十四、执行计划分析2
前面说完了type索引类型,下面接着说possible_keys
possible_keys
可能走的索引的名字
key
最终选择的索引的名字
mysql> desc select sno from student where sno > 5;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 5 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
单列索引执行计划分析
key_len
索引覆盖长度
#回顾
当表为utf8m4格式下
varhcar(10)会预留40个字节长度
可以存10个中文,即占用40个字节
可以存10个英文或数字,占用10个字节
如下,t100w表采用utf8m4格式,k2列为char(4),预留4*4=16个字节长度,在这16个字节前面还有一个标识可以为空的字节,所以key_len长度为17个字节长度。
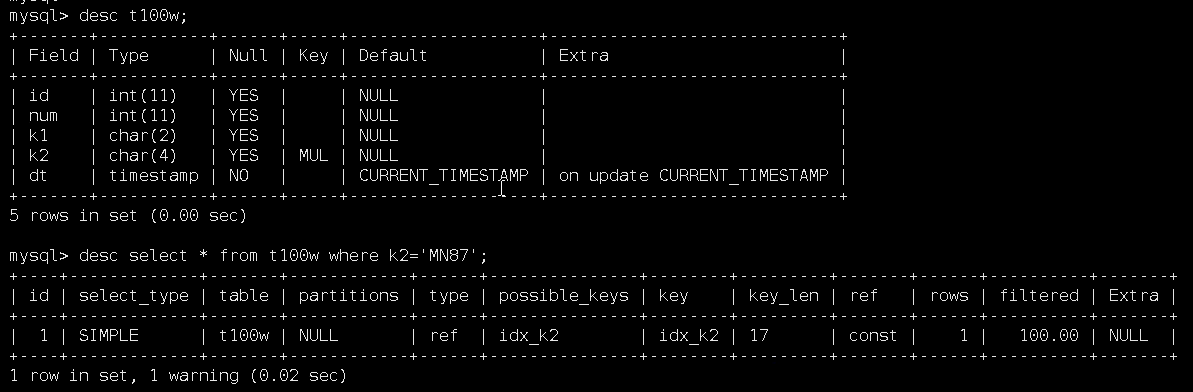
当k2设置为not null时,key_len长度为16,标识为空的字节就没了

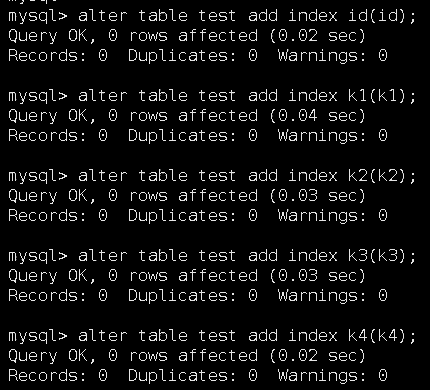
创建一个test表

给每个列都单独建立索引方便测试
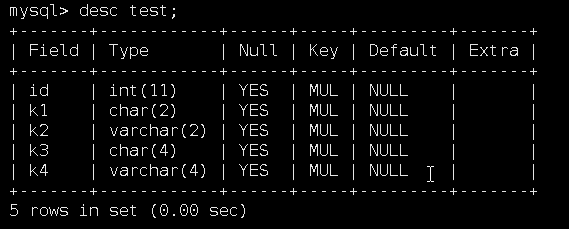
int类型都是占用4个字节,还有一个字节用于标识可以为空,所以key_len为5

char(2)最大保留长度为2*4=8个字节,还有一个字节用于标识可以为空,所以key_len为9

varchar(2)最大保留长度为2*4=8个字符,标识可以为空占用一个字符,还有两个字符标识开始跟结束。

总结: key_len索引长度是按照数据类型最大预留长度来计算的。
可以为空会占用一个字节长度,最好设置为不能为空,减少占用字节长度从而减少索引长度,提升性能。
参考资料: key_len长度计算
联合索引执行计划分析
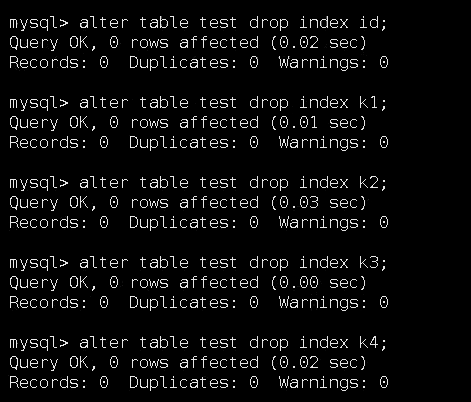
删除创建的索引
创建4个列的联合索引

此时key_len的长度为k1,k2,k3,k4长度之和,即9+11+17+19=56

总结:使用联合索引时,key_len长度越长效率越好,也就是所有索引都用起来的时候,效率最好。
对于单列的情况,key_len长度越短效率越好。
重新创建表test1编码格式为utf8

此时k1的char(2)数据类型key_len计算长度为2*3+1=7
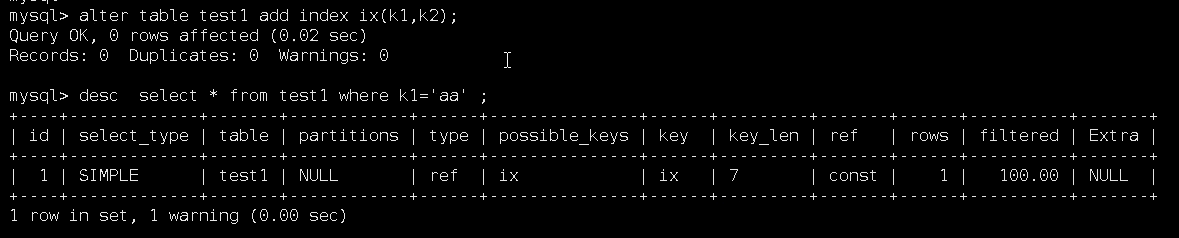
因为创建的是联合索引,所以必须有几个列一起查询才走索引
此时key_len的长度为k1,k2长度之和,即23+1+23+3=16
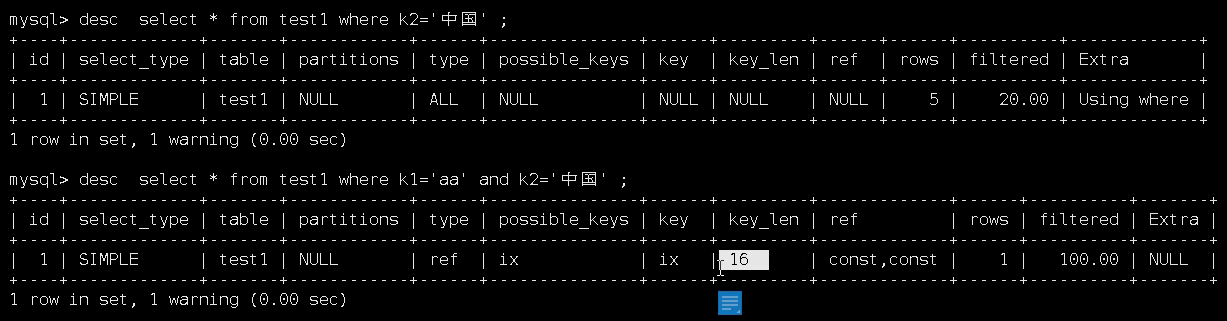
注意:utf8m4字符编码长度为1个字符预留4个字节,utf8字符编码长度为1个字符预留3个字节,GBK的字符编码长度为1个字符预留2个字节长度。
要分清预留字节长度,跟实际占用字节长度
如varchar(20),在utf8字节编码情况下
1.能存储20个任意字符,每个字符预留长度为3个字节。
2.能存储20个数字或字母,每个数字字母占用每个预留字符长度中的1个字节。
3.能存储20个中文字符,每个中文字符是占满了每个预留字符长度的所有字节。
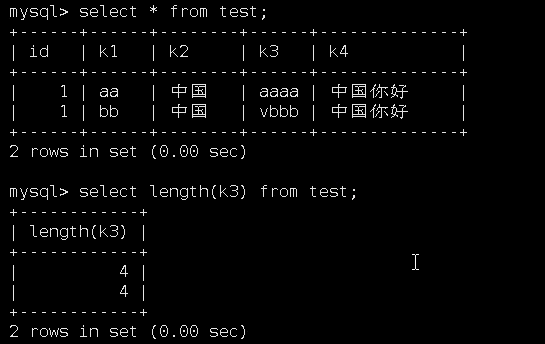
1个字母数字占用1个字节,所以如下字节长度为4
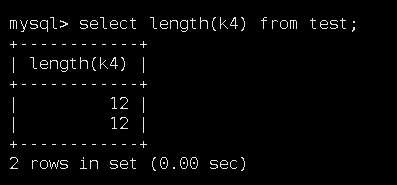
在utf8字符编码格式下,1个中文字符占用3个字节,所以如下字节长度为12
所有查询条件是等值查询时,联合索引走的是全索引,key_len长度是56,当条件顺序被打乱时,会自动按创建索引时的顺序进行排序。
如创建索引顺序为idx(k1,k2,k3,k4),则等值查询顺序被打乱,会自动排序成k1,k2,k3,k4走全索引,key_len长度为56。
当只有部分等值查询条件时,如只有k1,k3,k4时,排序后,只走k1索引,所以key_len长度为9
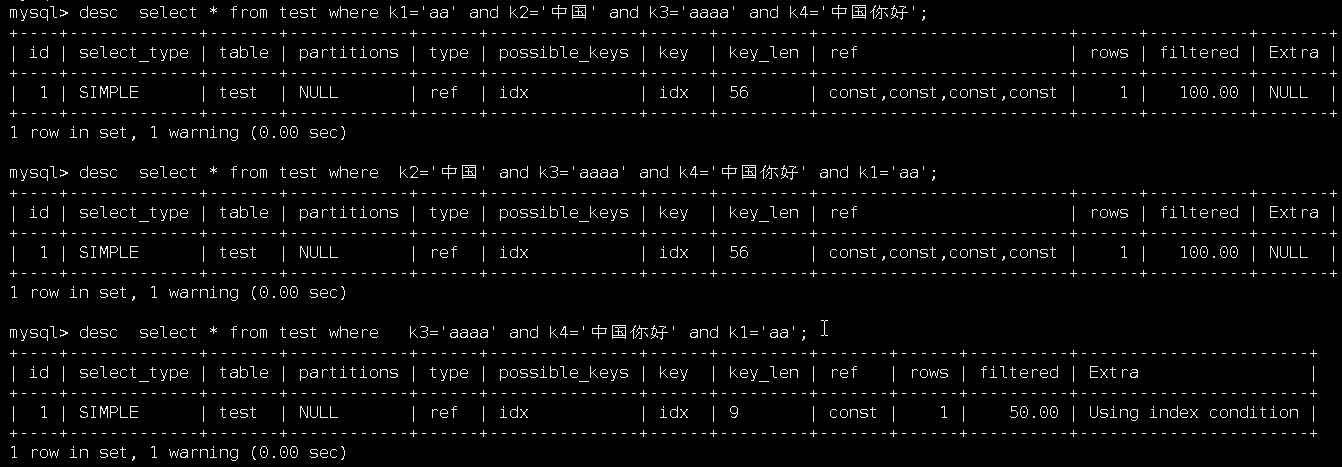
只有k1,k2,k4时,走k1,k2,key_len为20

当where后接> < >= <= like时,索引只走到不等值查询条件即止。
如下,k2>'中国',key_len长度值为k1+k2的长度

对于此类语句的优化即把不等值查询放在最后,同时更改索引为idx(k1,k3,k4)
优化总结:
1、根据语句执行频率修改索引,查询频率高才修改索引
2、创建联合索引时,将唯一值多的列放在最左侧,假设k2唯一值多,则创建索引为idx(k2,k1,k3,k4)
3、不连续查询条件,如只查询k1,k3,k4则创建索引为idx(k1,k3,k4)
4、没有k1列即最左侧列的联合查询是不走索引的
删除所有索引,创建两个单列索引
执行计划中只走了单列索引,对于这种多子句优化可以使用联合索引

创建idx3(k1,k2),可以看到Extra列中少了Using filesort排序,ken_len长度仅计算了k1,但是因为少了额外的排序所以性能得到了提升

总结
1、多子句查询,可以使用联合索引优化
2、必须按照子句执行顺序创建联合索引
Extra
当Extar列出现Using filesort时,需要使用额外的排序
一般涉及到的子句有
order by
group by
distinct
union
这种情况常出现在查询过程中有关排序的条件列没有合理的应用索引造成的。
可以通过key_len判断是否走全索引,没有走的话需要将子句添加到联合索引中去。
学习来自:老男孩深标DBA课程 第四章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号