2.spark structured streaming编程基本概念
1. 引言
接下来从使用spark structured streaming的示例等各个方面分析,spark提供了什么接口给我们使用以深入探究spark帮我们做了什么?
2. 示例代码
```java
//1.配置应用名称、参数等
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredKafkaWordCount")
.getOrCreate();
// 2.创建DataSet,一个dataset为kafka的一行数据
Dataset<String> lines = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option(subscribeType, topics)
.load()
.selectExpr("CAST(value AS STRING)")
.as(Encoders.STRING());
//3.对一行数据的单词进行分割,对数量进行统计
Dataset<Row> wordCounts = lines.flatMap(
(FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(),
Encoders.STRING()).groupBy("value").count();
//4.最后得到的数据,以表格形式输出到kafka中存储,开始进行流计算
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
//5.等待运行结束
query.awaitTermination();
```
3. 代码分步骤解析
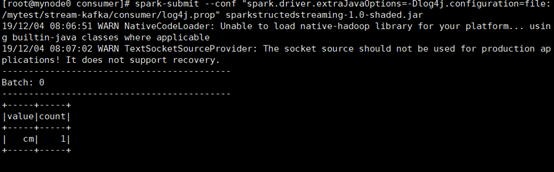
上述示例实现了对输入单词的统计,从kafka中读取一批数据,将数据按照Encoders.STRING()的格式进行解析,解析的数据按照行分割为单词,统计出现频次,将统计结果输出到控制台上。代码输出结果如下图所示
4.编程模型解析
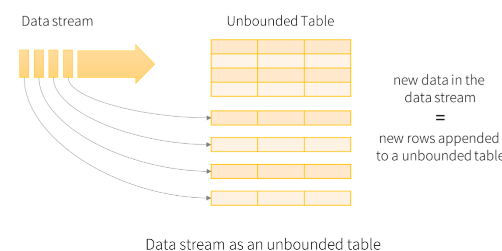
spark structured streaming 不管是批还是流都是统一的编程代码。需要指定应用设置、输入、处理过程、输出。
输入:将输入的数据看成是一张无边界的表格,任何从流中的数据都被当成是输入的一行追加到输入表中
处理:相当于对数据进行查询
输出:是一张结果表
5.无界(大)数据处理核心关注的问题
5.1what?计算的内容?
批处理中: 用变换(Transformations)解决 “What results are calculated?”spark 分为转换算子 以及 触发算子,
- 转换算子:如(map flatmap ),当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住数据集的逻辑操作;
- 触发atcion算子:如count(),foreach() start()等,触发Spark提交作业
流处理中:由于批处理数据是有界的,因此在所有数据到达之后上处理完所有数据后,就能得到正确结果。但是如果数据集是无界数据的话,这样处理就有问题(不知道数据何时结束)。
5.2where?对哪些数据实施计算?
1.首要条件: 批数据是流数据的子集
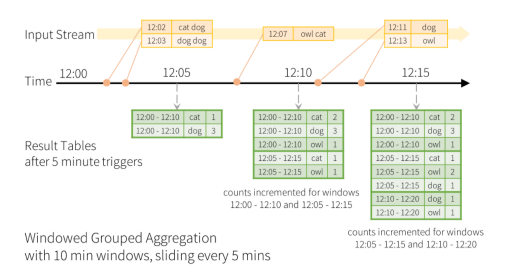
2.分割时间单位进行计算:按照事件时间,将数据切分到不同的窗口,每个窗口的结果进行计算。
3.spark中的窗口:
Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words.groupBy(
//其中时间由word中的数据项提供,可以是数据产生的时候自己带上的,也可以是进入spark的时候spark加上的
//5分钟统计一次,统计10分钟内数据,窗口大小为10min,但是5min增加一个窗口
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();
5.3when?什么时候计算?
** 批处理系统**:要等到所有数据都到齐才能输出计算结果,在无界数据流计算中是不可行的。
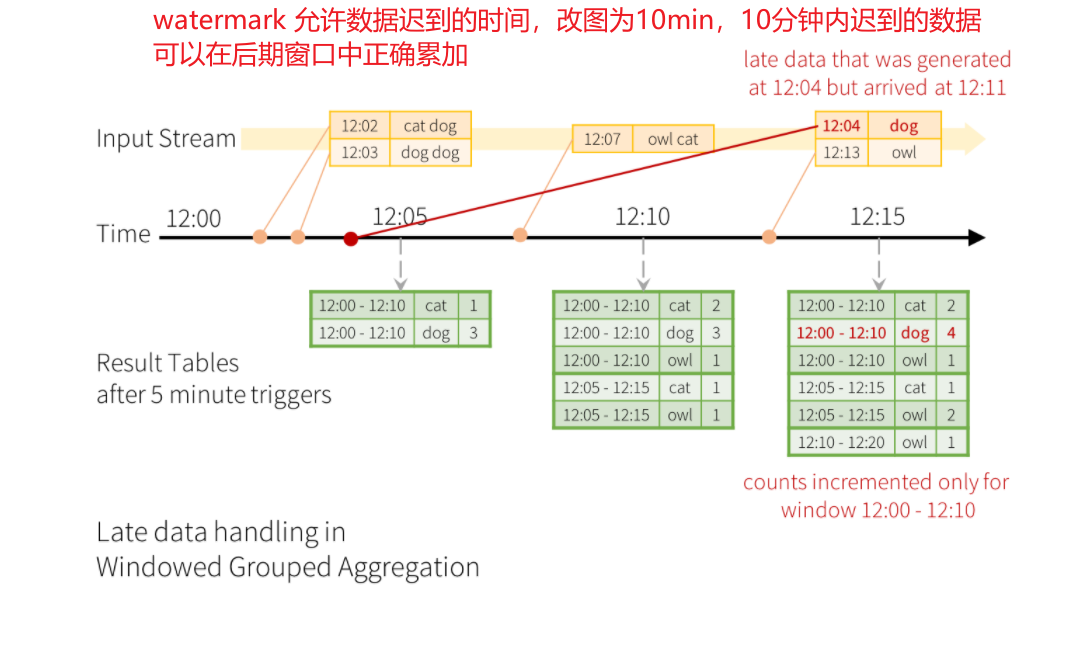
流系统:引入了watermark以及trigger
1.触发器会根据事件时间event time上的watermark来决定,在 处理时间(process time)的哪个时间点来输出窗口数据
| 触发器类型 | 描述 |
|---|---|
| 未指定 | 以微批模式(micro-batch)执行,只要前一批数据执行完成了就开始下一批 |
| 固定时间间隔的微批 | 查询将以微批模式执行,其中微批将按用户指定的间隔启动。如果前一个微批处理在间隔内完成,那么引擎将等待直到间隔结束后才启动下一个微批处理。如果前一个微批处理的完成时间超过了间隔时间(即错过了一个间隔边界),那么下一个微批处理将在前一个微批处理完成后立即开始(即不等待下一个间隔边界)。如果没有可用的新数据,则不会启动任何微批处理。 |
| One-time micro-batch | 查询将只执行一个微批处理来处理所有可用数据,然后自行停止。这在您希望周期性地启动集群、处理自上一个时间段以来可用的所有内容,然后关闭集群的场景中非常有用。在某些情况下,这可能会大大节省成本。 |
| Continuous with fixed checkpoint interval(experimental) | 查询将以新的低延迟、连续处理模式执行 |
df.writeStream
.format("console")
//要在连续处理模式下运行受支持的查询,您所需要做的就是指定一个连续触发器,并将所需的检查点间隔作为参数
//检查点间隔为1秒意味着连续处理引擎将每秒记录查询的进度,支持微批和连续模式的互换
.trigger(Trigger.ProcessingTime("2 seconds"))
.start();
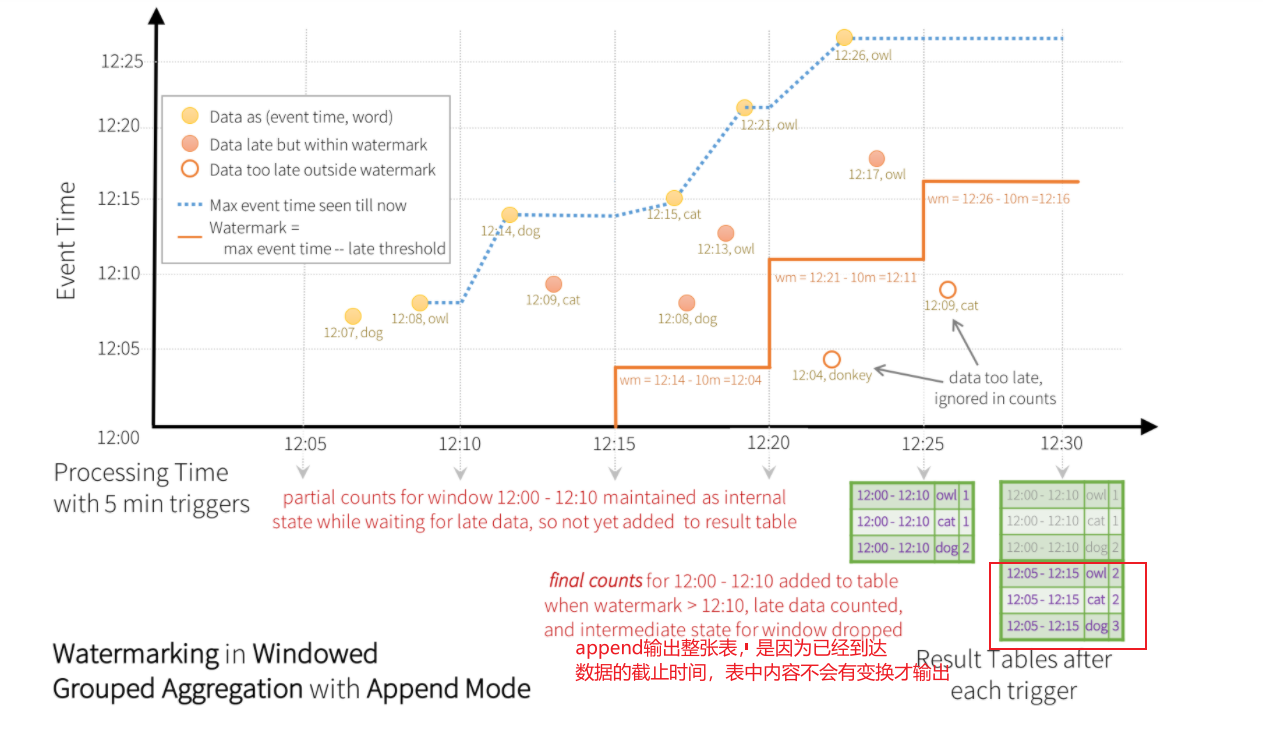
流系统:引入了watermark,是某个event time窗口中所有数据都到齐的标志。一旦窗口的watermark到了,那么这个event time窗口里的数据就到齐了,可以被物化不比继续存储为中间状态了
val windowedCounts = words
//在处理时间10:15分的时候,窗口大小为产生event时间(10:0 ~ 10:10),不接收产生event时间 10:5分以前的数据,第一个窗口数据全部到达,如果触发器时间到了可以直接处理
// (10:5 ~ 10:15)
// (10:10 ~ 10:20)
.withWatermark("timestamp", "10 minutes")
.groupBy(
//窗口时延为10分钟,5分钟创建一次窗口 (event time)
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()

5.4how?遇到迟到的数据,如何处理之前触发器输出的结果?
追加模式: ——这是默认模式,其中只有自最后一个触发器以来添加到结果表的新行才会输出到接收器。只支持那些添加到结果表的行永远不会更改的查询。因此,这种模式保证每行只输出一次(假设接收是容错的)。例如,只有select、where、map、flatMap、filter、join等的查询将支持追加模式
完成模式——在每个触发器之后,整个结果表将被输出到接收器。聚合查询支持这一点。
更新模式:——(自Spark 2.1.1以来可用)只有结果表中自上次触发以来更新的行将输出到接收。在以后的版本中要添加的更多信息。
6.总结
- spark中的计算过程在map等转换算子中,用窗口解决计算数据量的问题,用触发器解决输出时间的问题,用watermark解决临时状态数据量过大的问题,用输出模式append update complete解决更新的数据处理的问题
- spark中的触发器是用来表示在处理时间间隔(process)后输出结果
- spark中的窗口表示计算的数据量,窗口使用的是event time
- spark中的watermark确定临时状态的保存时间以及append模式最后可以输出的时间(process time)
参考链接:
https://blog.csdn.net/xxscj/article/details/84989879
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号