

python jieba库
jieba库
分词原理
Jieba分词依靠的是一个强大的中文库,确定汉字自检的关联概率,概率大的组成词组,形成了分词的结果。除了分词呢,用户还可以添加自定义的词组。
Jieba分词的三种模式:
1.精确模式:把文本精确的切分开,不存在冗余单词
2.全模式:把文本中所有可能的词语都扫描出来,有冗余
3.搜索引擎模式:在精确模式基础上,对长词再次切分
| 函数 | 描述 |
|---|---|
| jieba.lcut(s) | 精确模式,返回一个列表类型的分词结果 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型的分词结果,有冗余 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型的分词结果,有冗余 |
| jieba.add_word(w) | 向分词词典中增加新词w |
实例
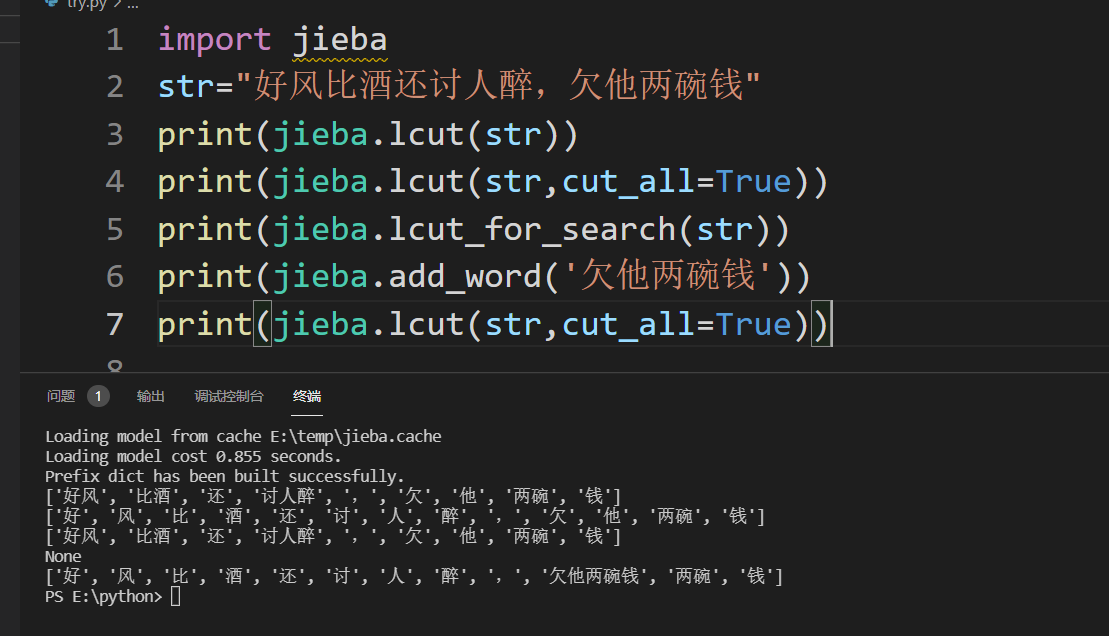
#实例代码
import jieba
str="好风比酒还讨人醉,欠他两碗钱"
print(jieba.lcut(str))
print(jieba.lcut(str,cut_all=True))
print(jieba.lcut_for_search(str))
print(jieba.add_word('欠他两碗钱'))
print(jieba.lcut(str,cut_all=True))
计算机二级例题[1]

答案
#答案
import jieba
txt = input(“请输入一段中文文本:”)
Is=jieba.lcut(txt)
print( "{ :.If) ".format( len( txt)/len( Is)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号