langchain实践
原理篇
LLM模型,学术意义上这个大体现在供给给模型的训练样本很大,对我们使用者来说我们可以认为他海纳百川,有容乃大。学的足够多, 博学。所以你要跟它对话,需要先告诉它你充当的角色是谁,也就是你要获得知识的来源。
LangChain可以标准化和抽象化整个大语言模型使用过程。
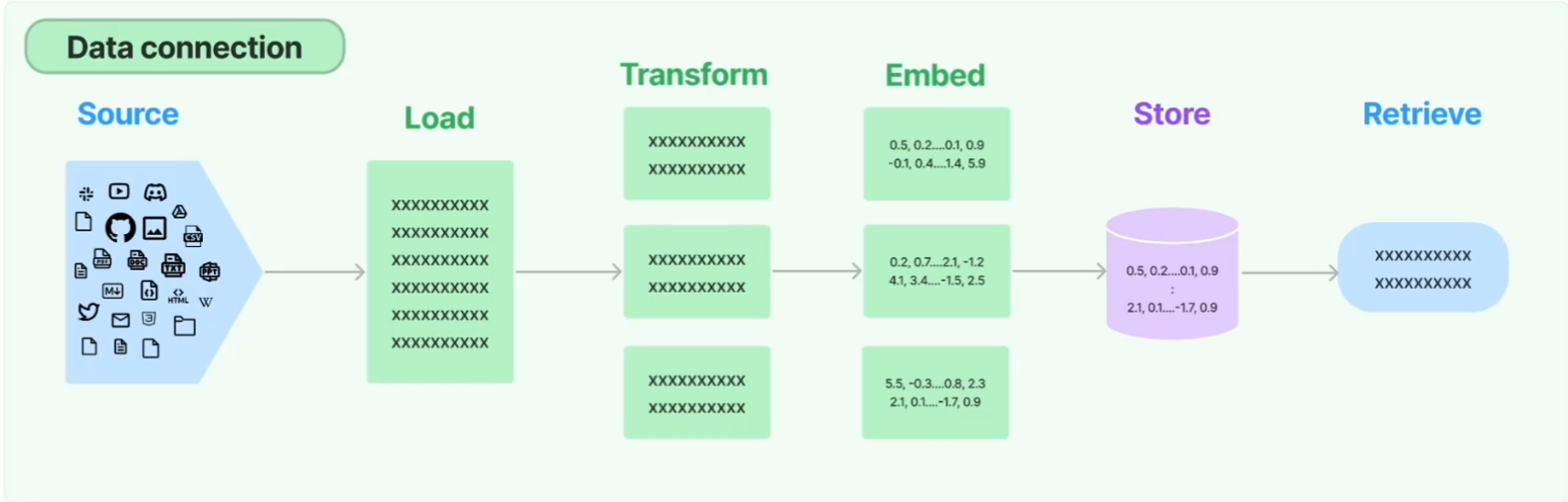
- 文本加载
- 从各种数据源中加载文本语料。
- 你关心的数据,可以是自己现成的也可以是第三方供给的。
- 文本转换(切割)
嵌入容器入口有大小限制,切割后的文档有重合,便于关联文档上下文。 - 文本词嵌入(数字向量化)
文本词数字向量化,多维化。 - 词嵌入向量的存储和检索
存入向量数据库返回检索器
W模型,是一种用于写作文的方法,它指的是根据Who(谁),What(什么),When(何时),Where(何地),Why(为什么),How(如何)等问题,来组织文章的内容和结构;W模型可以帮助我们清晰地回答文章的基本问题,使文章更有逻辑和条理。
在这个例子中,我们可以根据以下方式来分析Prompt架构中的W模型:
- Who:谁是文章的作者,谁是文章的读者,谁是文章的主角。在这个例子中,文章的作者是我们,文章的读者是预训练语言模型(LLM),文章的主角是文本分类任务。
- What:文章的主题是什么,文章的目的是什么,文章的内容是什么。在这个例子中,文章的主题是情感分析,文章的目的是指导LLM完成文本分类任务,文章的内容是一个cloze prompt,包括输入部分和输出部分。
- When:文章发生在什么时间,文章的时效性如何,文章的时序关系如何。在这个例子中,文章发生在当前,文章的时效性较高,文章的时序关系是先输入后输出。
- Where:文章发生在什么地点,文章的空间关系如何,文章的范围如何。在这个例子中,文章发生在计算机中,文章的空间关系是输入部分和输出部分之间用分隔符隔开,文章的范围是一句话。
- Why:文章的动机是什么,文章的意义是什么,文章的论点是什么。在这个例子中,文章的动机是利用LLM的泛化能力和迁移能力,减少对有监督数据的依赖,文章的意义是实现小样本学习的目标,文章的论点是根据输入部分的情感倾向,输出正确的类别。
- How:文章的方法是什么,文章的结构是什么,文章的技巧是什么。在这个例子中,文章的方法是使用cloze prompt,文章的结构是输入部分和输出部分,文章的技巧是使用特殊符号或标记来分隔输入部分和输出部分,以及使用变量或元数据来表示参数。
开发篇
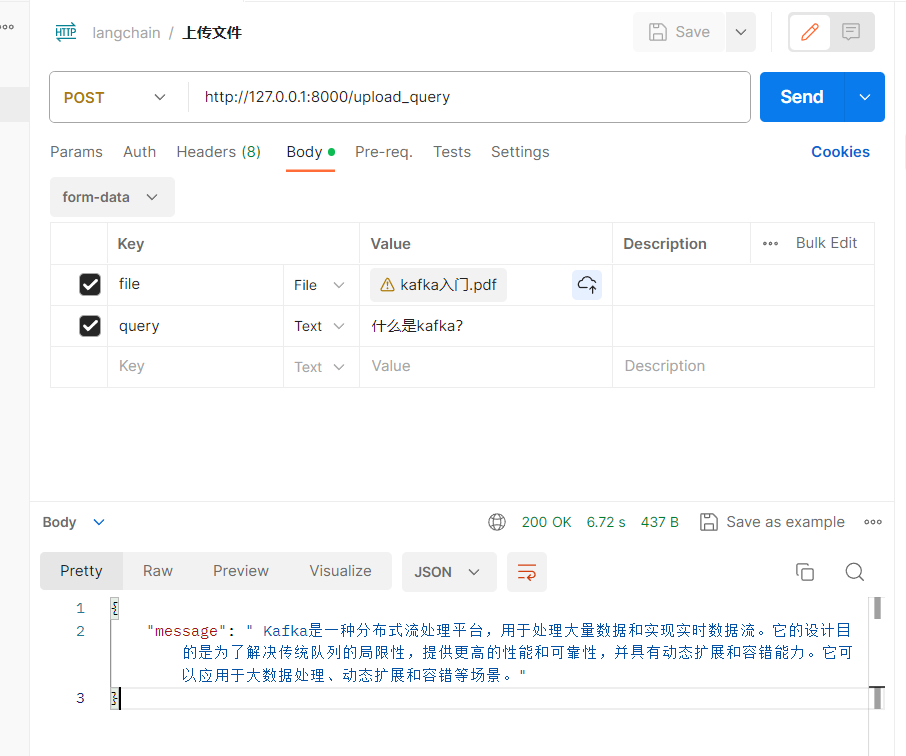
上传一个pdf文档,将文档转换为向量化语料喂给OpenAILLM模型,同时向它提问问题,回答内容和文档强相关。
- PostMan中API验证
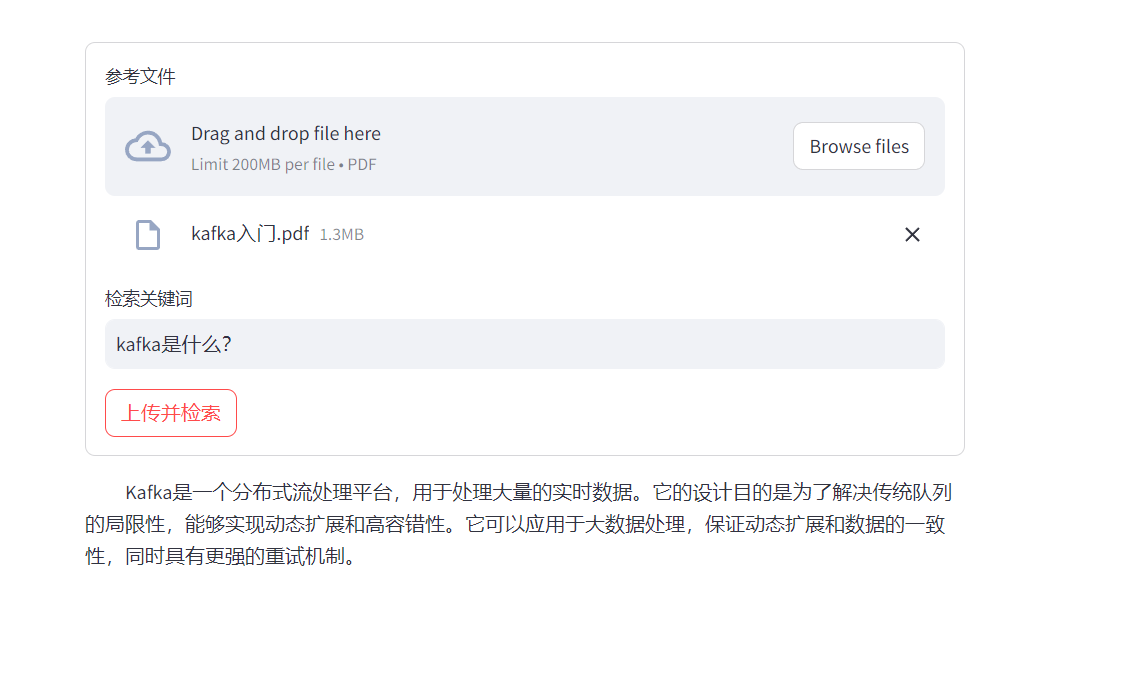
- 实现结果
-
python-dotenv
初始化各种环境变量
pip install -U python-dotenv touch .env配置项 配置值 OPENAI_API_KEY 'sk-xx' OPENAI_API_BASE "https://xxx" request_timeout "10000" https_proxy "http://127.0.0.1:58309" http_proxy "http://127.0.0.1:58309" upload_path_prefix xxxx/ save_vector_prefix xxxx/ -
fastapi
快速构建Backend API接口,类似Java Servlet、Spring MVCpip install -U fastapi -
streamlit
快速构建 Frontend UI ,提供UI和后端进行交互。
pip install -U streamlit -
chromadb
本地化向量数据库pip install chromadb -
构建后端服务
uvicorn backend_api:app --reload -
构建前端
streamlit run frontend_face.py
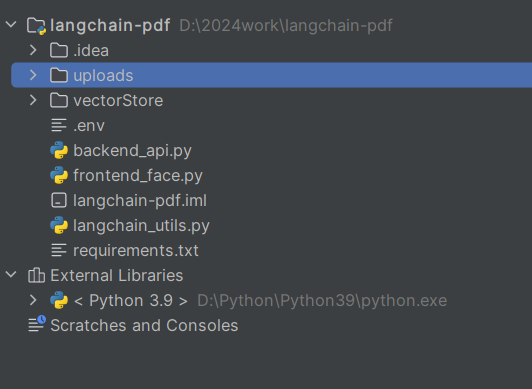
项目结构
具体实现
-
backend_api
from fastapi import FastAPI, UploadFile, File, Form from fastapi.responses import JSONResponse from langchain_utils import * app = FastAPI() @app.post("/upload_query") async def upload_query(file: UploadFile = File(...), query: str = Form(...)): try: upload_file(file) res = query_with_index(query,file.filename) return JSONResponse(content={"message": res}) except Exception as e: return JSONResponse(status_code=500, content={"message": f"Error occurred: {e}"}) -
frontend_face
import streamlit as st import requests form = st.form(key='my_form') uploaded_file = form.file_uploader('参考文件', type=['pdf']) text = form.text_input('检索关键词') submit_button = form.form_submit_button('上传并检索') if submit_button: # assuming the server is running on localhost and port 8000 url = "http://127.0.0.1:8000/upload_query" if uploaded_file is not None: # convert to bytes bytes_data = uploaded_file.getvalue() files = {'file': (uploaded_file.name, uploaded_file.getvalue())} else: file = None data = {'query': text} response = requests.post(url, files=files, data=data) if response.ok: # 获取后端返回的结果 result = response.json() # 显示结果 # 使用 st.markdown 来渲染结果,并添加一些样式 st.markdown(f""" <p style="text-indent:2em">{result['message']}</p> """, unsafe_allow_html=True) else: st.write('在提交过程中出现了错误') -
langchain_utils
# # # 1.从Http Multi File文件流加载文件到服务器,这一步在API已完成 # # 2.从服务器路径加载文件到向量数据库 import os.path import shutil from dotenv import load_dotenv from langchain.indexes import VectorstoreIndexCreator from langchain.indexes.vectorstore import VectorStoreIndexWrapper from langchain_community.document_loaders import PyPDFLoader from langchain_community.embeddings import OpenAIEmbeddings from langchain_community.vectorstores.chroma import Chroma load_dotenv() local_persist_path = os.getenv("save_vector_prefix") upload_path_prefix = os.getenv("upload_path_prefix") # 从网络IO上传文件存到服务器端 def upload_file(file): save_path = get_file_path(upload_path_prefix,file.filename) if not (os.path.exists(save_path)): with open(f"{save_path}", "wb") as buffer: shutil.copyfileobj(file.file, buffer) # 构建地址和文件的相对路径 def get_file_path(path_prefix,indexName): return os.path.join(path_prefix,indexName) # 加载服务端上传好的文件到Chroma本地向量数据库 def load_file_2_VectorStore(file): loader = PyPDFLoader(file_path=get_file_path(upload_path_prefix,file)) save_path = get_file_path(local_persist_path,file) # 存在加载保存的数据进Chroma内存向量数据库 if (os.path.exists(save_path)): vectorstore = Chroma( embedding_function= OpenAIEmbeddings(), persist_directory = save_path ) return VectorStoreIndexWrapper(vectorstore=vectorstore) # 不存在生成并返回同时保存到本地 else: return (VectorstoreIndexCreator(vectorstore_kwargs={"persist_directory":save_path}).from_loaders(loaders=[loader])) # 用生成的向量数据库加载数据到OpenAI生成知识库,用知识库检索问题的答案 # mapreduce的处理模式适合大文件场景,可以分块切割然后在reduce阶段聚合归并最终结果。 def query_with_index(query,filename): return load_file_2_VectorStore(filename).query_with_sources(query,chain_type="map_reduce")
知识点
Agent ReAct
Action agents
ReAct: Synergizing Reasoning and Acting in Language Models – Google Research Blog
Plan And Execute Agent
MapReduce
适合大文件场景,可以分块切割然后在reduce阶段聚合归并最终结果。
from functools import partial
from langchain.schema import Document
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import format_document
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from initChatAI import ChatGPTConfig
ChatGPTConfig()
llm = ChatOpenAI()
# Prompt and method for converting Document -> str.
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt)
# The chain we'll apply to each individual document.
# Returns a summary of the document.
map_chain = (
{"context": partial_format_document}
| PromptTemplate.from_template("Summarize this content:\n\n{context}")
| llm
| StrOutputParser()
)
# A wrapper chain to keep the original Document metadata
map_as_doc_chain = (
RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain})
| (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)")
# The chain we'll repeatedly apply to collapse subsets of the documents
# into a consolidate document until the total token size of our
# documents is below some max size.
def format_docs(docs):
return "\n\n".join(partial_format_document(doc) for doc in docs)
collapse_chain = (
{"context": format_docs}
| PromptTemplate.from_template("Collapse this content:\n\n{context}")
| llm
| StrOutputParser()
)
def get_num_tokens(docs):
return llm.get_num_tokens(format_docs(docs))
def collapse(
docs,
config,
token_max=4000,
):
collapse_ct = 1
while get_num_tokens(docs) > token_max:
config["run_name"] = f"Collapse {collapse_ct}"
invoke = partial(collapse_chain.invoke, config=config)
split_docs = split_list_of_docs(docs, get_num_tokens, token_max)
docs = [collapse_docs(_docs, invoke) for _docs in split_docs]
collapse_ct += 1
return docs
# The chain we'll repeatedly apply to collapse subsets of the documents
# into a consolidate document until the total token size of our
# documents is below some max size.
def format_docs(docs):
return "\n\n".join(partial_format_document(doc) for doc in docs)
collapse_chain = (
{"context": format_docs}
| PromptTemplate.from_template("Collapse this content:\n\n{context}")
| llm
| StrOutputParser()
)
def get_num_tokens(docs):
return llm.get_num_tokens(format_docs(docs))
def collapse(
docs,
config,
token_max=4000,
):
collapse_ct = 1
while get_num_tokens(docs) > token_max:
config["run_name"] = f"Collapse {collapse_ct}"
invoke = partial(collapse_chain.invoke, config=config)
split_docs = split_list_of_docs(docs, get_num_tokens, token_max)
docs = [collapse_docs(_docs, invoke) for _docs in split_docs]
collapse_ct += 1
return docs
# The chain we'll use to combine our individual document summaries
# (or summaries over subset of documents if we had to collapse the map results)
# into a final summary.
reduce_chain = (
{"context": format_docs}
| PromptTemplate.from_template("Combine these summaries:\n\n{context}")
| llm
| StrOutputParser()
).with_config(run_name="Reduce")
# The final full chain
map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(
run_name="Map reduce"
)
text = """LangChain is a platform for natural language processing and machine learning.
It provides a series of tools and services that allow users to easily use pre-trained
language models (LLMs) to build and deploy various applications.
"""
docs = [
Document(
page_content=split
)
for split in text.split("\r")
]
print(map_as_doc_chain.map().invoke(docs[0:1]))
# print(map_reduce.invoke(docs[0:1], config={"max_concurrency": 5}))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号