大数据拾遗
MapReduce
-
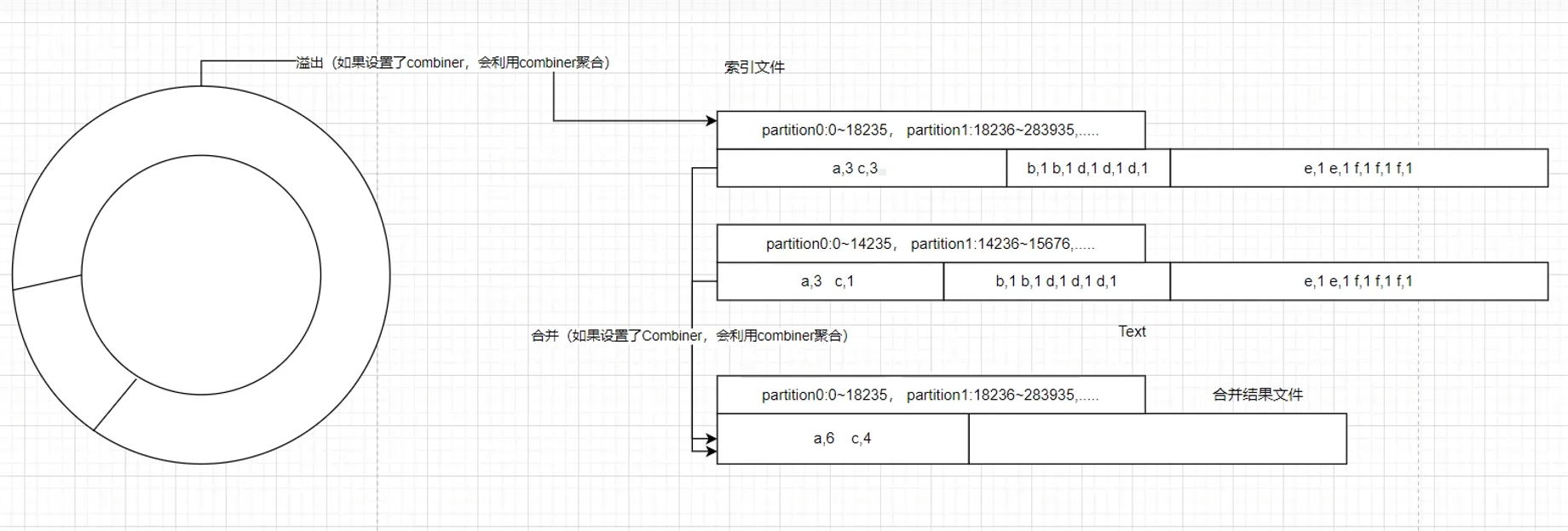
record reader读取到输入文件根据指定FileInputFormat格式解析内容并组织输入的(k,v),不同的输入文件的Key代表的含义不一样好比text的hdfs文件key表示的物理文件的字符偏移量,然后对(k,v)进行自定义的map逻辑处理处理完成后交给collector,丢进环形缓冲区。
-
环形缓冲区溢出的数据落盘成文件的同时会伴随索引文件的更新,索引文件记录的是生成的临时文件:文件号(P0、P1):map输出内容物理偏移量。
以下为环形缓冲区落盘的满足条件。-
当环形缓冲区中的数据量达到一定阈值(如128MB)
-
时间窗口到达一定时间
-
触发线程将缓冲区中的数据进行排序和分区,并将每个分区的数据写入临时文件中。
这种环形缓冲区落盘机制能够充分利用内存进行中间结果的存储和排序,减少了磁盘I/O操作,从而提高了整个MapReduce作业的性能和效率。
-
-
maptask全部处理完毕后,会在map端进行一次全局排序(shuffle),将缓冲区生成的临时文件进行排序合并。
-
如果设置了combiner,则会在溢出和合并时运行设定的reduce计算逻辑(前提是计算逻辑支持提前运算),会大大减少网络传输的文件大小,map->reduce过程中会伴随网络IO甚至跨机架。
-
Reduce任务读取分区文件进行处理,最终输出结果。
- 从上游maptask的输出文件拉取属于自己partition的数据,并将拉取过来的数据进行排序合并。
- GroupingComparator是迭代器判断hasNext的重要依据(是否为同一组数据)。

Hive
执行计划
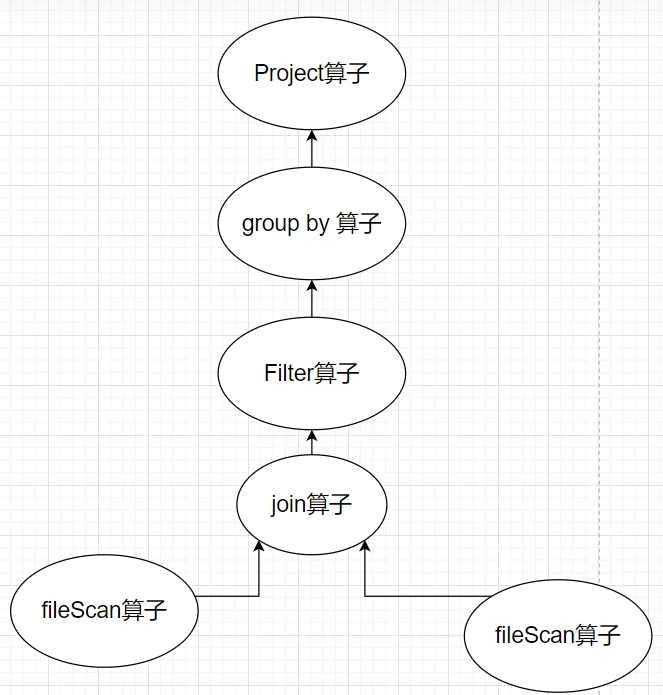
执行计划:Sql语句->逻辑执行计划->语法优化->物理执行计划。
sql语句
原生sql语句逻辑执行计划
匹配元数据、数据库方言以及数据位置生成逻辑执行计划。语法优化
根据方言语境以及语义针对性优化Sql语法物理执行计划
根据物理执行引擎转化为物理执行计划(MapReduce/Spark/Tez)
调试技巧
-
本地化
当测试较小量数据时,将执行引擎改为本地,因为一些特殊用法所以不建议在mysql中,试运行 (当然一些join也是可以满足的。)- 使用Hive CLI并且使用
-local参数。
hive -e 'Your SQL Here' -local- 在Hive Shell中动态设置MapReduce框架为本地。
SET mapreduce.framework.name=local; - 使用Hive CLI并且使用
示例展示
-
有四列数据,姓名,院系,学科,成绩,求每个系总成绩最高的一个学生的姓名,用rank over和max over实现
- rank over
SELECT name, department, total_score FROM ( SELECT name, department, SUM(score) AS total_score, RANK() OVER (PARTITION BY department ORDER BY SUM(score) DESC) as rank FROM students GROUP BY name, department ) AS sub_query WHERE rank = 1;- max over
WITH ranked_students AS ( SELECT name, department, SUM(score) AS total_score, MAX(SUM(score)) OVER (PARTITION BY department) AS max_score FROM students GROUP BY department, name ) SELECT name, department, total_score FROM ranked_students WHERE total_score = max_score; -
有三列数据,用户、打靶顺序、是否命中,计算连续三次命中的用户
- lag over
# 统计连续三次击中靶的用户 /* 1.先用lag函数和当前行比较,如果当前行的user_id和lag行的user_id相同,说明是连续击中 2.统计连续击中靶的用户,就是统计连续击中靶的用户的数量 */ select user_id,sum(if_contiue_flag) from (select user_id,seq_no, if(if_hit=lag(if_hit,1) over (partition by user_id order by seq_no)=1,1,0) as if_contiue_flag from hit_test) t group by user_id having sum(if_contiue_flag)>=2;- row_numer over
/* 1,2,1 1,3,1 1,4,1 1,10,6 2,2,1 2,5,3 2,8,5 3,6,5 先过滤出命中的打靶顺序,然后用打靶顺序减去序号来判断是否为连续命中 */ select user_id,count(sn) from ( select user_id,seq_no, seq_no-row_number() over (partition by user_id order by seq_no) as sn from hit_test where if_hit=1) t group by user_id,sn having count(sn)>=3; -
字符串运算符
select "a"||"b"; # ab
知识点
Sql执行顺序
SELECT
st.gender,AVG(s.chinese_score) as avg_chine_score
FROM `students` st JOIN `score` s
on st.id = s.student_id
WHERE s.chinese_score>=60
GROUP BY st.gender
HAVING avg_chine_score>=80
ORDER BY avg_chine_score DESC
LIMIT 2;
FROM+JOIN -> WHERE-> GROUP BY -> HAVING ->SELECT->SELECT->ORDER BY -> LIMIT
-
FROM:首先执行
FROM子句,组合所有指定的表。在这里,我们有students st和score s两张表,并使用JOIN进行了联接(匹配了st.id = s.student_id)。 -
WHERE:然后,执行
WHERE子句,从上一步得到的结果集中筛选出满足条件chinese_score>=60的记录。 -
GROUP BY:接着,执行了
GROUP BY,将上一步的结果按照st.gender进行分组。 -
HAVING:然后,执行
HAVING子句,筛选出满足条件avg_chine_score >= 80的组(在GROUP BY之后HAVING进行筛选,不同于WHERE子句,在GROUP BY之前进行筛选,这两者的区别值得注意)。 -
SELECT:下一步,执行
SELECT,选择需要的字段。这里我们选择了st.gender和平均分AVG(s.chinese_score)。 -
ORDER BY:使用
ORDER BY对结果进行排序。这里是按照avg_chine_score进行降序排序。 -
LIMIT:最后,执行
LIMIT限制返回结果的数量。这里我们只返回了前两个结果。
请注意,虽然SELECT语句写在查询的最前面,但它在实际的执行过程中却是在较后的阶段被执行的。 这是因为我们必须在选择字段之前知道要从哪些记录中选择字段。
with和子查询的异同点
WITH子句(也被称为公共表表达式或CTE)和子查询都是 SQL 提供的强大工具,它们都允许我们在复杂的查询中创建临时的结果集。他们之间在查询效率上的差异主要取决于特定数据库的实现和查询的具体情况。
在很多情况下,WITH子句和子查询的性能是相似的。但也有一些例外:
-
可读性和维护性:在有很多级联查询和复杂查询逻辑时,
WITH子句通常会比子查询提供更高的可读性和维护性。因为你可以为每个WITH子句分配一个描述性的名称,这有助于其他读你代码的人理解你查询的逻辑。 -
重复利用:如果你对一个临时结果集进行多次查询操作,
WITH子句有时会更高效,因为它们在查询开始时就执行,然后结果可以用于多次查询不需要再次计算。 -
递归查询:在需要进行递归查询的情况下,只有
WITH子句才能处理这种情况,子查询做不到。
总的来说,这两者之间在查询效率上的差异主要依赖于查询的复杂性和数据库的特殊实现。当你写复杂的查询时,最好都试一下,然后选择在你的特定情况下表现最好的那个。
不同序号的区别
在 SQL 中,RANK(), ROW_NUMBER() 和 DENSE_RANK() 都是窗口函数,用于为每个窗口(或分区)中的行进行排序和编号。但它们在处理排名时存在一些关键差异:
-
ROW_NUMBER():为结果集中的每一行分配唯一的数字。即使两行具有完全相同的排序值,它们也会被赋予不同的行号。 -
RANK():为结果集中的每一行分配数字,对于排名相同的行(即具有完全相同排序值的行),会分配相同的排名。然后,下一个行的排名数会增加,增加的值等于之前相同排序值的行数。因此,RANK()可能会跳过一些数字。 -
DENSE_RANK():与RANK()类似,也为相同的排序值的行分配相同的排名。不同之处在于,DENSE_RANK()不会跳号,下一个排序值的行总是当前行排名数加一。
这是一个例子来说明这三个函数的区别:
| row_number | rank | dense_rank | score |
|---|---|---|---|
| 1 | 1 | 1 | 95 |
| 2 | 1 | 1 | 95 |
| 3 | 3 | 2 | 90 |
| 4 | 4 | 3 | 85 |
ROW_NUMBER()赋予每个学生都有不同的行号。RANK()给两个得95分的学生分配了相同的排名(1名),然后给得90分的学生分配了3名(跳过了2名)。DENSE_RANK()给得95分的学生分配了相同的排名(1名),然后给得90分的学生分配的是2名(没有跳号)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号