flink知识点
生成项目
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.16.4
wordcount入门教程
- socket进程收集数据
# terminal 运行
nc -lk 9999
- java flink 处理
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
- scala flink 处理
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WindowWordCount {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1)
counts.print()
env.execute("Window Stream WordCount")
}
}
api相关
-
入口类
-
流式
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); -
批式
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH);
-
-
模拟数据
-
单并行度
DataStreamSource<String> source = env.fromElements("a", "b", "c");/** * Creates a data stream from the given non-empty collection. * * <p>Note that this operation will result in a non-parallel data stream source, i.e., a data * stream source with parallelism one. * * @param data The collection of elements to create the data stream from * @param typeInfo The TypeInformation for the produced data stream * @param <OUT> The type of the returned data stream * @return The data stream representing the given collection */ public <OUT> DataStreamSource<OUT> fromCollection( Collection<OUT> data, TypeInformation<OUT> typeInfo) { Preconditions.checkNotNull(data, "Collection must not be null"); // must not have null elements and mixed elements FromElementsFunction.checkCollection(data, typeInfo.getTypeClass()); SourceFunction<OUT> function = new FromElementsFunction<>(data); return addSource(function, "Collection Source", typeInfo, Boundedness.BOUNDED) .setParallelism(1); } -
多并行度
DataStreamSource<LongValue> streamSource = env.fromParallelCollection(new LongValueSequenceIterator(1, 100), TypeInformation.of(LongValue.class));
-
组件
- JobManager:Flink 作业的主控制器,负责协调作业的执行和容错。
- TaskManager:Flink 作业的执行器,负责运行各个算子的子任务。
- Source:Flink 作业的数据源,负责从 Kafka 消费数据。
- Sink:Flink 作业的数据输出,负责将结果写入到外部存储。
- Map:Flink 作业的一个算子,负责将数据转换为键值对的形式。
- KeyedState:Flink 作业的一个状态类型,负责存储每个键对应的值,例如 word count 的结果。
- Checkpoint Coordinator:Flink 作业的检查点协调器,负责触发和管理检查点的执行。
- Checkpoint Barrier:Flink 作业的检查点分界线,用于将数据流划分为不同的段,每个段对应一个检查点的快照。
- State Backend:Flink 作业的状态后端,负责存储检查点的状态数据,例如 RocksDB,HDFS 等。
- Checkpoint Storage:Flink 作业的检查点存储,负责存储检查点的元数据,例如文件系统,数据库等。
checkpoint和barrier
- 触发检查点后,发送检查点屏障来通知各个任务。
- 屏障对齐确保所有任务接收到相同的屏障(flink消费kafka,kafka偏移量保存在flink checkpoint的原因)。
- 任务收集并发送确认信息,表示已处理完毕。
- 检查是否所有任务都发送了确认信息。
- 如果是,触发状态快照,并将任务状态存储起来。
- 如果不是,等待更多确认信息或者处理超时/异常情况。
- 恢复阶段:如果发生故障,使用存储的状态快照来进行恢复,然后继续任务处理。
- 恢复完成后,标记检查点为完成状态。
- 判断是否还有其他待处理的检查点。
- 如果是,返回第一步继续进行下一个检查点。
- 如果不是,结束作业执行。
watermark
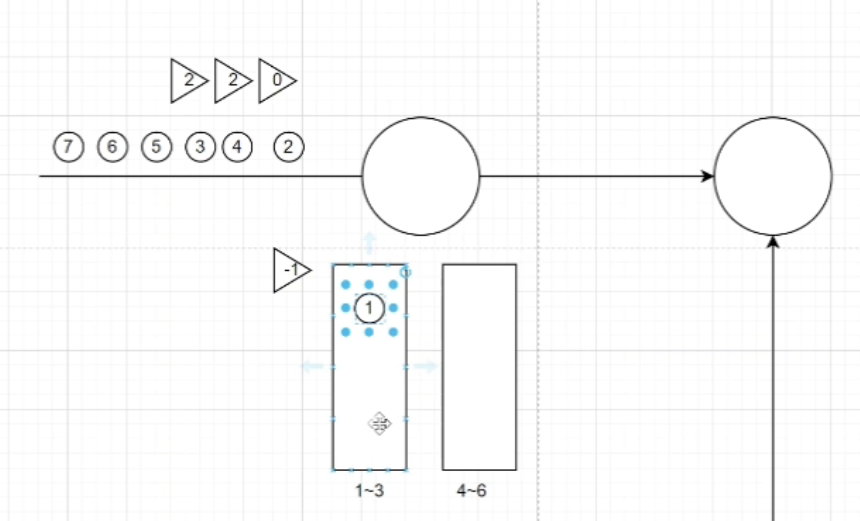
- 容忍时间乱序
- 容忍消息晚到
作为时间推进的依据,一定程度上可以缓解多个并行任务之间或者同一任务的消息晚到以及时间乱序问题。
- 事件时间戳提取:首先,从数据流中的每个事件中提取事件时间戳。事件时间戳是指代表事件发生时间的值。通常,事件时间戳是在事件对象中作为一个字段存储的。
- 延迟容忍度:确定延迟容忍度。延迟容忍度是指在Watermark生成过程中,允许数据到达的最大延迟时间。这个值通常由用户根据业务需求来设定。
- 最大事件时间戳追踪:在每个并行任务中,维护一个当前最大的事件时间戳(Max Event Timestamp)变量。初始值可以设置为负无穷大或者系统启动时间。
- Watermark计算:当每个事件时间戳被提取后,使用它们来更新并行任务中的最大事件时间戳。具体做法是将每个事件的事件时间戳与当前最大事件时间戳进行比较,并将较大的值赋给最大事件时间戳变量。
- Watermark生成:在接下来的生成过程中,通过将当前最大事件时间戳减去延迟容忍度,生成Watermark。(当事件时间计算出来的差值等于watermark时,则之后的但凡算出的差值小于当前watermark的,watermark都记为当前最大事件时间戳减去延迟容忍度的结果,直到计算出来的差值等于窗口右边临界值就触发窗口计算。)
只会变大而不会变小,到一定程度保持不变(等于当前最大事件时间戳减去延迟容忍度的结果),然后等待触发。 - Watermark传递:生成的Watermark将会随着数据流一起传递到下游操作符。每个操作符都会接收到Watermark,并在内部进行处理,例如用于触发基于时间的窗口计算。
- Watermark合并:如果存在多个并行任务,那么各个并行任务会独立生成自己的Watermark。在后续的操作中,这些Watermark会被比较合并,以得出整个作业的全局Watermark。通常会选择较小的值作为全局Watermark,以确保所有并行任务的水位线都被触发。
lookup
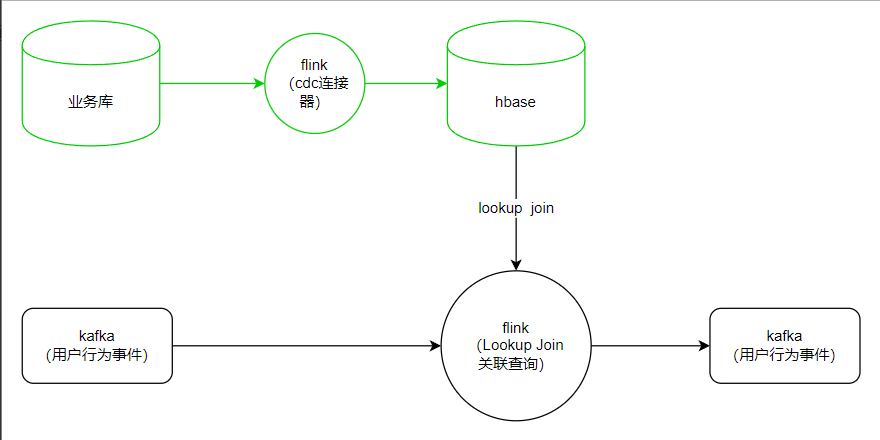
-
使用Lookupjoin解决维度数据流问题
-
问题一:广播流,解决不了数据过大问题(需要checkpoint,STW就会很慢),解决不了更新问题。
-
问题二:实时流,数据不同步问题解决不了。
-
问题三:inner join 解决不了 数据不同步问题。
数据不同步问题:维度数据滞后,就会造成行为数据join不到的情况。
-
-
解决维度数据滞后
- 一般来说维度数据都是新注册然后,再有客户流量进来但是如果关系的维度数据是更新数据 ,就会极大可能有维度数据滞后的问题。
使用lookup来查询第三方数据库(建议使用分布式数据来缓解查询压力好比:hbase) - 可以在api中加入lookup重试机制,多次查询给维度数据一定的延迟来保证join的成功率。
- api较为繁琐,flinksql在1.6之后也支持了重试机制的lookupjoin
- 缓存是否开启根据业务来判断。
- 一般来说维度数据都是新注册然后,再有客户流量进来但是如果关系的维度数据是更新数据 ,就会极大可能有维度数据滞后的问题。
组内分区
// 3. 计算指标,每5分钟内,每种页面类型中,访问人数最多的前10个页面
tenv.executeSql(
" INSERT INTO dashboard_traffic_3 SELECT " +
" window_start " +
" ,window_end " +
" ,page_type " +
" ,page " +
" ,uv_amt " +
" FROM " +
" ( " +
" SELECT " +
" window_start " +
" ,window_end " +
" ,page_type " +
" ,page " +
" ,uv_amt " +
" ,row_number() over(partition by window_start,window_end,page_type order by uv_amt desc) as rn " +
" FROM ( " +
" -- 先在时间窗口中,聚合计算每个页面的访问人数 " +
" SELECT " +
" window_start " +
" ,window_end " +
" ,page_type " +
" ,regexp_extract(properties['url'],'^(.*?\\.html).*?') as page " +
" ,count(distinct user_id) as uv_amt " +
" FROM TABLE( " +
" TUMBLE(TABLE dwd_kafka,DESCRIPTOR(row_time),INTERVAL '5' MINUTE) " +
" ) " +
" GROUP BY " +
" window_start,window_end,page_type,regexp_extract(properties['url'],'^(.*?\\.html).*?') " +
" ) o1 " +
" ) o2 " +
" WHERE rn<=10 "
);
操作点:
- 根据页面类型、页面path分组统计访问人数
- 组内按照页面类型分区按照访问人数排序
- 根据序号取访问人数前十的页面
注意点:
- 使用正则抽取产品路径(去除动态参数)
- 滚动窗口分组统计
- 分区函数中要加上窗口时间
flink 和 Doris
flink接入Doris数据库
flink预处理更强体现在串行化的业务处理能力以及更自由的预处理语境。
使用Doris的优势在哪儿?
因为Doris支持预聚合模型,那么如果一个事件的维度统计跨统计时间窗口的话,在flink里面展示的数据在doris中是可以实现二次聚合的好比最大最小值、替换空等操作,同时最小时间也能保证存留的时间为窗口的开始时间。
时间窗口聚合,有可能会把本该放在一起聚合的行为序列分散到多个窗口各自聚合,这样聚合出来要考虑写入 doris 时的合并可能性(合并的关键设计在于:不管在哪个时间窗口聚合出来的结果的 key 列值保持一致)
DROP TABLE IF EXISTS dws.search_ana_agg;
CREATE TABLE dws.search_ana_agg
(
user_id BIGINT,
search_id VARCHAR(16), -- 搜索标识id
keyword VARCHAR(40), -- 搜索词
split_words VARCHAR(40), -- 分词结果
similar_word VARCHAR(40), -- 近义词
search_time BIGINT MIN, -- 搜索发起时间
return_item_count BIGINT REPLACE_IF_NOT_NULL, -- 返回搜索结果条数
click_item_count BIGINT SUM -- 结果点击次数
)
AGGREGATE KEY(user_id,search_id,keyword,split_words,similar_word)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES
(
"replication_num" = "1"
);
package cn.doitedu.etl;
import cn.doitedu.beans.SearchAggBean;
import cn.doitedu.beans.SearchResultBean;
import cn.doitedu.functions.SimilarWordProcessFunction;
import org.apache.commons.codec.digest.Md5Crypt;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
/**
*
* 搜索事件分析主题olap聚合支撑任务
**/
public class Job5_SearchOlapAggregate {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage("file:/d:/ckpt");
env.setParallelism(4);
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 1. 读行为明细
tenv.executeSql(
" CREATE TABLE dwd_kafka( "
+ " user_id BIGINT, "
+ " username string, "
+ " session_id string, "
+ " event_id string, "
+ " event_time bigint, "
+ " lat double, "
+ " lng double, "
+ " release_channel string, "
+ " device_type string, "
+ " properties map<string,string>, "
+ " register_phone STRING, "
+ " user_status INT, "
+ " register_time TIMESTAMP(3), "
+ " register_gender INT, "
+ " register_birthday DATE, "
+ " register_province STRING, "
+ " register_city STRING, "
+ " register_job STRING, "
+ " register_source_type INT, "
+ " gps_province STRING, "
+ " gps_city STRING, "
+ " gps_region STRING, "
+ " page_type STRING, "
+ " page_service STRING, "
+ " proc_time AS proctime(), "
+ " row_time AS to_timestamp_ltz(event_time,3), "
+ " watermark for row_time as row_time - interval '0' second "
+ " ) WITH ( "
+ " 'connector' = 'kafka', "
+ " 'topic' = 'dwd_events', "
+ " 'properties.bootstrap.servers' = 'doitedu:9092', "
+ " 'properties.group.id' = 'testGroup', "
+ " 'scan.startup.mode' = 'latest-offset', "
+ " 'value.format'='json', "
+ " 'value.json.fail-on-missing-field'='false', "
+ " 'value.fields-include' = 'EXCEPT_KEY') "
);
// 2.过滤出搜索相关事件
tenv.executeSql(
" CREATE TEMPORARY VIEW search_events AS SELECT "+
" user_id, "+
" event_id, "+
" event_time, "+
" properties['keyword'] as keyword, "+
" properties['search_id'] as search_id, "+
" cast(properties['res_cnt'] as bigint) as res_cnt, "+
" properties['item_id'] as item_id, "+
" row_time "+
" "+
" FROM dwd_kafka "+
" WHERE event_id in ('search','search_return','search_click') "
);
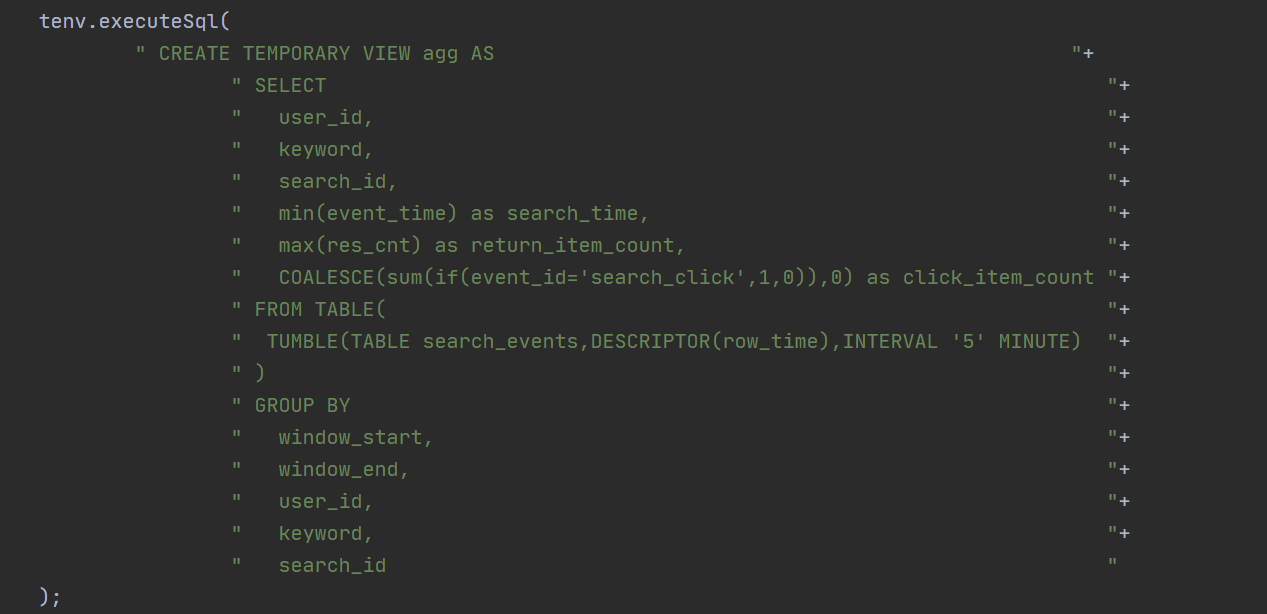
// 3. 聚合(一个搜索生命周期中的事件聚合成一条)
/* 数据规律:
u1,search, s_01,苦咖啡,t1, null, null
u1,search_rt,s_01,苦咖啡,t2, 200 , null
u1,search_ck,s_01,苦咖啡,t3, null, item01
结果: user_id,search_id,搜索词,start_time,返回条数,点击总次数
逻辑: 在时间窗口内,进行分组聚合即可:
group by: user_id,search_id,keyword
* startTime: min(event_time)
* 返回结果数: max(返回结果数)
* 点击次数 : count(if(点击事件))
*/
tenv.executeSql(
" CREATE TEMPORARY VIEW agg AS "+
" SELECT "+
" user_id, "+
" keyword, "+
" search_id, "+
" min(event_time) as search_time, "+
" max(res_cnt) as return_item_count, "+
" COALESCE(sum(if(event_id='search_click',1,0)),0) as click_item_count "+
" FROM TABLE( "+
" TUMBLE(TABLE search_events,DESCRIPTOR(row_time),INTERVAL '5' MINUTE) "+
" ) "+
" GROUP BY "+
" window_start, "+
" window_end, "+
" user_id, "+
" keyword, "+
" search_id "
);
// tenv.executeSql("select * from agg").print();
/*
+----+----------------------+--------------------------------+--------------------------------+----------------------+--------------------------------+-------------+
| op | user_id | keyword | search_id | search_time | res_cnt | click_cnt |
+----+----------------------+--------------------------------+--------------------------------+----------------------+--------------------------------+-------------+
| +I | 3 | usb 移动固态 | sc01 | 1670596213000 | 276 | 2 |
| +I | 5 | 速溶苦咖啡 | sc03 | 1670596215000 | 186 | 3 |
| +I | 3 | 固态移动硬盘 | sc02 | 1670596215000 | 276 | 0 |
*/
// 4. 查询近义词和分词(http请求)
Table aggTable = tenv.from("agg");
DataStream<SearchAggBean> dataStream = tenv.toDataStream(aggTable, SearchAggBean.class);
//dataStream.print();
SingleOutputStreamOperator<SearchResultBean> resultStream = dataStream.keyBy(bean -> Md5Crypt.md5Crypt(bean.getKeyword().getBytes()).substring(0, 5))
.process(new SimilarWordProcessFunction());
// 5. 写入doris
// 流转表
tenv.createTemporaryView("res",resultStream);
// 创建doris的连接器表
tenv.executeSql(
"CREATE TABLE sink_doris( "+
" user_id BIGINT, "+
" search_id STRING, "+
" keyword STRING, "+
" split_words STRING, "+
" similar_word STRING, "+
" search_time BIGINT, "+
" return_item_count BIGINT, "+
" click_item_count BIGINT "+
") WITH ( "+
" 'connector' = 'doris', "+
" 'fenodes' = 'doitedu:8030', "+
" 'table.identifier' = 'dws.search_ana_agg', "+
" 'username' = 'root', "+
" 'password' = 'root', "+
" 'sink.label-prefix' = 'doris_label35' "+
") "
);
tenv.executeSql("INSERT INTO sink_doris " +
"SELECT " +
"user_id,search_id,keyword,split_words,similar_word,search_time,return_item_count,click_item_count " +
"FROM res");
env.execute();
}
}
public class SimilarWordProcessFunction extends KeyedProcessFunction<String, SearchAggBean, SearchResultBean> {
CloseableHttpClient client;
MapState<String, String> state;
HttpPost post;
SearchResultBean searchResultBean;
@Override
public void open(Configuration parameters) throws Exception {
// 构造 http请求客户端
client = HttpClients.createDefault();
// 构造一个post请求对象
post = new HttpPost("http://doitedu:8081/api/post/simwords");
// 请求头
post.addHeader("Content-type", "application/json; charset=utf-8");
post.addHeader("Accept", "application/json");
// 申请一个状态(MapState),用于存储已经查询过的 : 搜索词 -> 分词,近义词
MapStateDescriptor<String, String> descriptor = new MapStateDescriptor<>("st", String.class, String.class);
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.of(30, TimeUnit.MINUTES)).setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite).build();
descriptor.enableTimeToLive(ttlConfig);
state = getRuntimeContext().getMapState(descriptor);
// 构造一个用于输出结果的可重用的bean
searchResultBean = new SearchResultBean();
}
@Override
public void processElement(SearchAggBean searchAggBean, KeyedProcessFunction<String, SearchAggBean, SearchResultBean>.Context context, Collector<SearchResultBean> collector) throws Exception {
// 取出搜索词,并封装成接口所要求的json结构
String searchWord = searchAggBean.getKeyword();
String words;
String similarWord;
String stateResult = state.get(searchWord);
if (stateResult != null) {
String[] split = stateResult.split("\001");
words = split[0];
similarWord = split[1];
} else {
HashMap<String, String> data = new HashMap<>();
data.put("origin", searchWord);
String jsonString = JSON.toJSONString(data);
// 请求体
post.setEntity(new StringEntity(jsonString, StandardCharsets.UTF_8));
// 发出请求,得到响应
CloseableHttpResponse response = client.execute(post);
// 从response中提取响应体(服务器返回的json)
HttpEntity entity = response.getEntity();
String responseJson = EntityUtils.toString(entity);
// 从响应中提取我们要的结果数据(近义词 分词)
JSONObject jsonObject = JSON.parseObject(responseJson);
words = jsonObject.getString("words");
similarWord = jsonObject.getString("similarWord");
// 将请求到的结果放入状态缓存起来
state.put(searchWord, words + "\001" + similarWord);
}
// 输出结果
searchResultBean.set(searchAggBean.getUser_id(),
searchAggBean.getKeyword(),
words,
similarWord,
searchAggBean.getSearch_id(),
searchAggBean.getSearch_time(),
searchAggBean.getReturn_item_count(),
searchAggBean.getClick_item_count()
);
collector.collect(searchResultBean);
}
}
谓词下推
根据物理计划中的数据源和计算节点的布局,在执行计划中将谓词下推到数据源节点,以尽早地过滤掉不符合条件的数据。
在 Flink SQL 中,谓词下推是优化查询的一种技术。它通过将谓词(即查询条件)尽可能地推送到数据源进行处理,以减少数据的读取和传输,从而提高查询性能。
当执行一个查询时,通常会包含多个谓词,例如 WHERE 子句中的过滤条件。谓词下推的目标是将这些谓词尽早地应用于数据源,减少不必要的数据读取和处理。
具体来说,谓词下推的过程可以分为以下几个步骤:
- 解析查询:解析 SQL 查询语句,获取其中的谓词信息。
- 逻辑优化:对查询进行逻辑优化,包括谓词重写、谓词合并等操作,以便更好地推测谓词。
- 物理优化:根据查询的物理计划选择最佳的执行策略。
- 谓词下推:根据物理计划中的数据源和计算节点的布局,在执行计划中将谓词下推到数据源节点,以尽早地过滤掉不符合条件的数据。
- 执行计划:基于谓词下推后的执行计划执行查询,并返回结果。
谓词下推的好处是减少了数据传输和处理的开销,提高了查询性能。通过将谓词下推到数据源节点,在数据源上进行更多的过滤操作,可以减少需要传输和处理的数据量,从而加快查询速度。
需要注意的是,谓词下推的效果取决于具体的查询和数据源的布局,不同场景下可能会有不同的优化效果。因此,在使用 Flink SQL 进行查询时,合理地利用谓词下推技术可以提高查询性能。
状态一致性
Flink两次提交保证了在分布式系统中,所有参与者节点在进行事务提交时保持一致性,避免数据的丢失或重复。具体来说,Flink两次提交的过程如下:
-
Source端
Flink从外部数据源读取数据时,需要保证消息的严格一次消费,以及数据源的可重放性。例如,如果数据源是Kafka,Flink可以将Kafka的消费偏移量作为状态保存到检查点中,并在恢复时重新设置偏移量,从而避免数据的丢失或重复。
-
计算层
Flink利用检查点机制,定期将分布式的状态快照保存到持久化的存储中,以便在发生故障时恢复状态。Flink使用了一种轻量级的快照算法,叫做异步屏障快照(asynchronous barrier snapshotting),它可以在不阻塞数据流的情况下,保证状态的全局一致性。 -
Sink端
Flink将处理完的数据写入到外部存储系统时,需要保证数据的一致性和完整性。Flink使用了两阶段提交协议(two-phase commit protocol)。预提交阶段可以保证与Flink的检查点机制协调,避免数据的不一致或重复。此外,外部存储系统也需要支持事务或幂等操作,以便在发生故障时回滚或重放数据。- 第一次提交(预提交阶段):当Flink的JobManager向数据流注入一个barrier时,表示开始一个新的检查点(checkpoint)。每个参与者节点(operator)在接收到barrier时,会将自己的状态保存到检查点中,并将barrier向下游传递。同时,如果参与者节点有外部状态,比如要写入外部存储系统,那么它也会开始一个新的事务,并将数据写入临时文件或缓存中。当所有参与者节点都完成检查点的保存,JobManager就会收到所有节点的反馈消息,表示预提交成功。
- 第二次提交(提交阶段):当JobManager收到所有参与者节点的反馈消息后,它会向所有节点发送检查点完成的通知。每个参与者节点在收到通知后,会正式提交自己的事务,并将数据从临时文件或缓存中移动到实际的目标位置。这样,就保证了数据的一致性和完整性。
举例kafka:
在预提交阶段,Flink 会将消费到的数据写入到 checkpoint 中。如果 checkpoint 成功,则表示预提交成功。如果 checkpoint 失败,则表示预提交失败,需要进行回滚。
在正式提交阶段,Flink 会将 checkpoint 中的数据写入到 offset 主题中,并向 Kafka 发送一个正式提交的请求。如果正式提交成功,则表示数据已经被成功提交。如果正式提交失败,则需要进行重试。
- Flink Job从Kafka Source消费数据,并将数据发送给Kafka Sink进行处理和输出。
- Kafka Sink将输出数据写入Offset Topic,用于记录输出的位置和状态。
- Checkpoint Coordinator定期触发检查点,要求Kafka Source和Kafka Sink保存各自的状态到Checkpoint Storage,例如Kafka Source的消费偏移量,Kafka Sink的输出文件句柄等。
- Kafka Source和Kafka Sink在保存状态后,向Checkpoint Coordinator确认检查点。
- Checkpoint Coordinator在收到所有确认后,将检查点的元数据保存到Checkpoint Storage。
- Checkpoint Coordinator根据检查点的成功或失败,通知Kafka Source和Kafka Sink进行预提交或回滚操作。
- Kafka Source和Kafka Sink在预提交成功后,将各自的状态提交到Offset Topic,例如Kafka Source的消费偏移量,Kafka Sink的输出文件句柄等。
- Kafka Source和Kafka Sink在预提交失败后,将各自的状态回滚到上一个检查点的状态,例如Kafka Source的消费偏移量,Kafka Sink的输出文件句柄等。
在 Flink 中,barrier 是用来同步并行 Task 的一种机制。它可以确保所有 Task 在到达 barrier 之前,都完成了特定的操作。
barrier 由 TaskManager 协调器来管理。TaskManager 协调器会为每个 barrier 分配一个唯一的 id。当 Task 到达 barrier 时,会向 TaskManager 协调器发送一个请求。TaskManager 协调器会检查所有 Task 是否都到达了 barrier。如果所有 Task 都到达了 barrier,则会释放 barrier。
具体的工作原理如下:
- Task 到达 barrier 时,会向 TaskManager 协调器发送一个请求。
- TaskManager 协调器会检查所有 Task 是否都到达了 barrier。
- 如果所有 Task 都到达了 barrier,则会释放 barrier。
- 当 barrier 被释放后,所有 Task 都可以继续执行。
在 Flink 中,TaskManager 协调器的实现是通过 JobManager 来完成的。JobManager 会维护一个 barrier 列表。当 Task 到达 barrier 时,会向 JobManager 发送一个请求。JobManager 会检查 barrier 列表,如果 barrier 存在,则会更新 barrier 的状态。
内存模型
| 内存类别 | 作用 |
|---|---|
| 框架内存 | 存储Flink框架本身的数据结构和对象 |
| 任务内存 | 用户自定义的数据结构和对象 |
| 托管内存 | 对象、排序、哈希表、缓存等计算过程中的临时数据 |
| 网络内存 | 网络缓冲区 |
| Flink的内存模型 | Spark的内存模型 |
|---|---|
| 基于Off-Heap内存管理,直接分配和操作系统内存,不受Java堆大小的限制 | 基于On-Heap内存管理,使用Java虚拟机管理的内存区域,受到Java堆大小的限制 |
| 使用自主的内存管理,将数据序列化到预分配的内存段(MemorySegment)中,提高数据的存储密度和处理效率,减少垃圾回收的开销 | 使用Java对象来存储数据,需要依赖于垃圾回收器(GC)来释放无用的对象占用的空间 |
| 将Flink总内存划分为框架内存、任务内存、托管内存和网络内存四个部分,分别用于存储Flink框架本身的数据结构和对象、用户自定义的数据结构和对象、排序、哈希表、缓存等计算过程中的临时数据和网络缓冲区 | 将Flink总内存划分为执行内存和存储内存两个部分,分别用于存储Shuffle、Join、Sort、Aggregation等计算过程中的临时数据和Spark的缓存数据,例如RDD的缓存、广播变量等 |
| 将TaskManager的内存分配为固定数量的Task Slots,每个Task Slot可以运行一条由多个并行Task组成的流水线,Task Slot的数量决定了TaskManager的并行度 | 将Executor的内存分配为动态数量的Task,每个Task可以运行一个Stage中的一个分区,Task的数量决定了Executor的并行度 |
实时数仓kappa
分布式系统资源预估
CPU和内存
- 对于一些基于磁盘的框架,如Hadoop和MapReduce,可以采用较低的内存和CPU的比率,如1:2或1:4,以提高CPU的利用率和磁盘的吞吐量。
- 对于一些基于内存的框架,如Spark和Flink,可以采用较高的内存和CPU的比率,如1:4或1:8,以提高内存的容量和带宽,减少磁盘和网络的开销。
- 对于一些复杂的机器学习算法,如深度学习,可以采用较高的内存和CPU的核心数,如1:8或1:16,以支持大规模的数据和模型的并行处理,同时可以考虑使用GPU等加速器来提升计算性能。
硬盘
-
为了保证数据高可用至少有一个副本。
数据大小*2 -
配置压缩,节省硬盘资源、加快网络同步。
数据大小*2*压缩比
kafka集群各种压缩性价比比较
| 压缩格式 | 压缩比 | 综合性价比 | 分析过程 |
|---|---|---|---|
| Gzip | 2.743 | 较低 | Gzip的压缩比最高,但是压缩速度最慢,CPU使用率最高,这意味着它会消耗更多的时间和资源来进行压缩和解压缩,从而降低了性能和效率。因此,Gzip的综合性价比较低,只适合对存储空间和网络带宽要求极高,对性能和效率要求较低的场景。 |
| Snappy | 2.073 | 较高 | Snappy的压缩比中等,压缩速度较快,CPU使用率适中,这意味着它可以在压缩和解压缩的过程中节省一定的时间和资源,同时也可以节省一定的存储空间和网络带宽。因此,Snappy的综合性价比较高,适合对性能和效率要求较高,对存储空间和网络带宽要求较高的场景。 |
| Lz4 | 2.101 | 较低 | Lz4的压缩比最低,压缩速度最快,CPU使用率最低,这意味着它可以在压缩和解压缩的过程中消耗最少的时间和资源,但是也会占用最多的存储空间和网络带宽。因此,Lz4的综合性价比较低,只适合对压缩速度和CPU消耗要求极高,对存储空间和网络带宽要求较低的场景。 |
| Zstd | 2.887 | 较高 | Zstd的压缩比中等,压缩速度较快,CPU使用率适中,这意味着它可以在压缩过程中做了一些优化和折衷,以提高压缩速度和降低CPU消耗,从而提高综合性价比。另外,Zstd还可以通过参数调整压缩比和压缩速度的权衡,以适应不同的场景和需求。因此,Zstd的综合性价比较高,适合对压缩效果和压缩性能要求较高,对存储空间和网络带宽要求较高的场景。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号