
分类结果评估
五、分类结果评估
(1)数据集:
采用2万多篇文档的数据集中的0.3测试集来计算roc,一共有6802篇文章的题目和摘要。
(2)精确度、召回率、F值:
混淆矩阵(Confusion Matrix):

真正例(True Positive;TP):将一个正例正确判断成一个正例
伪正例(False Positive;FP):将一个反例错误判断为一个正例
真反例(True Negtive;TN):将一个反例正确判断为一个反例
伪反例(False Negtive;FN):将一个正例错误判断为一个反例
Ⅰ.精确率(Precision)
预测为正例的样本中,真正为正例的比率.

精确率本质来说是对于预测结果来说的.表示对于结果来说,我对了多少。
Ⅱ.召回率(Recall)
预测为正例的真实正例(TP)占所有真实正例的比例.
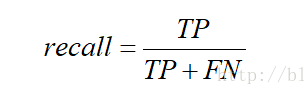
召回率是对于原来的样本而言的.表示在原来的样本中,我预测中了其中的多少。
Ⅳ.F值
表示精确率和召回率的调和均值


微精确度为多个混淆矩阵的精确率的平均 微精确度:0.758751607
微召回率为多个混淆矩阵的召回率的平均 微召回率:0.763060747
微F1: 0.76090008
(3)AUC和ROC曲线
Ⅰ.FPR伪正类率(False Positive Rate,FPR)
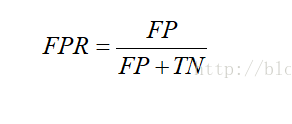

Ⅱ.TPR真正类率(Ture Positive Rate,TPR)
预测为正且实际为正的样本占所有正样本的比例.你会发现,这个不就是召回率
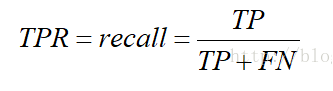
ROC就是对于一个分类器,给定一些阈值,每一个阈值都可以得到一组(FPR,TPR),以FPR作为横坐标,TPR作为纵坐标
AUC:为ROC曲线下面积
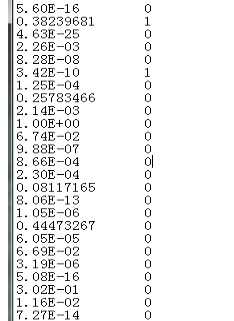
第一列是每一篇文献属于这一类的概率
第二列是真实的类别 如果属于这类就为1,不属于就为0
放入Excel中,然后再使用R语言计算AUC,可以直接画出ROC曲线。
第一步:首先加载这个选中的程序包

第二步,导入文件:

第三步:画图,FALSE和TURE是做升序还是降序

第四步:前百分之多少的AUC
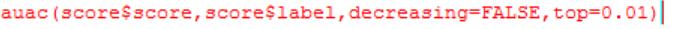
(其中top=0.01可以不设置)
第五步:算AUC


 浙公网安备 33010602011771号
浙公网安备 33010602011771号