日志
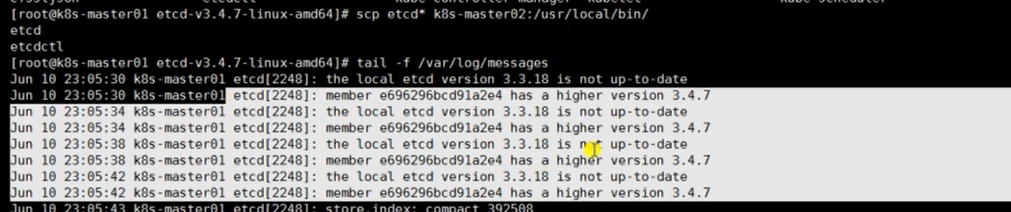
至此,etcd集群升级成功!
我的环境升级etcd
我的环境是v1.23.13升级到v1.25.1
etcdv3.5.1升级到v3.5.4
查看etcd版本
$ etcdctl version
etcdctl version: 3.5.1
API version: 3.5
打开官方的github的CHANGELOG查看升级改动,进入v1.25.1版本Changelog查看更新变化
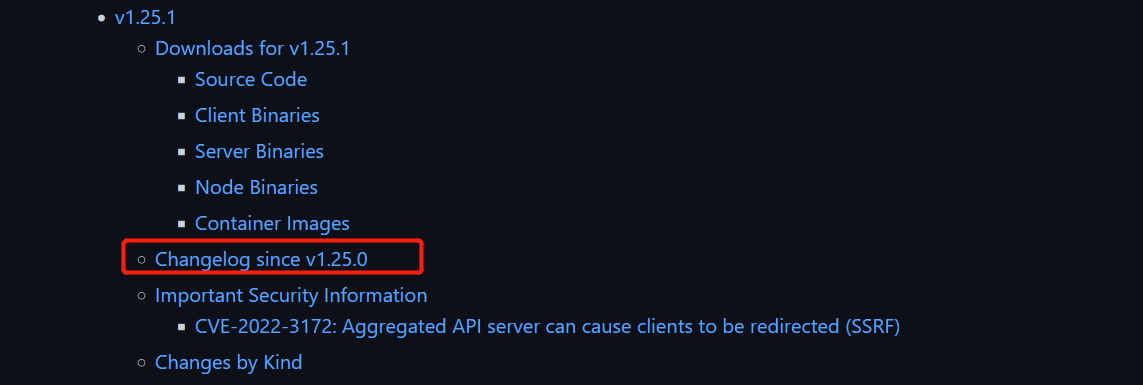
使用Crtl+F搜索etcd,可以看到etcd版本需要升级为v3.5.4

下载etcd 3.5.4版本
下载链接:https://github.com/etcd-io/etcd/releases/tag/v3.5.4
#解压
tar zxvf etcd-v3.5.4-linux-amd64.tar.gz
#查看etcd状态
$ export ETCDCTL_API=3
etcdctl --endpoints="10.103.236.203:2379,10.103.236.202:2379,10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint status --write-out=table
#通过snapshot -h查看快照帮助
$ export ETCDCTL_API=3
etcdctl --endpoints="10.103.236.203:2379,10.103.236.202:2379,10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem snapshot -h
...
COMMANDS:
restore Restores an etcd member snapshot to an etcd directory #回滚
save Stores an etcd node backend snapshot to a given file #备份数据
status [deprecated] Gets backend snapshot status of a given file #查看状态
...
#备份数据,这里只需要指定其中一个节点备份就行了,指定多个会报错
$ etcdctl --endpoints="10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem snapshot save 20221130-1640.db
etcd如下状态是正常的

登录master02关闭etcd服务
master02节点是10.103.236.202
$ systemctl stop etcd
#查看状态,发现节点10.103.236.202变为不健康
$ export ETCDCTL_API=3
etcdctl --endpoints="10.103.236.203:2379,10.103.236.202:2379,10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint health

解压etcd
#在master01上解压etcd软件
tar zxvf etcd-v3.5.4-linux-amd64.tar.gz
#登录master02查看etcd位置
$ which etcd
/usr/local/bin/etcd
$ cd /usr/local/bin/
#备份,只在一台服务器上备份即可
mkdir bak
cp * bak/
#回到master01
cd etcd-v3.5.4-linux-amd64
scp etcd* k8s-master02:/usr/local/bin/
scp etcd* k8s-master03:/usr/local/bin/
#回到master02
etcd -v #可以看到版本已经是3.5.4了
etcdctl version: 3.5.4
API version: 3.5
#重启master02跟03的etcd服务
systemctl restart etcd
tail -f /var/log/messages
#回到master01查看日志会发现提示版本过高,因为我们升级了master02的etcd的版本
tail -f /var/log/messages
#回到master01查看etcd集群状态
$ export ETCDCTL_API=3
etcdctl --endpoints="10.103.236.203:2379,10.103.236.202:2379,10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint health
#查看节点状态,可以看到都是健康的
kubectl get node
#以同样的方式升级主节点
#主节点stop掉会重新选主
systemctl stop etcd
cd etcd-v3.5.4-linux-amd64
scp etcd* /usr/local/bin/
systemctl restart etcd
#查看etcd集群状态,发现已经启动成功
$ export ETCDCTL_API=3
etcdctl --endpoints="10.103.236.203:2379,10.103.236.202:2379,10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint health
#查看etcd主从状态
$ export ETCDCTL_API=3
etcdctl --endpoints="10.103.236.203:2379,10.103.236.202:2379,10.103.236.201:2379" \
--cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem \
--cert=/etc/kubernetes/pki/etcd/etcd.pem \
--key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint status --write-out=table
etcd集群健康状态

etcd集群主从状态

至此,etcd集群升级成功!
1.3 k8s 1.19升级说明
配置文件一般都放在more /usr/lib/systemd/system/kube-apiserver.service文件中,如果没在里面,可能是一个独立的配置文件。
$ more /usr/lib/systemd/system/kube-apiserver.service
...
[Service]
ExecStart=/usr/local/bin/kube-apiserver \
--v=2 \
--logtostderr=true \
--allow-privileged=true \
--bind-address=0.0.0.0 \
--secure-port=6443 \
--insecure-port=0 \
--advertise-address=10.103.236.201 \
--service-cluster-ip-range=192.168.0.0/16 \
--service-node-port-range=30000-32767 \
--etcd-servers=https://10.103.236.201:2379,https://10.103.236.202:2379,https://10.103.236.203:2379 \
--etcd-cafile=/etc/etcd/ssl/etcd-ca.pem \
--etcd-certfile=/etc/etcd/ssl/etcd.pem \
--etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \
--client-ca-file=/etc/kubernetes/pki/ca.pem \
--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \
--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \
--kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \
--kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \
--service-account-key-file=/etc/kubernetes/pki/sa.pub \
--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \
--service-account-issuer=https://kubernetes.default.svc.cluster.local \
--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \
--authorization-mode=Node,RBAC \
--enable-bootstrap-token-auth=true \
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \
--requestheader-allowed-names=aggregator \
--requestheader-group-headers=X-Remote-Group \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-username-headers=X-Remote-User
# --token-auth-file=/etc/kubernetes/token.csv
Restart=on-failure
RestartSec=10s
LimitNOFILE=65535
#可以看到文件中指定了一些参数,证书文件,还有集群IP地址
关于CHANGELOG文档
更新版本有可能会发生参数变化,可以在CHANGELOG中看到。
文档建议从下往上看,最开始的文档改动会很大。
版本alpha为内测,beta为公测版本。
需要看下Urgent Upgrade Notes(紧急说明),这里会说一些废弃掉的参数。
这一集介绍了一个漂移,重启pod的情况,需要重新看下。
1.4 升级Master组件
高可用节点可以先停止一个节点,一个节点一个节点的进行升级,升级过程中不会影响宿主机Pod跟其他节点。
单节点升级会影响调度功能,不会影响业务跟pod。
升级中主要就是注意参数的变化。
升级kube-apiserver
#解压下载好的v1.25.1版本文件
tar xf kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin/
#查看版本,可以看到是v1.25.1版本
./kubectl version
#关闭master01的apiserver
systemctl stop kube-apiserver
which kube-apiserver
#升级前备份一下文件
cd /usr/local/bin/
mv kube-apiserver bak/
#拷贝文件
\cp /root/k8s_tools/kubernetes/server/bin/kube-apiserver /usr/local/bin/
/usr/local/bin/kube-apiserver --version
Kubernetes v1.25.1
#这次跨版本升级,有个参数取消了
vim /usr/lib/systemd/system/kube-apiserver.service
...
--insecure-port=0 ##删除这行参数
...
systemctl daemon-reload
systemctl restart kube-apiserver
tail -f /var/log/messages
#如果没有提示报错信息,说明版本是兼容的,没有别的参数改动
systemctl status kube-apiserver
如果不删除取消的参数会报如下错误
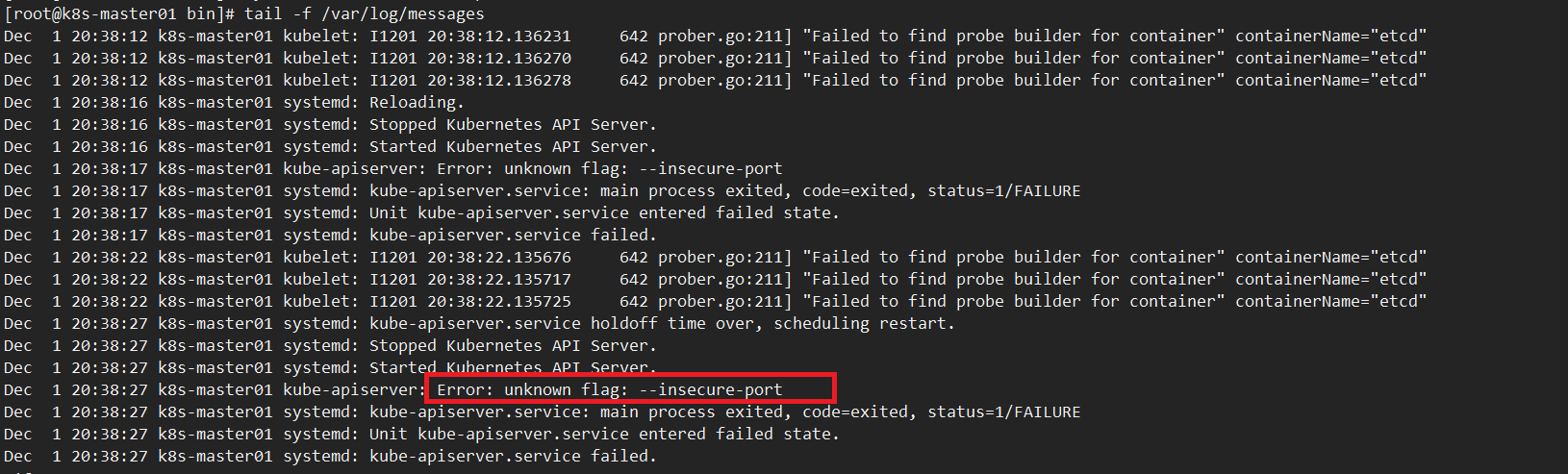
升级kube-controller-manager
systemctl stop kube-controller-manager
systemctl stop kube-scheduler
#备份
cd /usr/local/bin/
mv kube-controller-manager kube-scheduler bak/
cd /root/k8s_tools/kubernetes/server/bin/
#这次跨版本升级kube-controller-manager跟kube-scheduler取消掉了--address参数
vim /usr/lib/systemd/system/kube-controller-manager.service
...
--address=127.0.0.1 #删除这行
...
vim /usr/lib/systemd/system/kube-scheduler.service
...
--address=127.0.0.1 #删除这行
...
systemctl daemon-reload
#\表示强制覆盖
\cp -rp kube-controller-manager kube-scheduler /usr/local/bin/
systemctl restart kube-controller-manager
systemctl status kube-controller-manager
#可以看到没有报错
systemctl restart kube-scheduler
systemctl status kube-scheduler
#可以看到没有报错
升级kube-proxy
systemctl stop kube-proxy
#备份
cd /usr/local/bin/
mv kube-proxy bak/
cd /root/k8s_tools/kubernetes/server/bin/
\cp -rp kube-proxy /usr/local/bin/
systemctl restart kube-proxy
systemctl status kube-proxy
如果kube-proxy提示报错,参数找不到或者不支持,可以在CHANGELOG中搜索kube-proxy,其他组件同理。
升级kubectl
#备份
cd /usr/local/bin/
mv kubectl bak/
cd /root/k8s_tools/kubernetes/server/bin/
cp -rp kubectl /usr/local/bin/
#可以正常使用
$ kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health":"true","reason":""}
etcd-1 Healthy {"health":"true","reason":""}
etcd-0 Healthy {"health":"true","reason":""}
$ kubectl cluster-info
Kubernetes control plane is running at https://10.103.236.236:8443
CoreDNS is running at https://10.103.236.236:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
这时我们看下集群状态,发现版本还是v1.23.13,是因为还未升级kubelet
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready <none> 33d v1.23.13
k8s-master02 Ready <none> 32d v1.23.13
k8s-master03 Ready <none> 32d v1.23.13
k8s-node01 Ready <none> 32d v1.23.13
k8s-node02 Ready <none> 32d v1.23.13
升级其他节点
在master01上操作
cd /root/k8s_tools/kubernetes/server/bin/
scp kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubectl k8s-master02:/tmp/
scp kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubectl k8s-master03:/tmp/
在master02上操作
systemctl stop kube-apiserver
\cp /tmp/kube-apiserver /usr/local/bin/
#删除废弃参数
vim /usr/lib/systemd/system/kube-apiserver.service
...
--insecure-port=0 ##删除这行参数
...
systemctl daemon-reload
systemctl restart kube-apiserver
systemctl status kube-apiserver
tail -f /var/log/messages
systemctl stop kube-controller-manager
systemctl stop kube-scheduler
\cp /tmp/kube-{controller-manager,scheduler} /usr/local/bin/
#删除废弃参数
vim /usr/lib/systemd/system/kube-controller-manager.service
...
--address=127.0.0.1 #删除这行
...
vim /usr/lib/systemd/system/kube-scheduler.service
...
--address=127.0.0.1 #删除这行
...
systemctl daemon-reload
systemctl restart kube-controller-manager
systemctl status kube-controller-manager
#没有报错再继续
systemctl restart kube-scheduler
systemctl status kube-scheduler
systemctl stop kube-proxy
\cp /tmp/kube-proxy /usr/local/bin/
systemctl restart kube-proxy
systemctl status kube-proxy
cd /usr/local/bin/
\cp /tmp/kubectl /usr/local/bin/
kubectl get cs
kubectl cluster-info
#检查
$ kube-apiserver --version
Kubernetes v1.25.1
master03跟master02一样,这里不再复述
1.5 升级Node组件
使用pod漂移方式升级
这种升级方式业务不会中断。
#查看有哪些pod
kubectl get po --all-namespaces
#查看pod位置
kubectl get po -A -owide
我的环境中,master01节点上只有一个pod,所以先升级的master01,生产环境中尽量挑运行Pod数量较少的节点来优先升级。
设置master01为不可调度,即下线状态,这时master01上的pod会运行到其他节点上。
kubectl drain k8s-master01 --delete-local-data --force --ignore-daemonsets
- 因为是把master01下线,去除掉所有的pod,那么本地数据也可以不要了,使用--delete-local-date 可以删除本地数据。
- 如果是es集群,绑定了node节点的话,不要让他漂移,直接升级kubelet,因为es是有状态的,有可能会出问题。
- --ignore-daemonsets:忽略daemonset,因为我们在创建ds守护进程容器的时候,会给pod打上一个unSchedule的标签,而drain也是给容器打上一个 unSchedule的标签,这样就变成了死循环。所以需要忽略daemonset。
这时可以看到k8s-master01处于SchedulingDisabled状态
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled <none> 34d v1.25.1
k8s-master02 Ready <none> 33d v1.25.1
k8s-master03 Ready <none> 33d v1.25.1
k8s-node01 Ready <none> 33d v1.25.1
k8s-node02 Ready <none> 33d v1.25.1
#可以看到master01上门已经没有跑pod了
kubectl get po -owide | grep k8s-master01
升级过程如下,kubelet跟calico最好一起升级,防止pod二次漂移,在这里可以停一下去看一下如何升级calico,提前做好准备
#修改10-kubelet.conf,因为这次版本升级取消了某些参数,如下是v1.25版本的10-kubelet.conf配置文件
vim /etc/systemd/system/kubelet.service.d/10-kubelet.conf
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.kubeconfig --kubeconfig=/etc/kubernetes/kubelet.kubeconfig"
Environment="KUBELET_SYSTEM_ARGS=--container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
Environment="KUBELET_CONFIG_ARGS=--config=/etc/kubernetes/kubelet-conf.yml"
Environment="KUBELET_EXTRA_ARGS=--node-labels=node.kubernetes.io/node='' "
ExecStart=
ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_SYSTEM_ARGS $KUBELET_EXTRA_ARGS
systemctl daemon-reload
systemctl stop kubelet
#替换kubelet二进制文件
cd /root/k8s_tools/kubernetes/server/bin/
\cp -rp kubelet /usr/local/bin/kubelet
#替换之后先不要启动kubelet,往下翻去升级calico,这样会防止pod二次漂移,后续会讲到。
systemctl start kubelet
systemctl status kubelet
#可以看到成功启动
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled <none> 33d v1.25.1 #升级了kubelet,版本就变了
k8s-master02 Ready <none> 32d v1.23.13
k8s-master03 Ready <none> 32d v1.23.13
k8s-node01 Ready <none> 32d v1.23.13
k8s-node02 Ready <none> 32d v1.23.13
kubectl uncordon k8s-master01 #恢复过来,让节点上线
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready <none> 33d v1.25.1
k8s-master02 Ready <none> 32d v1.23.13
k8s-master03 Ready <none> 32d v1.23.13
k8s-node01 Ready <none> 32d v1.23.13
k8s-node02 Ready <none> 32d v1.23.13
不漂移pod的升级方法
之前使用pod漂移的方式升级了master01,这次使用不漂移的方式升级master02跟maser03
#将master01上的kubelet拷贝到其他节点
cd /root/k8s_tools/kubernetes/server/bin
scp kubelet k8s-master02:/tmp
scp kubelet k8s-master03:/tmp
scp /etc/systemd/system/kubelet.service.d/10-kubelet.conf k8s-master02:/etc/systemd/system/kubelet.service.d/10-kubelet.conf
scp /etc/systemd/system/kubelet.service.d/10-kubelet.conf k8s-master03:/etc/systemd/system/kubelet.service.d/10-kubelet.conf
#在master02上操作
systemctl stop kubelet
\cp -rp /tmp/kubelet /usr/local/bin/
#注意:有个检测时间,在五分钟内启动kubelet,pod是不会漂移的
systemctl daemon-reload
systemctl start kubelet
systemctl status kubelet
kubectl get node #发现master02版本也变了
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready <none> 33d v1.25.1
k8s-master02 Ready <none> 32d v1.25.1
k8s-master03 Ready <none> 32d v1.23.13
k8s-node01 Ready <none> 32d v1.23.13
k8s-node02 Ready <none> 32d v1.23.13
#在master03上操作
systemctl stop kubelet
\cp -rp /tmp/kubelet /usr/local/bin/
systemctl daemon-reload
systemctl restart kubelet
#可以看到master03的版本也变了
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready <none> 33d v1.25.1
k8s-master02 Ready <none> 32d v1.25.1
k8s-master03 Ready <none> 32d v1.25.1
k8s-node01 Ready <none> 32d v1.23.13
k8s-node02 Ready <none> 32d v1.23.13
#看看容器有没有重启
kubectl get po -A -owide
正常情况下升级master02的kubelet,节点上的容器会重启,没有重启的原因是我们升级的速度很快,没有触发健康检查,用kubeadm的时候所有容器会重启,但是不重启情况更好,业务不会中断。
可以看下容忍度,也可能跟容忍度有关,如下图所示如果节点的状态不正常,会容忍300s,在300s不进行漂移
kubectl describe po coredns-54b8c69d54-ct9hw -n kube-system

查看dns的健康检查
kubectl edit deploy coredns -n kube-system
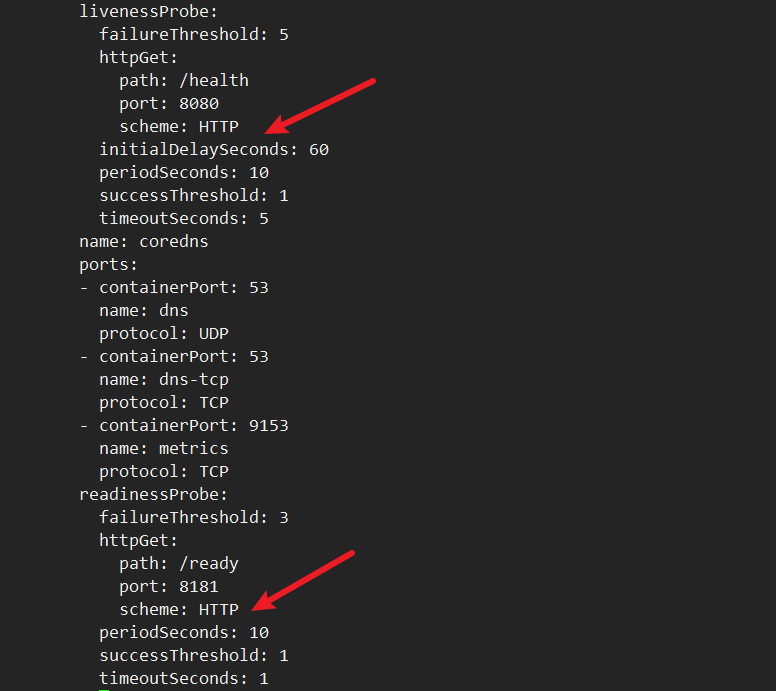
存活检查的是8080端口,失败5次后认为容器不健康才会重启,我们升级的过程特别快,还没有检测到5次,因为间隔是10s,所以需要50s才会重启,所以不会重启。就绪检查的是8181端口。
其他节点升级步骤是一样的,在升级集群前一定要在测试环境上先测试。
两种升级区别
如果我不能让服务有中断,就使用漂移的方法。
1.6 升级Calico
calico升级文档:https://docs.projectcalico.org/maintenance/kubernetes-upgrade#upgrading-an-installation
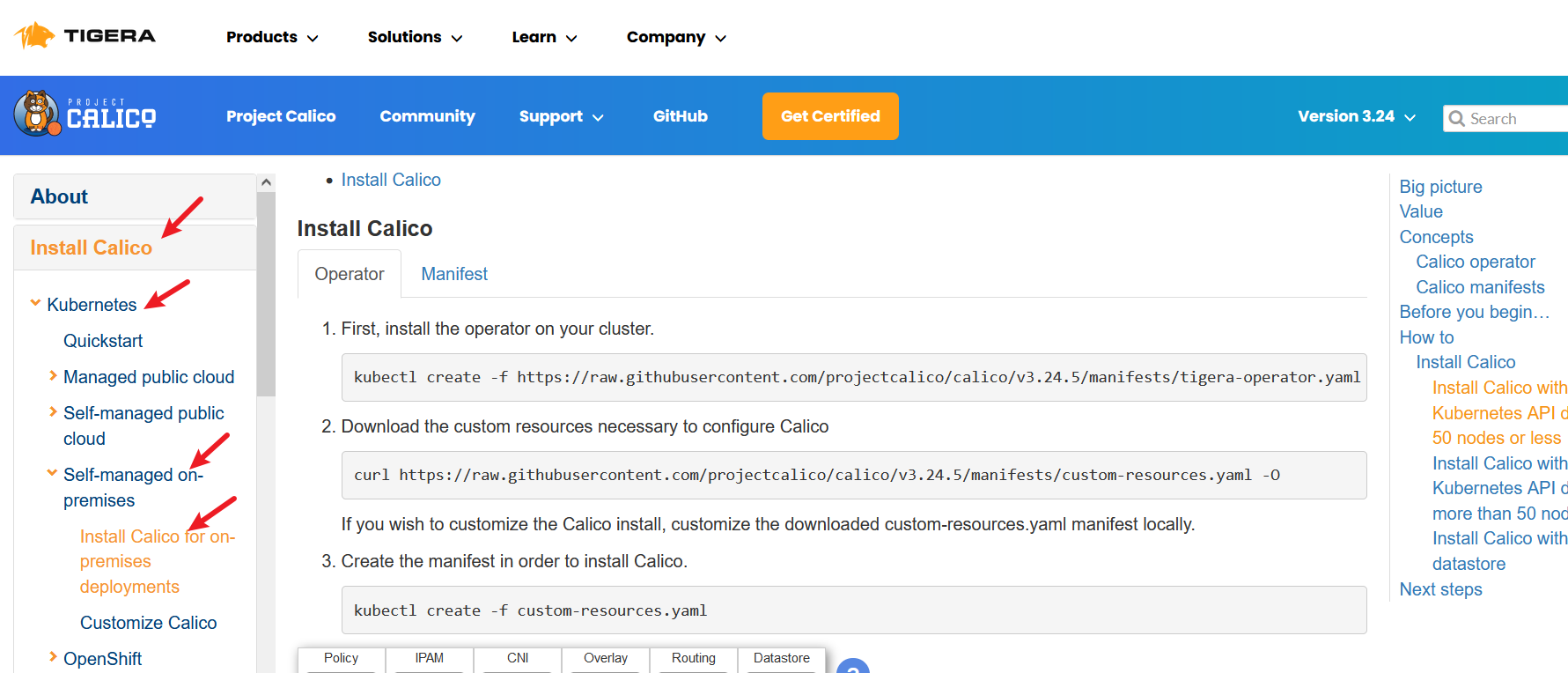
安装calico有三种方式
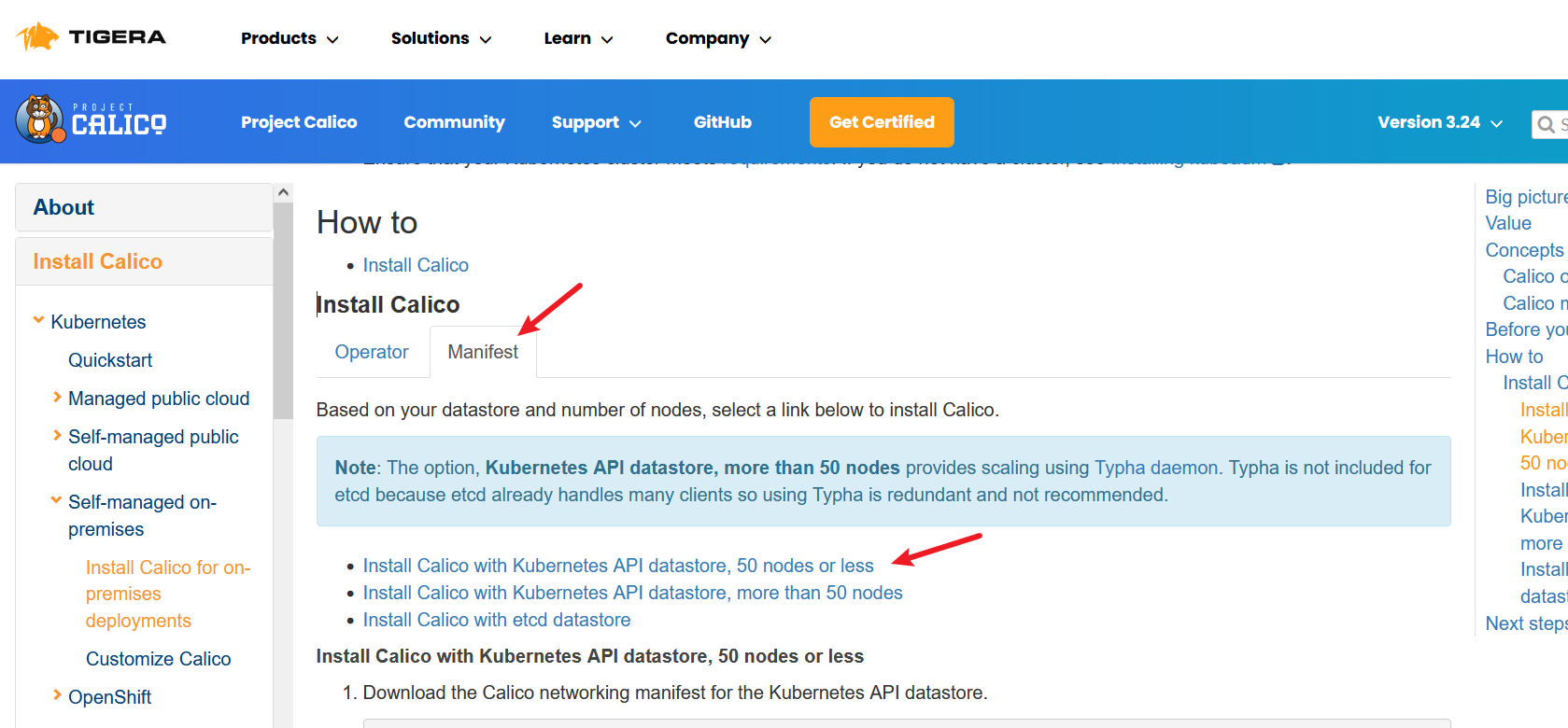
前两种方式使用的是apiserver去连到etcd的,后一种方式是calico直连etcd的。
通过apiserver去连接etcd节点,又分为了安装少于50个节点的方法,跟超过50个节点的方法。
官方推荐使用少于50个节点的安装方法,如果节点大于50个不要使用该方法。
第二种方法无需任何配置,直接运行就行了。
第三种方法直连etcd,把etcd的证书跟IP地址写入配置文件就可以了。
如果同时使用了calico跟flannel一定要用etcd的安装方法,不要使用apiserver连接etcd的方法。
老师的经验
在opensack上搭建的k8s集群,calico部署方式是使用apiserver连接到etcd时,当etcd全挂掉的时候,会导致每个宿主机上的容器网络不通,但在物理机上搭建k8s集群的时候不会出现这种情况,对网络不会有任何影响。
大于50个节点的安装方式会多一个calico的管理pod,用来管理其他calico节点的pod。
升级分为四种情况
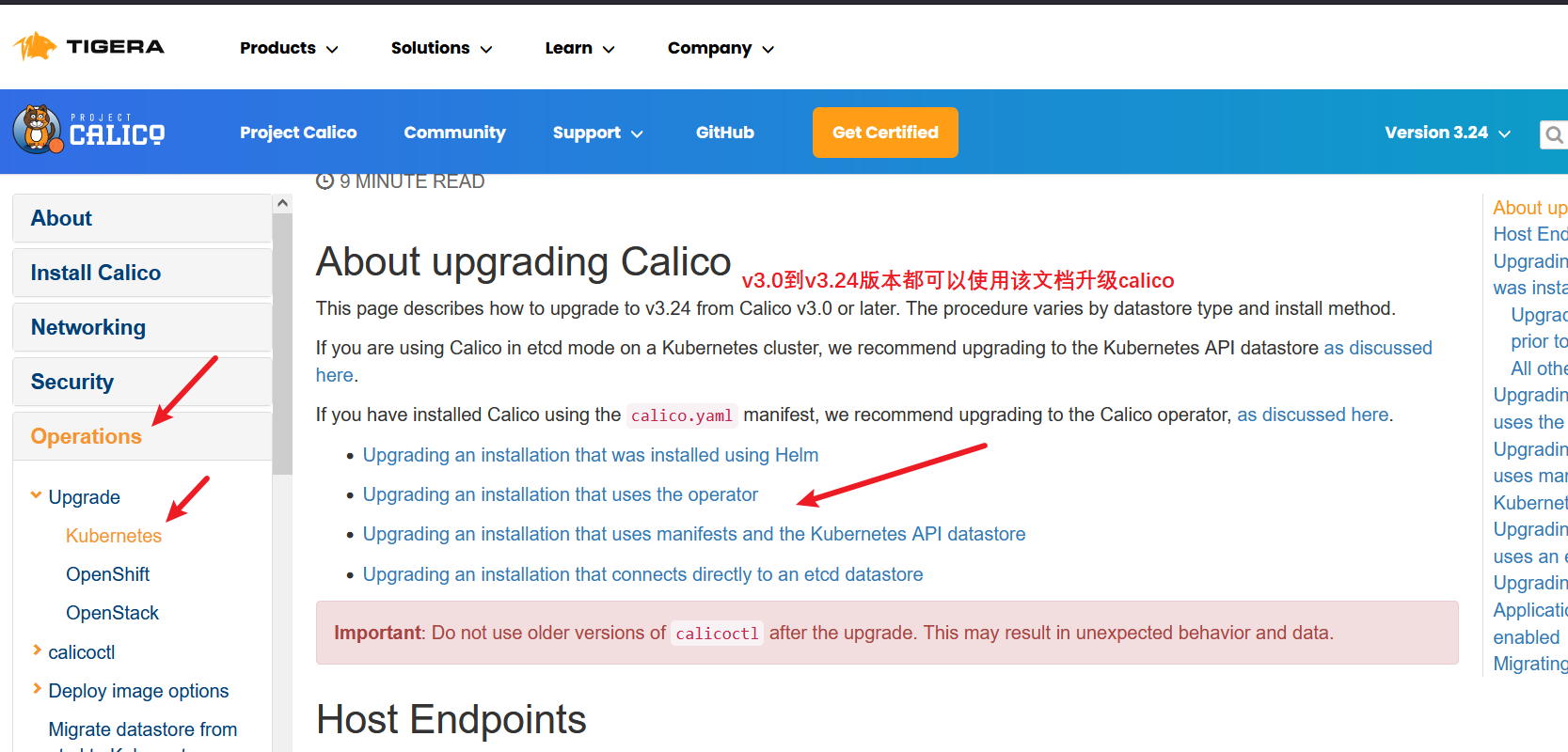
如果使用apiserver连接etcd的话需要点击第三种,直连etcd点击第四种
这里点击第三种方式,使用apiserver连接etcd的方式
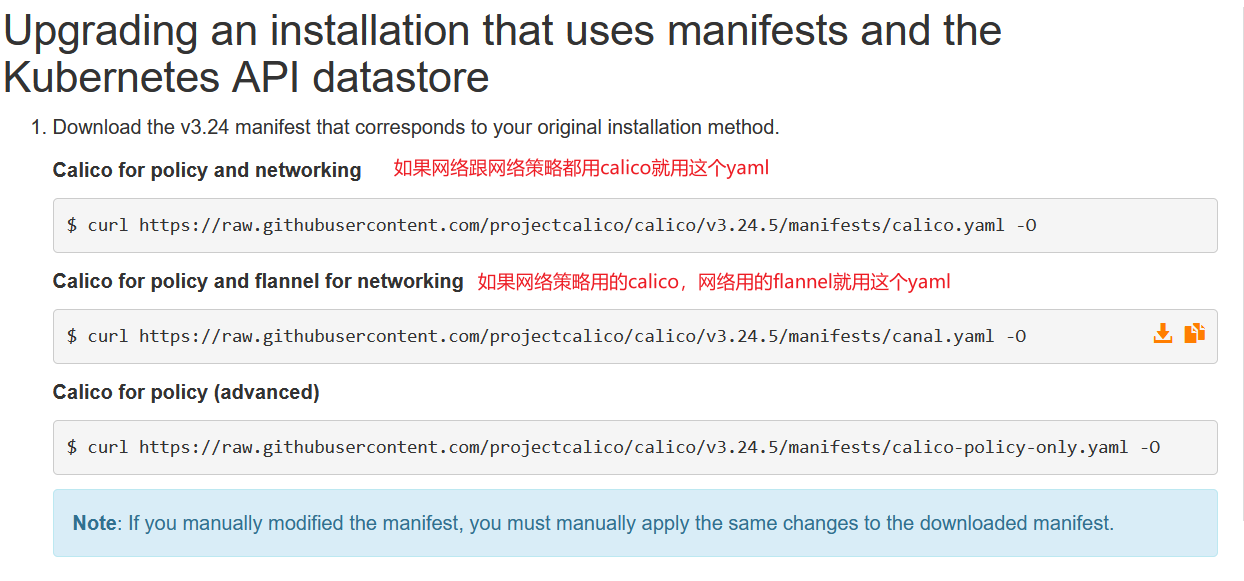
这里选择第一种,网络策略跟网络都使用calico
cd /root/k8s_tools
curl https://raw.githubusercontent.com/projectcalico/calico/v3.24.5/manifests/calico.yaml -O
#搜索image查看使用的镜像版本
less calico.yaml
这个版本的calico.yaml文件用的是v3.24.5的镜像

查看我们现在用的calico镜像版本
#随机找一个calico的pod
kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
...
kube-system calico-node-6mvcw 1/1 Running 1 (12h ago) 5d19h
kube-system calico-node-6n9dc 1/1 Running 93 (12h ago) 5d19h
...
#可以看到我们现在calico的版本是v3.22.0
kubectl get pod calico-node-6n9dc -n kube-system -oyaml | grep image
image: registry.cn-beijing.aliyuncs.com/dotbalo/node:v3.22.0
#可以看到我们目前使用的是滚动更新
kubectl edit ds -n kube-system
...
updateStrategy:
type: RollingUpdate #默认是滚动更新,升级失败了其他节点也会失败
rollingUpdate:
maxUnavailable: 1
...
接上回,我们在master01上升级kubelet,同时也应把calico顺带升级了,这里给出升级方法
在master01上操作
#修改calico.yaml文件,改为OnDelete的方式,这样只升级当前节点的calico,容易排查问题,且如果该节点升级失败了不会影响其他节点
cd /root/k8s_tools
vim calico.yaml
...
updateStrategy:
type: RollingUpdate #默认是滚动更新,升级失败了其他节点也会失败,改为OnDelete
rollingUpdate: #删除这一行
maxUnavailable: 1 #删除这一行
...
kubectl apply -f calico.yaml
$ kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6f6595874c-krgz7 1/1 Terminating 12 (20h ago) 5d20h
calico-node-6mvcw 1/1 Running 1 (12h ago) 5d20h
calico-node-ggf4r 1/1 Running 94 (12h ago) 5d20h
calico-node-s26jk 0/1 Init:0/4 0 2s #新的calico
calico-node-t8jpj 1/1 Running 94 (12h ago) 5d20h
calico-node-z2dqj 1/1 Running 126 (12h ago) 5d20h
calico-typha-6b6cf8cbdf-95g44 1/1 Running 4 (12h ago) 5d20h
coredns-5db5696c7-lg8jv 1/1 Running 0 65m
metrics-server-6bf7dcd649-jrh8q 1/1 Running 12 (12h ago) 32d
#升级完calico,跳回去启动Kubelet
验证一下其他节点是否升级了
#找一个没有升级过的calico看看,可以看到版本还是原来的,没有升级
kubectl get po calico-node-z2dqj -n kube-system -oyaml | grep image
#看下装在master02上的calico
kubectl get po -n kube-system -owide
#查看下master02的calico的yaml
kubectl get po calico-node-z2dqj -n kube-system -oyaml | grep image
#删掉master01的calico的pod
kubectl delete po calico-node-xxx -n kube-system
kubectl describe po calico-node-xxx
#可以看到拉取的是最新的镜像,其他节点是没有变化的
升级其他节点过程类似,唯一不同的是应用完calico.yaml后,需要删除master02跟03的calico容器,让其使用最新的配置文件。
kubectl delete po calico-xxx-xxx calico-xxx-xx -n kube-system
-
在升级calico中,pod的网络也是通的,因为路由规则一旦创建完成,新版本的calico升级是不会影响已创建的路由规则,虽然升级过程中网络不会中断也不会影响业务,但是在生产环境中建议还是先下线节点再进行升级,这样防止一个节点在升级过程中出现问题,不会影响到其他节点的服务。
-
calico最好跟kubelet一起升级,比如在一个节点上升级完calico就升级kubelet,这样就防止两次漂移,calico升级漂移一次,kubelet升级漂移一次。
新版本的calico升级不会影响现有的路由规则。
新版本的kubelet升级不会重启现有的容器跟业务。
1.7 升级CoreDNS
查看现有CoreDNS服务的版本
kubectl get pod coredns-5db5696c7-lg8jv -n kube-system -oyaml | grep image
image: registry.cn-beijing.aliyuncs.com/dotbalo/coredns:1.8.6
查看v1.25的CHANGELOG建议安装版本
建议安装v1.9.3的版本

打开CoreDNS官方github:https://github.com/coredns/coredns
安装文档在:https://github.com/coredns/deployment/tree/master/kubernetes
之前老版本名字叫kube-dns,现在新版本都叫coredns
使用git拉取代码
git clone https://github.com/coredns/deployment.git
#因为github是国外网站,拉不下来很正常
#我是下载zip压缩包,然后上传到服务器解压的
yum -y install unzip
cd /root/k8s_tools/
unzip coredns-master.zip
cd /root/k8s_tools/deployment-master/kubernetes
如果使用的是kube-dns就用如下命令,拉取代码后使用脚本安装即可
$ ./deploy.sh | kubectl apply -f -
$ kubectl delete --namespace=kube-system deployment kube-dns
升级前先备份
#查看configmap跟deloyment
kubectl get cm,deploy -n kube-system
NAME DATA AGE
configmap/calico-config 4 5d22h
configmap/coredns 1 33d
configmap/extension-apiserver-authentication 6 34d
configmap/kube-root-ca.crt 1 34d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/calico-kube-controllers 1/1 1 1 5d22h
deployment.apps/calico-typha 1/1 1 1 5d22h
deployment.apps/coredns 1/1 1 1 33d
deployment.apps/metrics-server 1/1 1 1 32d
#查看本机coredns的clusterrole、clusterrolebinding信息
$ kubectl get clusterrole system:coredns
NAME CREATED AT
system:coredns 2022-10-29T09:09:11Z
$ kubectl get clusterrolebinding system:coredns
NAME ROLE AGE
system:coredns ClusterRole/system:coredns 33d
#备份coredns的configmap文件跟deployment文件以及clusterrole、clusterrolebinding
mkdir bak
kubectl get cm coredns -n kube-system -oyaml > bak/coredns-cm.yaml
kubectl get deploy coredns -n kube-system -oyaml > bak/coredns-dp.yaml
kubectl get clusterrole system:coredns -oyaml > bak/cr.yaml
kubectl get clusterrolebinding system:coredns -oyaml > bak/crb.yaml
#使用脚本升级,脚本会生成coredns的svc,deployment,clusterrole、clusterrolebinding配置
#coredns的clusterrole、clusterrolebinding的名字叫system:coredns,通过如下命令查看生成的配置
./deploy.sh -s
#查看镜像版本
./deploy.sh -s | grep image
image: coredns/coredns:1.9.4
#视频中升级coredns的命令如下,执行了报错的话需要手动删除创建
./deploy.sh -s | kubectl apply -f -
#手动删除coredns
./deploy.sh -s > coredns.yaml
kubectl delete -f coredns.yaml
kubectl create -f coredns.yaml
#看到如下日志表示升级成功了
$ kubectl logs -f coredns-54b8c69d54-ct9hw -n kube-system
.:53
[INFO] plugin/reload: Running configuration SHA512 = 165c2220dade77166d5aa3508a7dd59a865dbb9a90ca5af87e487b4217222b80d5b35bedd2640b4c4895a10c969c81b9d1ff90d2592ccccc0307eebe5469b6ab
CoreDNS-1.9.4
linux/amd64, go1.19.1, 1f0a41a
查看coredns的clusterrole、clusterrolebinding的名字,名字叫system:coredns
验证
#看下有哪些svc
kubectl get svc -A
#进入其中一个pod
$ kubectl get po
$ kubectl exec -it nginx-test -- bash
$ curl kubernetes:443 #可以看到是可以解析的
Client sent an HTTP request to an HTTPS server.
$ curl metrics-server.kube-system:443 #如果有命名空间隔离,需要写上命名空间
Client sent an HTTP request to an HTTPS server.
#每个创建的pod都会有个resolv.conf配置文件,记录了dns配置信息
$ cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.10
options ndots:5
#将resolv.conf配置到宿主机上,宿主机就能解析到svc
#在master01上执行,注意注释掉原来有的dns配置
vim /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.10
options ndots:5
#telnet这个svc是通的,说明dns可以解析
telnet kube-dns.kube-system 53
Trying 192.168.0.10...
Connected to kube-dns.kube-system.
Escape character is '^]'.
#验证完记得将宿主机的dns改回来
在kubeadm升级coredns,替换一下deployment文件即可
再次强调:生产环境升级时要先在测试环境演练一遍谨防意外。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号