为什么一定要学习正则表达式
为什么一定要学正则表达式
前言
为什么有正则表达式,以及为什么一定要学习正则表达式?
本文不去讨论正则表达式的历史,流派以及完整而复杂的用法,仅仅通过一个简单的搜索场景,把你带入正则表达式的世界,从此你将感受到“海阔凭鱼跃、天高任鸟飞”的痛快!,回归正题,假设有一份名单,如下所示:
张仲景
刘德华
刘亦菲
张良
刘欢
张居正
葛振林
刘邦
李世民
葛云飞
刘彻
刘禹锡
李清照
诸葛亮
刘伯温
刘备
葛优
任务场景
最简单的搜索任务:在文本中搜索“刘德华”
很简单,只要在搜索框中输入“刘德华”再搜索就可以了,一般的文本编辑器都支持这个功能。
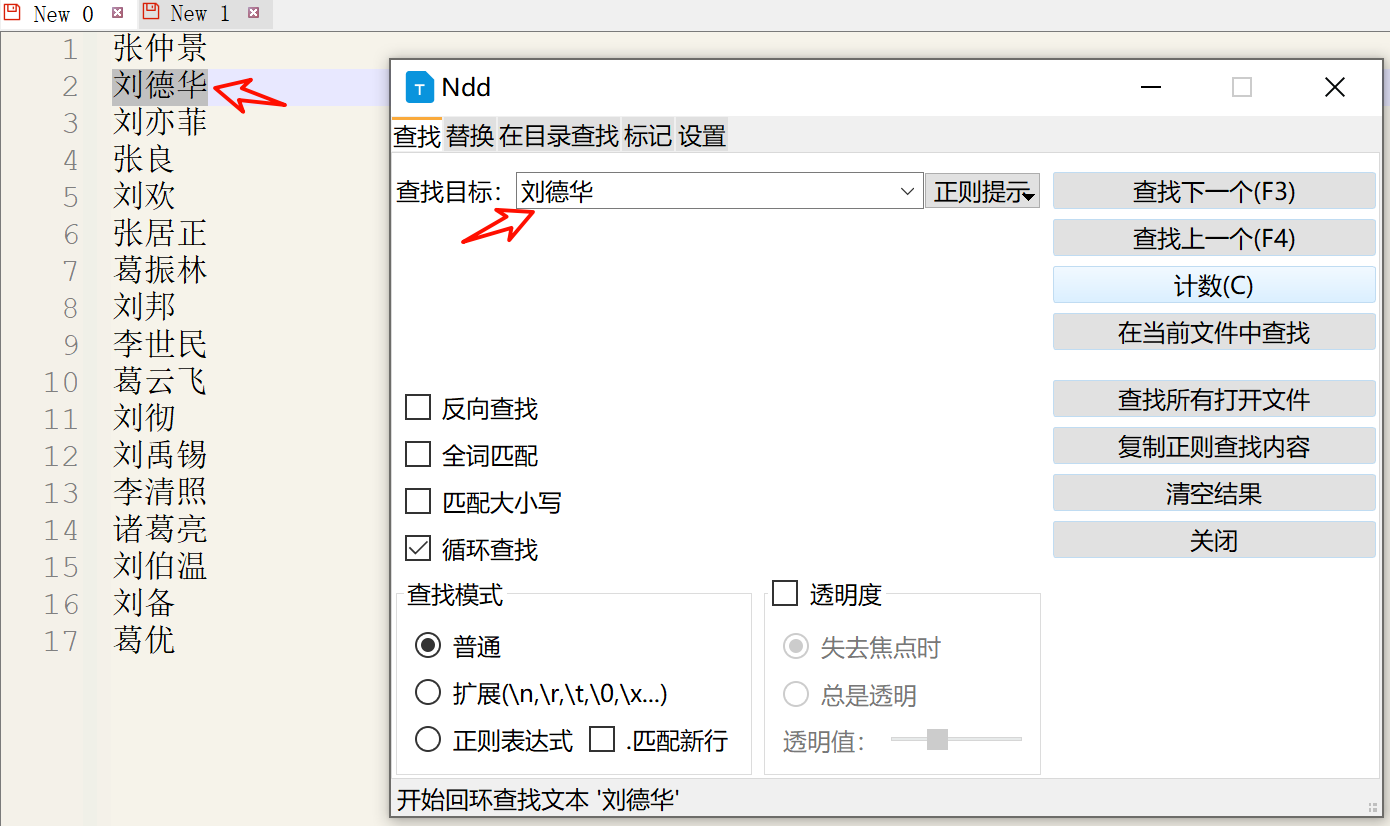
搜索结果显示“刘德华”已经成功被找到!
一眼简单,但多坑的搜索任务:在文本中搜索所有姓“葛”的人
很多编辑器或阅读工具都提供“通配符”,可以用来进行模糊查找:
? : 表示匹配一个字符
* : 表示匹配任意个字符(包括一个都没有)
- 第1回合:在搜索框中输入“葛??”就好了, 是这样吗?
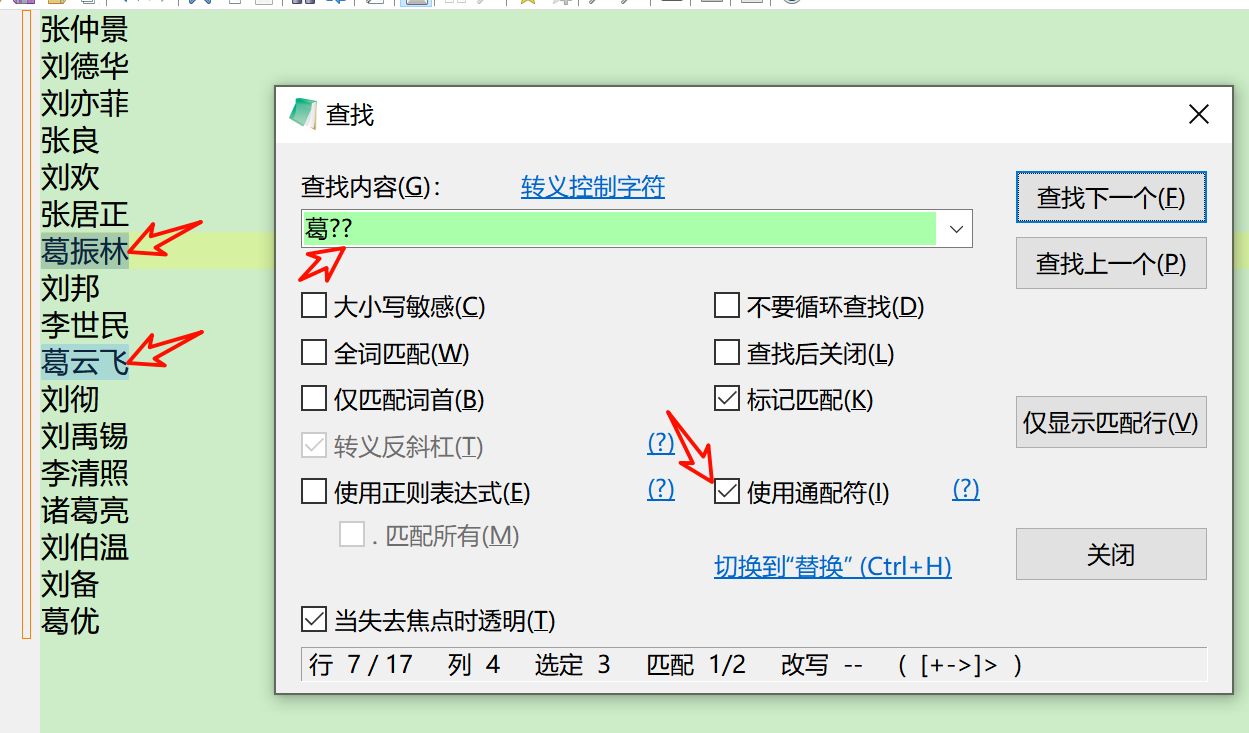
问题:你发现“葛优”,没有搜索出来!
- 第2回合:好吧,不用(?)号了, 用(*)号, 搜索“葛*”,这回应该没有问题了吧!是这样吗?
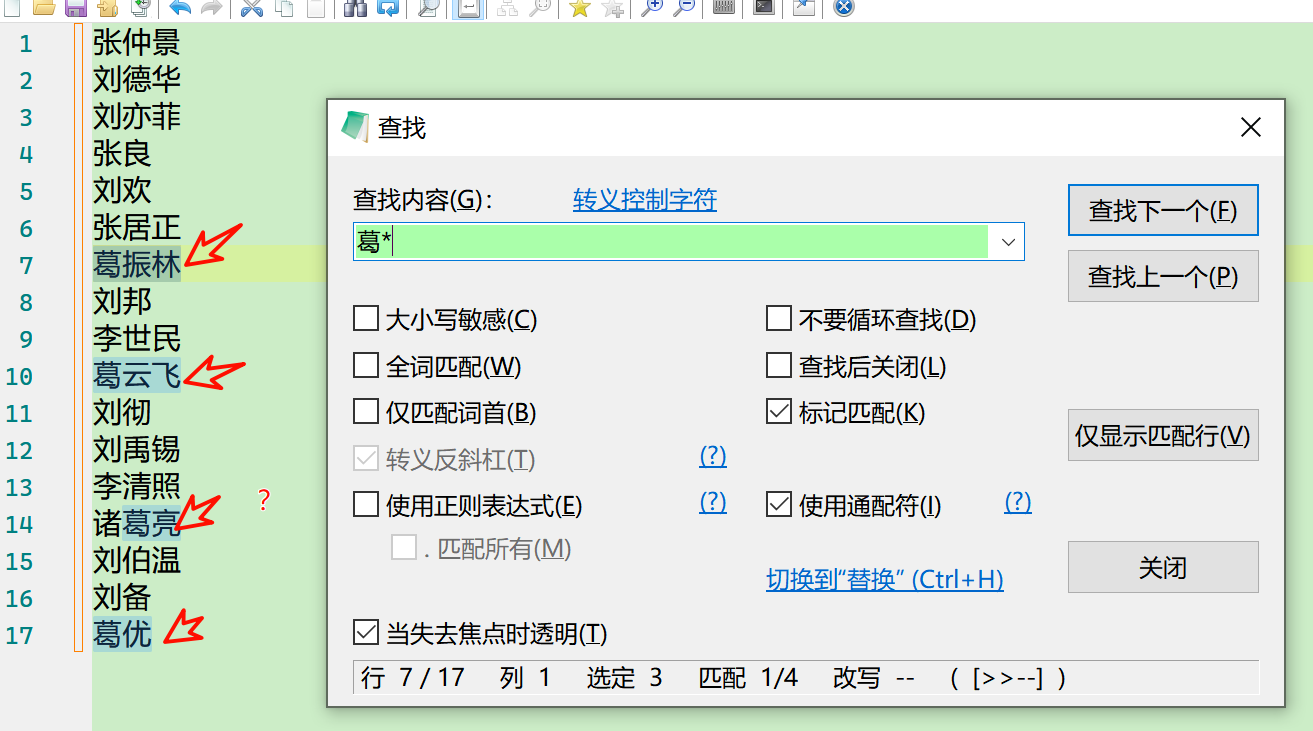
问题:“葛亮”是什么鬼?
- 第3回合:最后,我们来试试正则表达式!在搜索框输入“^葛.*”
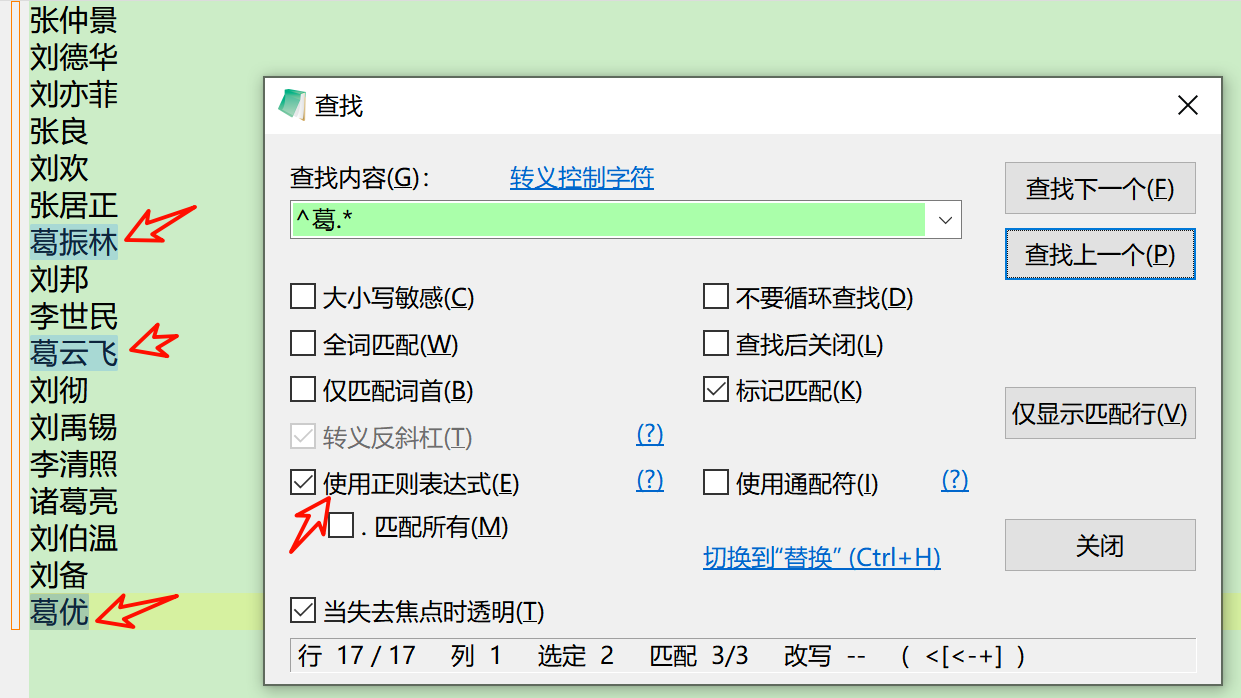
OK、完美的找出了所有姓“葛”的人,并且没有误判。至于这段字符是什么意思,请阅读下文。
🕮说明:常见的正则表达式字符及功能
| 字符 | 功能描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符,或一个原义字符,或一个向后引用,或一个八进制转义符。例如,”\n”匹配一个换行符。 |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| * | 匹配前面的子表达式零次或多次,等价于 |
| + | 匹配前面的子表达式一次或多次,等价于 |
| ? | 匹配前面的子表达式零次或一次,等价于 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串”oooo”,”o+?”将匹配单个”o”,而”o+”将匹配所有的”o”。 |
| N是一个非负整数,匹配确定的n次。 | |
| N是一个非负整数,至少匹配n次。 | |
| M和n均为非负整数,其中n<=m,最少匹配n次且最多匹配m次。 | |
| . | 匹配除”\n”之外的任何单个字符。要匹配包括”\n”在内的任何字符,请使用像”[.\n]”的模式 |
| (pattern) | 匹配pattern并获取这一匹配。 |
| (?:pattern) | 匹配pattern但不获取匹配结果。这在使用“或”字符( |
| (?=pattern) | 正向预查,在任何匹配pattern的字符串开始处匹配查找字符串。例如:”Windows(?=95 |
| (?!pattern) | 负向预查,在任何不匹配pattern的字符串开始处匹配查找字符串。例如:”Windows(?!95 |
| x | y |
| [xyz] | 字符集合,匹配所包含的任何一个字符。 |
| [^xyz] | 负值字符集合,匹配未包含的任意字符。 |
| [a-z] | 字符范围,匹配指定范围内的任意字符。 |
| [^a-z] | 负值字符范围,匹配任何不在指定范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是单词和空格间的位置。 |
| \B | 匹配非单词边界。 |
| \cx | 匹配由x指明的控制字符。X的值必须为A-Z或a-z之间 |
| \d | 匹配一个数字字符。等价于[0-9] |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \f | 匹配一个换页符。等价于\x0c和\cL |
| \n | 匹配一个换行符。等价于\x0a和\cJ |
| \r | 匹配一个回车符。等价于\x0d和\cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。 |
| \S | 匹配任何非空白符。 |
| \t | 匹配一个制表符 |
| \w | 匹配包括下划线的任何单词字符。等价于[a-zA-Z0-9_] |
| \W | 匹配任何非单词字符。 |
| \xn | 匹配n,其中n为十六进制转义值。例如”\x41”匹配”A”。 |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如:”(.)\1” |
以上正则表达式字符和规则,仅仅是正则表达式的冰山一角,读者入门后可以根据精力更加深入的去学习正则表达式。
文档作者声明:本文档仅用于学习交流,未经作者许可,不得将本文档用于其他目的。
Copyright © 2022~2024 All rights reserved.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号