正则表达式
正则表达式
正则表达式由普通文本和具有特殊意义的符号组成。
用于从数据流中匹配过滤出我们需要的数据流。
语法
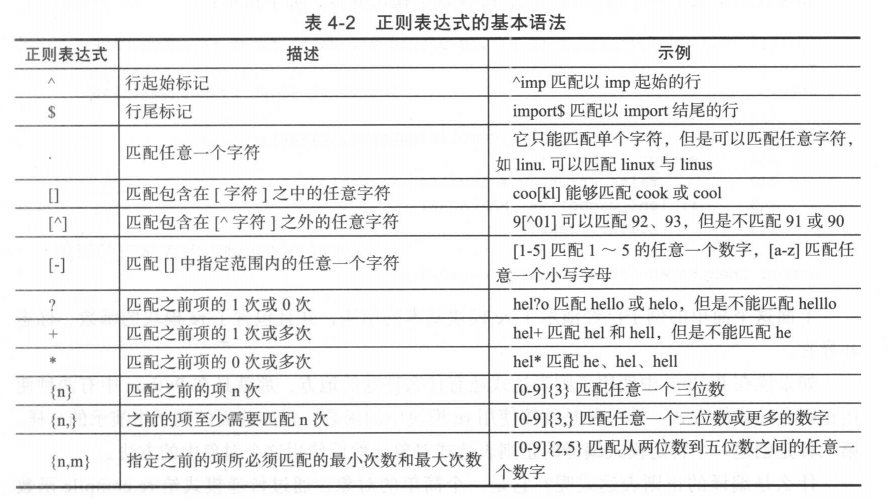
正则表达式修饰符 - 可选标志flags
修饰符 描述
re.I 使匹配对大小写不敏感(常用)
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响 ^ 和 $
re.S 使 . 匹配包括换行在内的所有字符
re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
使用re模块处理正则表达式
需要导入re模块,需要使用到re模块下的函数
re.match 从开头匹配
re.search 只匹配一次
re.findall 查找所有
re.sub 替换
re.split 分割
re.match
从字符串的起始位置匹配正则表达式,如果起始位置匹配不成功则返回None,成功则返回SRE_Match对象。
语法
re.match(pattern, string, flags=0)
pattern:正则表达式
string:字符串
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例
import re
msg = '佟丽娅娜扎热巴戴斯'
result =re.match('佟丽娅',msg)
print(result)
#out: <_sre.SRE_Match object; span=(0, 3), match='佟丽娅'>
print(result.group()) #group()方法可以提取匹配到的字符串
#out: 佟丽娅
re.search
仅查找第一次匹配到的字符串。
语法
re.search(pattern, string, flags=0)
pattern:正则表达式
string:字符串
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例
import re
msg = '娜扎热巴佟丽娅戴斯'
result = re.search('佟丽娅',msg)
print(result)
#out: <_sre.SRE_Match object; span=(4, 7), match='佟丽娅'>
#span表示在(4,7)找到的佟丽娅,match表示匹配的内容
print(result.span()) #out: (4, 7)
print(result.group()) #out: 佟丽娅
re.findall
将所有匹配的字符串以列表的形式返回,如果没有找到匹配的字符串,则返回空列表。
语法格式1
也叫非编译正则表达式,适用于过滤较小的数据流。
re.findall(pattern, string, flags=0)
pattern:正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例
#验证字符串中是否包含d7v
import re
msg = 'abcd7vjkfd8hdf00'
#search()只要找到一个匹配后续就不会再找了
result = re.search('[a-z][0-9][a-z]',msg)
print(result.group()) #out: d7v
#findall()匹配整个字符串中是否包含规则字符串,返回值是一个列表
result = re.findall('[a-z][0-9][a-z]',msg)
print(result) #out: ['d7v', 'd8h']
#使用flags标志忽略大小写
import re
text = 'UPPER python, lower python, Mixed Python'
print(re.findall('python',text,flags=re.I))
#out: ['python', 'python', 'Python']
print(re.sub('python','snake',text,flags=re.I))
#out: UPPER snake, lower snake, Mixed snake
语法格式2
也称编译正则表达式,适用于处理较大的数据流,速度比格式1要快。
pattern.findall(string[, pos[, endpos]])
pattern:正则表达式
string:要匹配的字符串
pos:可选,要匹配的字符串的起始位置,默认为0
endpos:可选参数,指定字符串的结束位置,默认为字符串的长度。
案例
import re
msg = 'abcd7vjkfd8hdf00'
pattern = re.compile(r'[a-z][0-9][a-z]')
result = pattern.findall(msg,0,11)
print(result) #out: ['d7v']
比较两者性能案例
使用seq命令生成1-10000000个数,-s表示分隔符号
$ seq -s '' 1 10000000 > data.txt #data.txt大小为66M
非编译正则表达式版本
import re
def main():
pattern = '[0-9]+'
with open('data.txt') as f:
for line in f:
re.findall(pattern,line)
if __name__ == '__main__':
main()
'''
运行速度如下
$ time python test.py
real 0m1.663s
user 0m0.336s
sys 0m1.180s
'''
编译正则表达式版本
import re
def main():
pattern = '[0-9]+'
re_pattern= re.compile(pattern)
with open('data.txt') as f:
for line in f:
re_pattern.findall(line)
if __name__ == '__main__':
main()
'''
运行速度如下
$ time python test2.py
real 0m0.402s
user 0m0.225s
sys 0m0.038s
'''
re.sub
用于替换字符串中的匹配项。
语法
re.sub(pattern, repl, string, count=0,flags=0)
pattern:正则表达式
repl:替换的字符串,可以为函数
string: 要匹配的字符串
count:可选参数 最多替换多少次,默认0替换所有
flags: 匹配模式,可以使用|表示同时生效,也可以在正则表达式中指定。
案例
import re
result = re.sub(r'\d+','99','java:60,python:80')
print(result) #out: java:99,python:99
#找到分数并使用函数计算加一
def func(temp):
num = temp.group()
num = int(num)+1
return str(num)
result = re.sub(r'\d+',func,'java:98,python:99')
print(result) #out: java:99,python:100
re.split
分割,同字符串的split()方法,但re.split()能使用正则表达式。
语法
re.split(pattern, string[, maxsplit=0, flags=0])
pattern:正则表达式
string:需要匹配的字符串
maxsplit:分隔次数,默认为0不限次数
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例
import re
result = re.split(r'[,:]','java:98,python:99') #遇到,跟:就切割
print(result) #out: ['java', '98', 'python', '99']
贪婪模式变成非贪婪模式
贪婪模式总是匹配最长的字符串,非贪婪模式匹配最短的字符串。
案例
import re
text = 'Beautiful is better than ugly. Explicit is better than implicit.'
#匹配以Beautiful开头,点号结尾的字符串会匹配最长的那条。
print(re.findall('Beautiful.*\.',text))
#out: ['Beautiful is better than ugly. Explicit is better than implicit.']
#使用非贪婪匹配,只需在匹配字符串时加一个?,表示匹配.* 1次
print(re.findall('Beautiful.*?\.',text))
#out: ['Beautiful is better than ugly.']
案例2
#贪婪模式变成非贪婪模式
#贪婪模式变成非贪婪模式
import re
msg ='abc123abc'
result=re.match(r'abc(\d+?)',msg)
print(result) #输出 abc1
path = '<img class="BDE_Image" src="http://tiebapic.baidu.com/forum/w%3D580/' \
'sign=6c1b37583af5e0feee1889096c6034e5/16f41bd5ad6eddc4cdde8cba2edbb6fd526633b1.jpg"' \
' size="776226" changedsize="true" width="560" height="380">'
#在""里面匹配一次或多次,如果不加?,会匹配到最后一个",即到380“
result = re.match(r'<img class="BDE_Image" src="(.+?)"',path)
print(result.group(1))
'''
out:
<_sre.SRE_Match object; span=(0, 4), match='abc1'>
http://tiebapic.baidu.com/forum/w%3D580/sign=6c1b37583af5e0feee1889096c6034e5/16f41bd5ad6eddc4cdde8cba2edbb6fd526633b1.jpg
'''
案例3
获取HTML页面中所有超链接
import re
import requests
r = requests.get('https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BE%8E%E5%A5%B3&fr=search')
print(re.findall('"(https?://.*?)"', str(r.content)))
其他案例

#注意正则永远验证的都是字符串
import re
#需要验证字符串msg中是否含有 a7a a88a a7878a
msg = 'a7aojowa88akfia7878ao'
result = re.findall('[a-z][0-9]+[a-z]',msg) #+表示前一位出现过>=1次
print(result) #输出结果 ['a7a', 'a88a', 'a7878a']
#qq号码的验证
qq = '451095888'
result = re.match('[1-9][0-9]{4,10}$',qq) #匹配的qq位数是5-11位,[1-9]一位了,后面只需要匹配4-10位即可
print(result.group())
#用户名验证,用户名必须为字母或者数字跟下划线,不能以数字下划线开头,必须大于6位
username = 'tz_2020'
result =re.search('^[a-zA-Z][a-zA-Z0-9_]{5,}$',username) #^表示开头匹配,$表示结尾匹配,如果使用match则可以不用^
print(result.group()) #输出 tz_2020
#上个例子简化版本 \w的使用
result = re.search('^[a-zA-Z]\w{5,}$',username)
print(result.group())
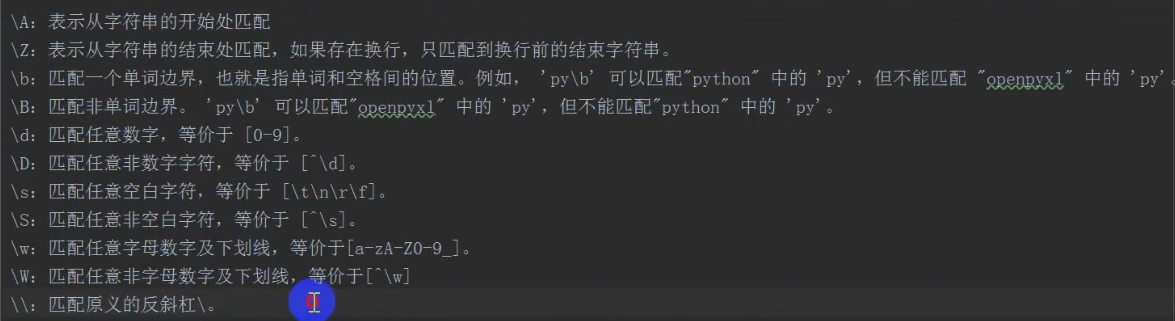
#\b的使用
#找到所有py文件名
'''
在正则中.表示任意字符(除\n)
r是原字符串,后面是什么就是什么,没有转义
r'.'中的.是正则中的.
r'\.'中的.就是普通的点
'''
msg = 'aa.py ab.py wc.py kk.png uc.gif abcpy'
result = re.findall('\w+.py\\b',msg) #\b需要转义,\b在字符串中有其他意义 或者加r
print(result) #输出为 ['aa.py', 'ab.py', 'wc.py', 'abcpy']
result = re.findall(r'\w+\.py\b',msg) #r防止出现转义的情况
print(result) #输出为 ['aa.py', 'ab.py', 'wc.py']
#验证手机号码
phone = '15988888888'
result = re.match('1[35789]\d{9}',phone)
print(result.group())
#匹配0-100的任意数字
import re
n=''
result=re.match('[1-9]?\d',n)
#当n=01时,输出 0,因为[1-9]可以有,可以没有,没有的话,就只有一位数字\d,那么match匹配到0就返回了
result=re.match(r'[1-9]?\d$',n)
#当n=01时,输出None,因为$结尾必须是一个数字。01不是一个数字,这种模式是不包括100的
result=re.match(r'[1-9]?\d$|100$',n)
#|表示或
print(result)
#验证邮箱 163 126 qq
#(163|126|qq)表示可以是163或者126或者qq,[163]表示是1或者6或者3
email = '2312342@qq.com'
result = re.match(r'\w{5,20}@(qq|163|126)\.(com|cn)',email)
print(result)
#验证不以4、7结尾的手机号码
phone = '15845135465'
result = re.match(r'1\d{9}[0-35-68-9]$',phone)
print(result)
#取区号跟电话号码
phone = '010-123456789'
result = re.match(r'(\d{3,4})-(\d{9})$',phone)
print(result)
#分别提取
#()表示分组,group(1)表示提取第一组的内容
print(result.group(1)) #输出 010
print(result.group(2)) #输出 123456789
#从标签中提取value值
msg='<html>abc</html>'
msg1='<h1>hello</h1>'
result = re.match(r'(<\w+>)+(\w+)+(</\w+>)$',msg1)
print(result.group(2)) #输出 hello
#第二种方法
result = re.match(r'<\w+>(.+)</\w+>$',msg1)
print(result.group(1)) #输出 hello
#这种方式如果msg=<html><h1>hello</h1></html>那么会输出<h1>hello</h1>
#取标签的升级版1.0
#因为标签是连对出现的,所以可以使用</\1>引用第一组匹配到的内容即<([0-9a-zA-Z]+)>
msg='<h1>hello world</h1>'
result = re.match(r'<([0-9a-zA-Z]+)>(.+)</\1>$',msg)
print(result.group(2)) #输出 hello world
#取标签的升级版2.0
#双重标签匹配
msg='<html><h1>hello world</h1></html>'
result = re.match(r'<([0-9a-zA-Z]+)><([0-9a-zA-Z]+)>(.+)</\2></\1>$',msg)
print(result.group(3)) #输出 hello world
'''
起名的方式
(?P<名字>正则)(?P=名字)
名字可以随便写,前后要呼应就行
'''
import re
msg = '<html><h1>abc</h1></html>'
result = re.match(r'<(?P<html>\w+)><(?P<h1>\w+)>(.+)</(?P=h1)></(?P=html)>',msg)
print(result) #输出 <_sre.SRE_Match object; span=(0, 25), match='<html><h1>abc</h1></html>'>
print(result.group(3)) #输出abc
学习来自:《python linux系统管理与自动化运维》 第四章 ,《python从入门到项目实践》明日科技 第七章, B站大学 p173-178 注意这几节是乱序,菜鸟教程
今天的学习是为了以后的工作更加的轻松!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号