
Spark优化
意识篇
-
类型转换
优化前:val extractFields: Seq[Row] => Seq[(String, Int)] = { (rows: Seq[Row]) => { var fields = Seq[(String, Int)]() rows.map(row => { fields = fields :+ (row.getString(2), row.getInt(4)) }) fields } }优化后:
val extractFields: Seq[Row] => Seq[(String, Int)] = { (rows: Seq[Row]) => rows.map(row => (row.getString(2), row.getInt(4))).toSeq }过程式编程变为函数式编程
关注主要业务逻辑,最终一次性完成类型转换。
原理篇
RDD
RDD,全称 Resilient Distributed Datasets,翻译过来就是弹性分布式数据集。本质上,它是对于数据模型的抽象,用于囊括所有内存中和磁盘中的分布式数据实体。
- 横向属性
partitions 和 partitioner 锚定数据分片实体,并且规定了数据分片在分布式集群中如何分布; - 纵向属性
dependencies 和 compute 用于在纵深方向构建 DAG,通过提供重构 RDD的容错能力保障内存计算的稳定性。
Map & MapPartitions
-
map
对每一条数据都会作用一次函数,出来什么数据结构,取决于输入。 -
MapPartitions
对输入源RDD的每个分区的迭代器作用一次函数,返回迭代器。 -
MapPartitionsWithIndex
同时提供分区号和迭代器。
-
补充
类似的还有foreach和foreachPatition 两个 Executor端 Action算子,前者是每条数据调用一次函数,后者是每个分区调用一次。这样持久化第三数据库或者其他的一些需要初始化的动作最好都使用后者来操作。
缓存
-
原则
只有需要频繁访问的数据集才有必要 cache。 -
原理
所谓内存计算,不仅仅是指数据可以缓存在内存中,更重要的是让我们明白了,通过计算的融合来大幅提升数据在内存中的转换效率,进而从整体上提升应用的执行性能。由于计算的融合只发生在 Stages 内部,而 Shuffle 是切割 Stages 的边界,因此一旦发生Shuffle,内存计算的代码融合就会中断。所以开发者更应该主动地想办法尽量避免Shuffle,让应用代码中尽可能多的部分融合为一个函数,从而提升计算效率。
依赖类型 描述 shuffle 窄依赖 每个父RDD分区最多只被子RDD的一个分区所使用 否 宽依赖 父RDD的一个分区可能被子RDD的多个分区所使用 是
调度系统
调度系统的工作流程:
- 将 DAG 拆分为不同的运行阶段 Stages;
- 创建分布式任务 Tasks 和任务组 TaskSet;
Taskset的个人取决于Stage中FinalRDD的分区个数决定。 - 获取集群内可用的硬件资源情况;
- 按照调度规则决定优先调度哪些任务 / 组;
- 依序将分布式任务分发到执行器 Executor。
- DAGScheduler将DAG划分不同的Stages,同时基于这些Stage创建不同任务和任务组;
- SchedulerBackend根据资源调度器的不同用WorkOffer封装资源数据(Executor Id,主机地址,CPU核数、可供使用内存等。);
- Spark Session -> Standalone
- Yarn
- Mesos
- k8s
- 然后TaskScheduler来根据调度规则来编排任务和组的执行顺序;
- stage之间
- FIFO
- FAIR
- stage内部
本地性级别有 4 种:Process local < Node local< Rack local < Any。从左到右分别是进程本地性、节点本地性、机架本地性和跨机架本地性。从左到右,计算任务访问所需数据的效率越来越差。
- stage之间
- TaskScheduler询问SchedulerBackend将分布式任务分发到执行器Executor,并监控任务的执行。
Tips
-
Stage、Task 、TaskSet、 Executor 的关系
- 一个Stage一个Taskset
- 一个Task一个Executor
-
Process Local & Node Local
如果Task需要的数据在Task线程执行所属的Executor进程的内存中,就属于Process Local,
而需要的数据在本台机器的其他Executor进程的内存中就属于Node Local。
Executor由机器资源分配所以给的是进程资源。Task 由 DAGScheduler 生成,并由 每个Executor的Task线程池负责创建和销毁的整个生命周期。
数据本地化
用来配置 Spark 在启动 executor 过程中等待资源本地化的最大时长。
根据本地性级别可以配置本地化的超时时间:
-
全局设置
spark.local.wait 默认为3s -
个性化配置
spark.local.wait.级别=xxs
eg:-
spark.local.wait.process=60s
-
spark.local.wait.node=30s
-
堆外内存
设置rdd持久化存储级别时可以设置为堆外,那么就可以将运算内存和存储内存很好的分割开来。
这样更好地利用JVM内部的存储内存匀给运行内存用来做聚合操作。
内存占用
内存分为:
-
Reserved Memory
存储 Spark 内部对象 -
User Memory
存储用户自定义的数据结构 -
Execution Memory
分布式任务执行
如 Shuffle、Sort 和 Aggregate 等操作; -
Storage Memory
容纳 RDD 缓存和广播变量如果对方的内存空间有空闲,双方就都可以抢占;
对于 RDD 缓存任务抢占的执行内存,当执行任务有内存需要时,RDD 缓存任务必须立即归还抢占的内存,涉及的 RDD 缓存数据要么落盘、要么清除;
对于分布式计算任务抢占的 Storage Memory 内存空间,即便 RDD 缓存任务有收回内存的需要,也要等到任务执行完毕才能释放。
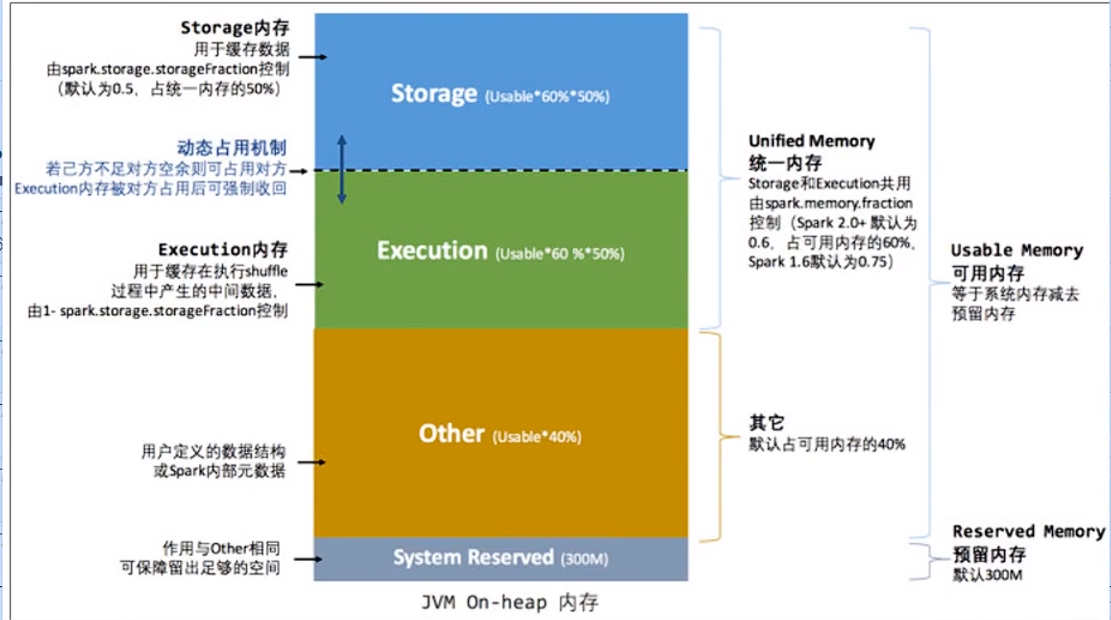

-
堆内内存以及堆外内存
-
内存划分
堆内内存上面四个都有;堆外内存只有后面两个。
-
怎么选择
重点考察数据模式。如果数据模式比较扁平,而且定长字段较多,应该更多地使用堆外内存。相反地,如果数据模式比较复杂,应该更多地利用堆内内存定长字段是指数据的长度是固定的,不会随着数据的变化而变化。例如,整数、浮点数、布尔值、日期等都是定长字段。这些数据可以很容易地序列化为二进制数据,因为它们的二进制表示是唯一的,而且可以用固定的字节数来存储。例如,一个 32 位的整数可以用 4 个字节来表示,一个 64 位的浮点数可以用 8 个字节来表示,一个布尔值可以用 1 个字节来表示,一个日期可以用 8 个字节来表示,等等。这样,序列化和反序列化的过程就很简单,只需要按照固定的规则来读写字节即可。如果数据的长度是不固定的,或者有多种可能的表示方式,那么序列化为二进制数据就比较复杂。例如,字符串、数组、列表、字典、结构体等都是不定长字段。这些数据的二进制表示不是唯一的,而且需要用额外的信息来标识长度、类型、分隔符等。例如,一个字符串可以用 UTF-8、UTF-16、GBK 等不同的编码方式来表示,一个数组可以用不同的元素类型和长度来表示,一个字典可以用不同的键值对的顺序和数量来表示,等等。这样,序列化和反序列化的过程就需要进行更多的计算和判断,增加了开销。
-
flink & spark 内存模型区别
| Flink的内存模型 | Spark的内存模型 |
|---|---|
| 基于Off-Heap内存管理,直接分配和操作系统内存,不受Java堆大小的限制 | 基于On-Heap内存管理,使用Java虚拟机管理的内存区域,受到Java堆大小的限制 |
| 使用自主的内存管理,将数据序列化到预分配的内存段(MemorySegment)中,提高数据的存储密度和处理效率,减少垃圾回收的开销 | 使用Java对象来存储数据,需要依赖于垃圾回收器(GC)来释放无用的对象占用的空间 |
| 将Flink总内存划分为框架内存、任务内存、托管内存和网络内存四个部分,分别用于存储Flink框架本身的数据结构和对象、用户自定义的数据结构和对象、排序、哈希表、缓存等计算过程中的临时数据和网络缓冲区 | 将Spark总内存划分为执行内存和存储内存两个部分,分别用于存储Shuffle、Join、Sort、Aggregation等计算过程中的临时数据和Spark的缓存数据,例如RDD的缓存、广播变量等 |
| 将TaskManager的内存分配为固定数量的Task Slots,每个Task Slot可以运行一条由多个并行Task组成的流水线,Task Slot的数量决定了TaskManager的并行度 | 将Executor的内存分配为动态数量的Task,每个Task可以运行一个Stage中的一个分区,Task的数量决定了Executor的并行度 |
哪些Join不能用 Broadcast Join
- 什么是broadcast join
使用BitTorrent协议将右表广播到各个Executor进程,task线程之间共享右表数据。
广播变量比闭包引用map更有效,就是因为种子下载协议,节省网络资源,多个Executor都可以下载做种,彼此之间又可以作为服务器和客户端去下载自己没有的数据。
在Spark中,强制开启broadcast join,可以通过在Spark SQL中使用broadcast提示来实现。broadcast join也称为map join,会在执行大表和小表的连接操作时,把小表的数据复制到所有的节点上去,以减少数据的传输量。
当你知道有一个表特别小,并且想要强制Spark执行一个broadcast join时,可以使用如下的写法:
SELECT /*+ BROADCAST(small_table) */ *
FROM big_table JOIN small_table
ON big_table.id = small_table.id;
在上面的查询中,通过/*+ BROADCAST(small_table) */提示来告知Spark优化器应该进行broadcast join。
除了使用SQL注释提示外,还可以在Spark SQL的配置中设置spark.sql.autoBroadcastJoinThreshold参数,来指定一个阈值,小于这个阈值大小的表会自动被用作broadcast join。默认情况下,这个参数设置为10MB。
spark.sql.autoBroadcastJoinThreshold=20971520
将这个值设置为你希望的大小。如果设置为-1,则会禁用自动broadcast join。
- 以下的情况broadcast join失效
- full outer join
需要找到两张表相互join不到的数据列举出来,广播谁都不好使,所以不能用,这种情况只能用Sort Merge Join。 - 两张表都大。
内存放不下所以不能使,可以用Shuffle Hash Join 或者 Sort Merge Join。 - 只能广播右表,注意语句写法。
- full outer join
补充:闭包引用的对象只会存在Driver端,同时复制一份到task中,所以闭包引用的对象在task中被修改,是不会作用到Driver端的对象的。
shuffle hash join & sort merge join
理解这两区别的前提前提是:理解为什么shuffle之前要sort,sort是为了保证数据的有序性可以把(同一份数据或者多份数据源的)相同key的数据排到一起,完成预先join,而hash join则完成的前提是有一张表可以做为广播表。
- shuffle hash join 和 sort merge join 都是适用于两个大表的等值连接,不要求参与连接的键是否可排序。
- shuffle hash join 的优点是不需要对数据进行排序,节省了排序的开销,但是需要将一张表的数据完全加载到内存中,使用哈希表进行连接,可能会导致内存溢出。
- sort merge join 的优点是不需要将数据完全加载到内存中,只需要对数据进行排序,然后像拉链一样进行连接,避免了内存溢出的风险,但是需要额外的排序的开销。
- shuffle hash join 和 sort merge join 的选择主要取决于数据的大小和内存的资源。一般来说,如果一张表的大小小于 spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions (默认值200)的值,而且小表的大小的三倍小于等于大表的大小,那么可以选择 shuffle hash join。如果两张表都很大,或者小表的大小的三倍大于大表的大小,那么可以选择 sort merge join。
- 另外,还可以通过设置 spark.sql.join.preferSortMergeJoin 参数来控制是否优先选择 sort merge join。默认值为 true,表示优先选择 sort merge join。如果设置为 false,表示优先选择 shuffle hash join.
理解Sort Merge
给出一个用python实现MapReduce理解sort merge
-
数据
-
key.txt
13512354789 15812344739 16621554739 18921354729 -
keyvalue.txt
13512354789,张三 15812344739,李四 16621554739,王五
-
-
代码
## map.py
import sys
def read_file(filename):
with open(filename, encoding='utf-8') as file:
for line in file:
yield line.rstrip('\n')
file_name_one=sys.argv[1]
for line in read_file(file_name_one):
file_prefix=file_name_one.split(".")[0]
print("\t".join([line,file_prefix]))
file_name_two=sys.argv[2]
for line in read_file(file_name_two):
file_prefix=file_name_two.split(".")[0]
print("\t".join([line,file_prefix]))
#red.py 方案一 纯输出
#!/usr/bin/env python
import sys
def main(separator = '\t'):
key = None
for data in sys.stdin:
detail = data.strip().split(separator)
if(detail[1].startswith("0")):
key = detail[0]
elif(key == detail[0] and detail[1].startswith("1_")):
print detail[1].split("_",1)[1]
if __name__ == '__main__':
main()
#red.py 方案二 该方案可以做一些集合操作。
import sys
key_match = None
value_match = {}
values = []
for line in sys.stdin:
key,tag = line.strip().split("\t")
if key_match:
# 匹配到key,则把value放入values和key_value
if(key_match in key):
# 匹配到多条value的场景,需要先从key_value中拿出然后再放回去
if key in value_match:
values = value_match.get(key_match)
values.append(key)
value_match[key_match] = values
# 匹配到第一条value的场景,不需要从key_value里面拿
else:
values.append(key)
value_match[key_match] = values
else:
# 如果参照key和拿出来key不一致说明来新key了,
# 同时也把上一个key的数据打印输出不占内存
key_match = key
if value_match:
for key in value_match.keys():
print(key,"\t".join(value_match[key]))
values.clear()
value_match.clear()
else:
# 第一个key来活了.
if(tag=="key"):
key_match = key
python map.py key.txt keyvalue.txt |sort |python reduce.py
## 中间文件
13512354789 key
13512354789,张三 keyvalue
15812344739 key
15812344739,李四 keyvalue
16621554739 key
16621554739,王五 keyvalue
18921354729 key
## 结果文件
13512354789 13512354789,张三
15812344739 15812344739,李四
16621554739 16621554739,王五
数据倾斜
-
原理
假设你有以下的数据分布,在没有考虑随机列
rand的情况下:col1 ---- Key1 Key1 Key1 Key2 Key2 Key3在Spark中,如果你按照
col1进行groupBy操作,由于Key1的出现次数远多于其他键,它们很可能会被分配到同一个分区中,从而导致某个分区的数据量过大,其他分区的数据量较小,这就是数据倾斜。
现在,如果在每个键值对中加入一个随机列rand,则大致如下:col1 rand ---- ---- Key1 0.5 Key1 0.2 Key1 0.9 Key2 0.3 Key2 0.6 Key3 0.1当执行
groupBy("col1").agg(...)操作时,即使逻辑上Key1的记录应该聚合在一起,由于它们在rand列上的值不同,它们会被随机散布到不同的分区上进行处理。这样,Key1的记录就不会全部落在同一个分区中,而是被均匀分配到其他分区。这样做之后,虽然rand对最终的聚合结果没有任何影响,因为最终我们会删去这个列,但在shuffle阶段因为rand的作用,导致了包含Key1的数据被平衡到了多个分区,大大减少了数据倾斜的影响。这也就提高了处理效率,特别是在分布式计算环境中。 -
取样
在处理包含倾斜列
col1的数据倾斜问题时,确实可能会存在对整个数据集进行groupBy操作时的数据倾斜。但是,这一步是为了查明哪些键是倾斜的。一旦我们确定了这些键,就可以有针对性地对其采样,而不是对整个数据集采样。
如果我们一开始就对数据进行随机采样,那么可能会错过那些倾斜的键,因为这些键在数据集中可能有很大的比重,但在小比例的随机样本中却不一定会出现。这样就不能解决数据倾斜的问题。
实际上为了避免在寻找倾斜键的过程中出现进一步的数据倾斜,我们可以采用一些策略来减少groupBy操作可能带来的倾斜。例如,我们可以在执行groupBy前对数据进行预处理,比如使用一个随机列进行散列,以达到一个更平衡的分布。
具体实现这一策略时,可以这样操作:import org.apache.spark.sql.functions.rand val dfWithRandom = df.withColumn("rand", rand()) val skewedKeys = dfWithRandom.groupBy("col1") .agg(count(lit(1)).alias("count"), first("rand").alias("rand")) .orderBy(desc("count")) .drop("rand") .limit(10)上面的代码片段通过添加一个随机数列
rand,在计算每个col1值计数的同时,将数据分散到不同的分区。这样,在聚合操作中,原本可能堆积在一个分区中的倾斜键会被分散到不同的分区,减少groupBy操作的数据倾斜问题。
请记住,这些策略和参数设置需要根据具体的应用环境和数据特性进行调整。TIPS:groupby算子不会进行预聚合,用的缓冲区为ExternalSorter,而reducebykey和aggregatebykey用的是ExternalAppendOnlyMap。
shuffle write 调优
默认的缓冲区初始大小为5m,每满一次申请一次5m(spark.shuffle.spill.initialMemoryThreshold 不可更改),
private[spark] val SHUFFLE_SPILL_INITIAL_MEM_THRESHOLD =
ConfigBuilder("spark.shuffle.spill.initialMemoryThreshold")
.internal() //不可更改
.doc("Initial threshold for the size of a collection before we start tracking its " +
"memory usage.")
.version("1.1.1")
.bytesConf(ByteUnit.BYTE)
.createWithDefault(5 * 1024 * 1024)
当申请不到时截止(上限取决于空闲的Execution内存),
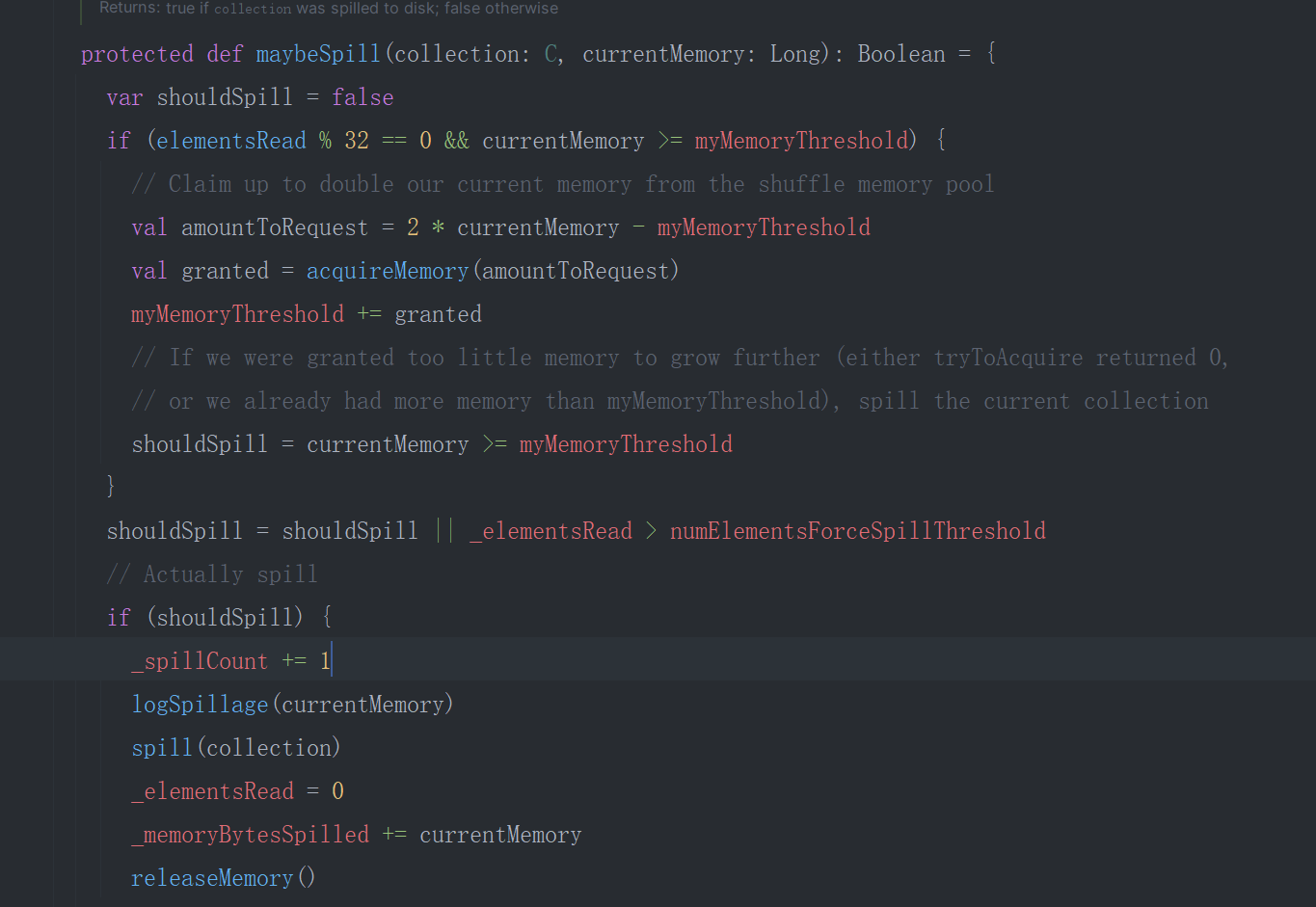
溢出到磁盘的取决于
-
fileBufferSize:spark.shuffle.file.buffer 可以更改。
private[spark] val SHUFFLE_FILE_BUFFER_SIZE = ConfigBuilder("spark.shuffle.file.buffer") .doc("Size of the in-memory buffer for each shuffle file output stream, in KiB unless " + "otherwise specified. These buffers reduce the number of disk seeks and system calls " + "made in creating intermediate shuffle files.") .version("1.4.0") .bytesConf(ByteUnit.KiB) .checkValue(v => v > 0 && v <= ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH / 1024, s"The file buffer size must be positive and less than or equal to" + s" ${ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH / 1024}.") .createWithDefaultString("32k") -
serializerBatchSize:spark.shuffle.spill.batchSize 不可更改
private[spark] val SHUFFLE_SPILL_BATCH_SIZE = ConfigBuilder("spark.shuffle.spill.batchSize") .internal() //不可更改 .doc("Size of object batches when reading/writing from serializers.") .version("0.9.0") .longConf .createWithDefault(10000)
private[this] def spillMemoryIteratorToDisk(inMemoryIterator: WritablePartitionedIterator[K, C])
: SpilledFile = {
// Because these files may be read during shuffle, their compression must be controlled by
// spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
// createTempShuffleBlock here; see SPARK-3426 for more context.
val (blockId, file) = diskBlockManager.createTempShuffleBlock()
// These variables are reset after each flush
var objectsWritten: Long = 0
val spillMetrics: ShuffleWriteMetrics = new ShuffleWriteMetrics
//初始化Writer,类似于outputstrem需要的buffer
val writer: DiskBlockObjectWriter =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)
// List of batch sizes (bytes) in the order they are written to disk
val batchSizes = new ArrayBuffer[Long]
// How many elements we have in each partition
val elementsPerPartition = new Array[Long](numPartitions)
// Flush the disk writer's contents to disk, and update relevant variables.
// The writer is committed at the end of this process.
// 刷写磁盘动作
def flush(): Unit = {
val segment = writer.commitAndGet()
batchSizes += segment.length
_diskBytesSpilled += segment.length
objectsWritten = 0
}
var success = false
try {
while (inMemoryIterator.hasNext) {
val partitionId = inMemoryIterator.nextPartition()
require(partitionId >= 0 && partitionId < numPartitions,
s"partition Id: ${partitionId} should be in the range [0, ${numPartitions})")
inMemoryIterator.writeNext(writer)
elementsPerPartition(partitionId) += 1
objectsWritten += 1
//达到特定batchsize才出发刷盘
if (objectsWritten == serializerBatchSize) {
flush()
}
}
if (objectsWritten > 0) {
flush()
writer.close()
} else {
writer.revertPartialWritesAndClose()
}
success = true
} finally {
if (!success) {
// This code path only happens if an exception was thrown above before we set success;
// close our stuff and let the exception be thrown further
writer.closeAndDelete()
}
}
SpilledFile(file, blockId, batchSizes.toArray, elementsPerPartition)
}
总结:从上文的代码可得要想加快shuffle write写盘的速度,只有spark.shuffle.file.buffer这个一个参数,默认为32k。
shuffle read 调优
- read buffer:spark.reducer.maxSizeInFlight 默认 48m
private[spark] val REDUCER_MAX_SIZE_IN_FLIGHT = ConfigBuilder("spark.reducer.maxSizeInFlight")
.doc("Maximum size of map outputs to fetch simultaneously from each reduce task, " +
"in MiB unless otherwise specified. Since each output requires us to create a " +
"buffer to receive it, this represents a fixed memory overhead per reduce task, " +
"so keep it small unless you have a large amount of memory")
.version("1.4.0")
.bytesConf(ByteUnit.MiB)
.createWithDefaultString("48m")
checkpoint
spark的checkpoint用于新生成一个job将需要多次利用的RDD存储到文件系统中(本地/HDFS/S3)。
分区器
-
数据源
无Shuffle无需重新分区,一个block或者range一个分区。
-
GroupByKey、ReduceBykey
HashPartitioner -
SortByKey(全局排序)
RangePartitionerdef sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) : RDD[(K, V)] = self.withScope { val part = new RangePartitioner(numPartitions, self, ascending) new ShuffledRDD[K, V, V](self, part) .setKeyOrdering(if (ascending) ordering else ordering.reverse) }
SparkSql解析过程
-
原始sql
-
SqlParse
解析sql语句生成逻辑执行计划树。 -
Analyzer
分析语句绑定元数据,生成带有元数据的逻辑执行计划树。 -
Optimizer
通过action算子触发讲过诸如以下的优化生成优化后的逻辑执行计划书。
-
谓词下推
将谓词过滤过程下推到数据源,尽可能得减少计算过程的数据传输。 -
列裁剪
优化需要的字段,使得数据源只提供需要的字段参与计算。 -
常量替换
-
常量累加
i = 10 ; where age = i + 1; // 替换后 where age = 12;
-
-
SparkPlanner
经过计算器解析生成各种Exec,形成最终的物理执行计划书。
-
execute
生成RDD,以及通过反射和实例化生成带有stage的全阶段RDD算子代码,依照DAG图通过迭代器完成计算。
UDF和UDAF区别
-
UDF
纯数据行处理函数
-
UDAF
包括了如下操作:
- 数据集合初始化
- 局部聚合操作
- 全局聚合操作
- 集合序列化
- 集合反序列化
-
将Int装入Bitmap然后存入第三方catalog重复使用好比hive
import org.apache.commons.io.output.ByteArrayOutputStream import org.apache.spark.sql.{Encoder, Encoders} import org.apache.spark.sql.expressions.Aggregator import org.roaringbitmap.RoaringBitmap import java.io.{ByteArrayInputStream, DataInputStream, DataOutputStream} /** * 创建UDAF函数用于,UV场景,需要多维度求UV的场景 * 好比 省市区都要求UV。 */ object BitMapUDAF extends Aggregator[Int,Array[Byte],Array[Byte]] { //集合初始化 override def zero: Array[Byte] = { val bitmap = RoaringBitmap.bitmapOfRange(0, 10) serBitMap(bitmap) } //局部聚合操作 override def reduce(b: Array[Byte], a: Int): Array[Byte] = { val bitmap: RoaringBitmap = deSerBitMap(b) bitmap.add(a) serBitMap(bitmap) } //全局最终聚合操作 override def merge(b1: Array[Byte], b2: Array[Byte]): Array[Byte] = { val bitmapb1: RoaringBitmap = deSerBitMap(b1) val bitmapb2: RoaringBitmap = deSerBitMap(b2) bitmapb1.or(bitmapb2) bitmapb1 serBitMap(bitmapb1) } //无操作,直接返回即可。 override def finish(reduction: Array[Byte]): Array[Byte] = { reduction } //反序列化器 override def bufferEncoder: Encoder[Array[Byte]] = Encoders.BINARY //序列化器 override def outputEncoder: Encoder[Array[Byte]] = Encoders.BINARY //序列化 Bitmap2Array[Byte] def serBitMap(bitmap: RoaringBitmap): Array[Byte] = { val bitmap = RoaringBitmap.bitmapOfRange(0, 10) val outputStream = new ByteArrayOutputStream() val dataOutputStream = new DataOutputStream(outputStream) bitmap.serialize(dataOutputStream) outputStream.toByteArray } //反序列化 Array[Byte]2Bitmap def deSerBitMap( byteArray:Array[Byte]):RoaringBitmap = { val bitmap = RoaringBitmap.bitmapOfRange(0, 10) val inputStream = new ByteArrayInputStream(byteArray) val dataInputStream = new DataInputStream(inputStream) bitmap.deserialize(dataInputStream) bitmap } } -
二次聚合用于高纬度聚合
import org.apache.commons.io.output.ByteArrayOutputStream import org.apache.spark.sql.{Encoder, Encoders} import org.apache.spark.sql.expressions.Aggregator import org.roaringbitmap.RoaringBitmap import java.io.{ByteArrayInputStream, DataInputStream, DataOutputStream} /** * 对bitmap做二次聚合使用 */ object MergeBitMapUDAF extends Aggregator[Array[Byte],Array[Byte],Array[Byte]] { //集合初始化 override def zero: Array[Byte] = { val bitmap = RoaringBitmap.bitmapOfRange(0, 10) serBitMap(bitmap) } //局部聚合操作 override def reduce(a: Array[Byte], b: Array[Byte]): Array[Byte] = { val bitmapA: RoaringBitmap = deSerBitMap(a) val bitmapB: RoaringBitmap = deSerBitMap(b) bitmapA.or(bitmapB) serBitMap(bitmapA) } //全局最终聚合操作 override def merge(b1: Array[Byte], b2: Array[Byte]): Array[Byte] = { reduce(b1,b2) } //无操作,直接返回即可。 override def finish(reduction: Array[Byte]): Array[Byte] = { reduction } //反序列化器 override def bufferEncoder: Encoder[Array[Byte]] = Encoders.BINARY //序列化器 override def outputEncoder: Encoder[Array[Byte]] = Encoders.BINARY //序列化 Bitmap2Array[Byte] def serBitMap(bitmap: RoaringBitmap): Array[Byte] = { val bitmap = RoaringBitmap.bitmapOfRange(0, 10) val outputStream = new ByteArrayOutputStream() val dataOutputStream = new DataOutputStream(outputStream) bitmap.serialize(dataOutputStream) outputStream.toByteArray } //反序列化 Array[Byte]2Bitmap def deSerBitMap( byteArray:Array[Byte]):RoaringBitmap = { val bitmap = RoaringBitmap.bitmapOfRange(0, 10) val inputStream = new ByteArrayInputStream(byteArray) val dataInputStream = new DataInputStream(inputStream) bitmap.deserialize(dataInputStream) bitmap } }
-
数据行的操作不要在Driver端执行
服务端才是分布式,从服务端拉数据过来不仅有网络消耗,而且硬生生把分布式操作改为本地操作,失去了大数据分布式分而治之的思想,Driver端资源更有限,会处理更慢。
优化前:
def createInstance(factDF: DataFrame, startDate: String, endDate: String): Dat val instanceDF = factDF .filter(col("eventDate") > lit(startDate) && col("eventDate") <= lit(endDate)) .groupBy("dim1", "dim2", "dim3", "event_date") .agg(sum("value") as "sum_value") instanceDF } pairDF.collect.foreach{ case (startDate: String, endDate: String) => val instance = createInstance(factDF, startDate, endDate) val outPath = s"${rootPath}/endDate=${endDate}/startDate=${startDate}" instance.write.parquet(outPath) }这种写法会把数据拉回到Driver端一句一句操作,会很慢。
优化后:val instances = factDF .join(pairDF, factDF("eventDate") > pairDF("startDate") && factDF("eventDate")<= pairDF("endDate") .groupBy("dim1", "dim2", "dim3", "eventDate", "startDate", "endDate") .agg(sum("value") as "sum_value") instances.write.partitionBy("endDate", "startDate").parquet(rootPath)这种只会分区落盘时拉取数据一次。
Tips
-
Spark 延迟计算的 Actions 算子主要有两类:
-
一类是将分布式计算结果直接落盘的操作,
如 DataFrame 的 write、RDD 的 saveAsTextFile 等; -
另一类是将分布式结果收集到 Driver 端的操作,
如 first、take、collect。
-
-
优化后的Join为Nested Loop Join(不等式Join)虽然性能最差,但也只会扫描一次全量数据。
坐享其成
钨丝计划
-
堆外内存
Tungsten 利用 Java Unsafe API 开辟堆外(Off HeapMemory)内存来管理对象。
堆外内存有两个天然的优势:
一是对于内存占用的估算更精确;二来不需要像 JVM Heap 那样反复执行垃圾回收。
-
二进制格式
自定义紧促的二进制格式数据,天然地避免了 Java 对象序列化与反序列化引入的计算开销,提高CPU命中率。 -
全阶段代码生成
不仅可以减少虚函数调用和降低内存访问频率,还能提升 CPU cache 命中率,做到大幅压缩 CPU idle 时间,从而提升 CPU 利用率。
AQE
-
动态切分Shuffle分区:在缺乏统计信息的情况下,Shuffle分区的数量往往难以恰当地选择。AQE可以根据运行时的统计信息,动态地合并小的分区,避免生成大量小文件和大量小任务,从而提升性能并减少资源消耗;shuffle后可能有的分区数据很少,自动分区合并可以把小数据量的数据分区(符合分组逻辑)进行合并。
-
动态调整任务并发度:在某些情况下,有些任务失败了很多次才完成,而这个过程中其他任务都已经完成。AQE可以动态地增加并发度,把剩下的任务更快地完成。
-
动态优化JOIN策略:对于不确定大小的JOIN操作,用户一般会设置为SortMergeJoin,但当实际表扫描过后发现数据偏小,则有可能转为更快的BroadcastHashJoin。AQE可以在运行时生成新的物理计划,从而改变JOIN的策略;join过程中如果过滤后某个数据集满足Broadcast Join,自动切换为Broadcast Join。
-
动态优化倾斜Join:当Join操作的key倾斜,即某一键出现的次数过多时,会导致这部分数据只能在一个task中处理,形成数据倾斜。AQE能够在运行时检测出数据倾斜并自动处理,缓解数据倾斜的问题;自己加盐和去盐。
SET spark.sql.adaptive.enabled=true;
SET spark.sql.adaptive.coalescePartitions.enabled=true;
SET spark.sql.adaptive.skewJoin.enabled=true;
spark.sql.adaptive.enabled:设置为true,表示开启AQE功能。
spark.sql.adaptive.coalescePartitions.enabled:设置为true,表示开启分区合并优化,这可以减少小分区的数量,避免任务过多和调度开销。
spark.sql.adaptive.skewJoin.enabled:设置为true,表示开启倾斜连接优化,这可以将倾斜的分区拆分成多个子分区,平衡负载和加速连接。
spark.sql.adaptive.skewJoin.skewedPartitionFactor:倾斜因子 默认为5
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes:倾斜比较依据阈值 默认256M
//倍数因子乘以中位数分区大小大于比较依据阈值,则认为该程序存在数据倾斜的。并且自动分区合并优先级高于数据倾斜判断。
spark.sql.adaptive.advisoryPartitionSizeInBytes 倾斜分区打散后的分区上限大小 肯定要小于上边的计算结果
能省则省,能拖则拖
- 尽量把能节省数据扫描量和数据处理量的操作往前推;
- 尽力消灭掉 Shuffle,省去数据落盘与分发的开销;
- 如果不能干掉 Shuffle,尽可能地把涉及 Shuffle 的操作拖到最后去执行。
- 工具类的实例化放在循坏外部
CBO
在Apache Spark 3.X中,CBO代表代价基优化(Cost-Based Optimization)。这是一种高级的查询优化技术,通过估计不同查询计划的成本来选择最有效的执行路径。
原理:
基于代价模型进行选择最佳执行计划。Spark在执行SQL查询时,会生成多个逻辑执行计划。在启用CBO时,每个逻辑计划都会根据统计信息计算成本,例如行数和列的数据分布。然后,Spark比较这些执行计划的成本并选择最佳的执行计划。
要充分利用CBO,需要对数据表进行统计信息收集,这通常通过执行ANALYZE TABLE命令完成。具体来说,可以使用:
ANALYZE TABLE table_name COMPUTE STATISTICS FOR ALL COLUMNS;
这样Spark就能获取数据分布的细节信息,从而做出更智能的执行计划选择。因为CBO依赖精确的统计信息来进行决策,所以定期更新统计信息非常重要,以确保查询优化保持最优状态。
CBO 默认情况下是不启用的。要启用 CBO,需要设置一些配置参数。具体地,你需要在 Spark 的配置文件 spark-defaults.conf (或者在运行会话中设置)中设置 spark.sql.cbo.enabled 为 true。同样,为了使 CBO 更有效,建议还要设置 spark.sql.cbo.joinReorder.enabled 为 true 以便于启用连接重排序功能。
下面是开启 CBO 相关的配置命令:
spark.sql.cbo.enabled=true
spark.sql.cbo.joinReorder.enabled=true
对查询的影响可以在多个方面体现出来:
- 过滤选择 - 当开启CBO时,Spark会使用数据的统计信息来优化过滤操作。比如,如果有两个过滤条件,CBO可以识别哪个过滤条件会排除更多的数据,然后先应用那个条件,以减少后续的数据处理量。
- 连接顺序 - 在有多个表参与连接时,CBO可以优化处理的顺序。基于数据的统计信息,它可以选择先连接那些行数较少的表,从而减少中间处理数据的大小。
- 连接策略 - Spark支持不同的连接策略,如广播连接和排序合并连接。CBO可以根据表的大小和分布来选择最合适的连接方法,从而提高查询效率。
- 聚合操作 - 对于聚合操作,CBO可以选择使用更有效的数据处理方式。比如,它可以决定是使用哈希聚合还是排序聚合,取决于行数和数据的分布情况。
- Join/Aggregate的优化 - 当开启CBO后,Spark还可以决定是否对某些聚合进行map-side pre-aggregation,这在处理大型数据集时可以显着提高速度。
举个具体的例子,我们可以考虑一个查询,它需要从两个不同大小的表中进行Join操作,并对结果进行聚合。在没有开启CBO的情况下,Spark可能会选择了一个排序合并连接策略,然后进行全局聚合。而在开启CBO后,它可能会识别到其中一个表的大小非常小,适合进行广播,然后选择广播连接策略,并且在map端进行部分预聚合,从而节省了在shuffle阶段传输数据的成本,并减少了聚合操作的处理时间。
开启CBO的具体影响会随着不同的查询和数据集的统计信息而变化。为了更清楚地看到CBO开启前后的区别,可以运行explain命令来查看Spark SQL查询的物理计划,并且在执行相同查询的时候使用Spark的Web UI或其他监控工具来比较执行时间和资源使用情况。
SMB JOIN
Spark环境中A和B两张表尚未通过桶(bucketing)排序好,而你需要进行排序合并连接(Sort-Merge Bucket Join, 简称SMB Join),那么你将需要先确保这两个表在连接键上是排序的,并对这两个表有相同数目的分区,同时要求同样的分桶(bucketing)来进一步优化大表的join操作。在Spark中,桶就是按照某列值的哈希结果将数据分散存储到多个文件中,这可以大大减少join时的数据倾斜问题,优化shuffle过程。这里有一个加入分桶过程的示例:
首先,你需要决定分桶的列和桶的数量,然后对A和B两张表采用bucketBy方法来应用桶配置。例如:
val bucketColumn = "col1"
val numBuckets = 50
val dfA = tableA.write.format("parquet").bucketBy(numBuckets, bucketColumn).sortBy(bucketColumn).saveAsTable("bucketed_A")
val dfB = tableB.write.format("parquet").bucketBy(numBuckets, bucketColumn).sortBy(bucketColumn).saveAsTable("bucketed_B")
在上面的示例中,两张表都根据列col1被分成了50个桶,并且也在该列上进行了排序。这将在数据存储时创建好分桶和排序,使得后续的操作(如join)可以更高效。
接下来,当你进行join操作时,Spark会识别出这两张表都已进行分桶和排序,它将采用SMB Join:
SELECT *
FROM bucketed_A
JOIN bucketed_B
ON bucketed_A.col1 = bucketed_B.col1
采用SMB Join时,由于数据已经是预分桶和排序的,Spark可以跳过大量的shuffle操作,从而提高join操作的性能,尤其是对于大表的join操作。
值得注意的是,为了桶化能够有效果,对于join、groupBy等操作,选择合适的桶的数量是很重要的。通常需要根据数据量和集群的配置来确定合适的桶的数量。设得太少可能达不到优化的效果,设得太多可能会使得每个桶中的数据量过小,导致处理过程中的开销相对增大。
开启 Kryo 序列化
Kryo 序列化是 Apache Spark 中使用的一种序列化机制,旨在提供比 Java 自带的序列化机制更高效的性能。在 Spark 中,序列化被用于两个主要的场景:
- Shuffle 数据传输:在 shuffle 过程中,数据需要从一个节点传输到另一个节点,这时数据需要被序列化成字节流。
- 任务序列化:在把任务从 driver 发送到 executor 的过程中,任务需要被序列化。
默认情况下,Spark 使用的是 Java 序列化,但它提供了 Kryo 序列化作为一个可选的优化,因为 Kryo 是更快且更高效的。使用 Kryo 序列化通常可以提升程序的性能,特别是在网络传输大量数据或者进行大规模内存运算的时候。
要在 Spark 中启用 Kryo 序列化,需要进行下面的设置:
在 spark-conf/spark-defaults.conf:
spark.serializer org.apache.spark.serializer.KryoSerializer
在代码中:
val conf = new SparkConf().setAppName(appName).setMaster(master)
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
Kryo 也支持注册自定义类以进一步提升性能,因为已注册的类在序列化时可以使用简短的 ID,而非完整的类名来标识类,从而减少了序列化后的数据大小:
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
适当配置使用 Kryo 序列化对于在 Spark 应用中实现性能优化是非常有帮助的。
shuffle
机制演进
| Shuffle机制 | 版本 | 原理 | 优点 | 缺点 |
|---|---|---|---|---|
| Hash Shuffle | Spark 0.8及以前 | 每个map task为每个reduce task生成一个文件,根据key的哈希值将数据分配到不同的文件中,不进行排序 | 简单,不需要排序 | 会产生大量的小文件,占用文件描述符,增加磁盘IO和内存开销,而且在reduce task时需要使用HashMap进行合并操作,容易引发OOM |
| Hash Shuffle + File Consolidation | Spark 0.8.1 | 一个Executor上所有的map task生成的分区文件只有一份, | 减少了文件数目,提高了数据拉取的效率 | 仍然会开启大量的Writer Handler,消耗内存,而且如果分区数很大,仍然会产生很多文件 |
| Sort Shuffle | Spark 1.1 | 每个map task将所有数据写入一个文件,并按照partition id和key进行排序,同时生成一个索引文件记录每个partition的大小和偏移量,在reduce task时,使用ExternalAppendOnlyMap进行合并操作,可以将数据溢写到磁盘,避免OOM | 解决了Hash Shuffle的所有弊端,减少了文件数目,提高了数据拉取的效率,避免了OOM | 需要进行排序,增加了计算开销 |
| Tungsten-Sort Shuffle | Spark 1.4 | 使用堆外内存和二进制格式存储数据,直接在序列化的二进制数据上进行排序,减少了内存占用和GC开销,避免了序列化和反序列化的开销,提高了排序的性能 | 进一步优化了Sort Shuffle,节省了内存和CPU,提高了性能 | 需要满足一些条件,比如不能有聚合操作,分区数不能超过一定的限制,否则会退化为Sort Shuffle |
中间文件
- 分类
- 一类是后缀为data 的数据文件,存储的内容是 Map 阶段生产的待分发数据;
- 另一类是后缀为 index 的索引文件,它记录的是数据文件中不同分区的偏移地址。这里的分区是指 Reduce 阶段的分区。
- 溢出
PartitionedPairBuffer中间内存(本质就一数组)空间有限,多余的task数据会经历排序、溢出、归并到文件中,最终生成数据文件和索引文件。
排序依据:key的hash值与reduce个数(缺省为200)取模之后得到的parttionid以及key的ASCII字典顺序。
ReduceByKey & GroupByKey
-
GroupByKey
中规中矩的分组聚合shuffle。 -
ReduceByKey (满足交换律和结合律)
利用PartitionedAppendOnlyMap在map阶段实现预聚合,类似于MapReduce中的combiner class.
在计数、求和、极值计算这些聚合操作中都可以使用来大大减少IO的消耗。
求平均和分位数这些则不适合。//假设rdd是一个(key, value)的RDD,使用ReduceByKey求平均值的巧妙用法。 val avg = rdd.mapValues(v => (v, 1)) //将每个value转换成(value, 1) .reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)) //对(value, 1)进行累加,得到(value的总和, key的个数) .mapValues(x => x._1 / x._2) //对(value的总和, key的个数)进行除法,得到平均值Tips:
- MapValues
MapValues和map的区别是,map可以对键值对进行任意的转换,而MapValues只能对值进行转换,键保持不变。MapValues的优点是,它可以避免重新分配键的开销,提高效率。
//假设rdd是一个(key, value)的RDD val rdd = sc.parallelize(Array((1, 2), (2, 4), (3, 6), (4, 8))) val rdd2 = rdd.mapValues(v => v + 1) //对每个value加一 rdd2.collect() //输出结果为Array((1, 3), (2, 5), (3, 7), (4, 9))- ReduceBykey是不是一定会有shuffle?
不一定,如果上游RDD的分区器和分区个数和ReduceBykey使用的一样,则不会发生shuffle。
/** * Return a copy of the RDD partitioned using the specified partitioner. */ def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope { if (keyClass.isArray && partitioner.isInstanceOf[HashPartitioner]) { throw SparkCoreErrors.hashPartitionerCannotPartitionArrayKeyError() } if (self.partitioner == Some(partitioner)) { self } else { new ShuffledRDD[K, V, V](self, partitioner) } }val valueRepartition = valueOneRDD.partitionBy(new HashPartitioner(2)) val reduceRDD = valueRepartition.reduceByKey(_+_)好比如上的操作reduceByKey就不会产生shuffle。
SortByKey
全局排序
验证如下:
val sparkConf = new SparkConf()
.setAppName("Simple Application")
.setMaster("local[1]")
val sc = new SparkContext(sparkConf)
val seqRDD = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3), ("a", 4), ("b", 1)), 2)
val sortByKeyRDD = seqRDD.sortByKey()
sortByKeyRDD.saveAsTextFile("data/sortbykey/output")
sc.stop()
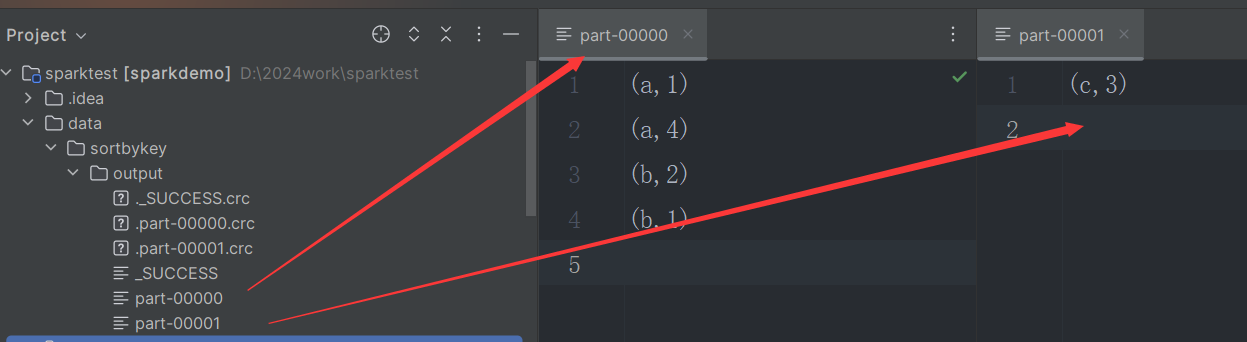
分类
-
BypassMergeSort
private[spark] object SortShuffleWriter { def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = { // We cannot bypass sorting if we need to do map-side aggregation. // 不能有map端聚合 if (dep.mapSideCombine) { false } else { //reduce端的分区数小于200 val bypassMergeThreshold: Int = conf.get(config.SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD) dep.partitioner.numPartitions <= bypassMergeThreshold } } } -
SerializedShuffle
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = { val shufId = dependency.shuffleId val numPartitions = dependency.partitioner.numPartitions //开启序列化 比如 kryo if (!dependency.serializer.supportsRelocationOfSerializedObjects) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " + s"${dependency.serializer.getClass.getName}, does not support object relocation") false //不能有map端聚合 } else if (dependency.mapSideCombine) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because we need to do " + s"map-side aggregation") false //看了下这个参数很大,一般达不到。16777216 } else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " + s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions") false } else { log.debug(s"Can use serialized shuffle for shuffle $shufId") true } } -
BaseSortShuffle
默认sortshuffle
性能优化速查手册
调试技巧
wins spark 本地调试
-
安装idea scala插件、下载scalasdk包,在idea项目添加全局依赖包,重启调试scala helloword。
-
根据报错定位到缺少winutils工具完成本地调试spark
Exception in thread "main" java.lang.RuntimeException: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:736) -
从该[git地址]( cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows (github.com) )下载离自己使用版本大小版本最近的依赖包。
-
配置HADOOP_HOME路径为该地址到系统环境变量。
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
-
复制hadoop.dll文件到C:\Windows\System32。
-
重启idea。
-
调试spark写数据到本地文件(此步骤才会用到HADOOP_HOME)
Any类型转换
// 定义一个包含Any类型的变量
val anyValue: Any = 42.5
// 尝试将Any类型转换为Double类型
val doubleValue: Double = anyValue.asInstanceOf[Double]
// 打印结果
println(s"Original Value: $anyValue")
println(s"Converted to Double: $doubleValue")
累加器
用于全局累计统计某些指标:错误解析的数据条数、某个算子总共处理了多久时间。
val sparkConf = new SparkConf()
.setAppName("Accumulator Application")
.setMaster("local[1]")
val sc = new SparkContext(sparkConf)
val jsonRDD: RDD[String] = sc.textFile("data/accum/a.json")
//初始化累加器
val errorParse: LongAccumulator = sc.longAccumulator("error_parse")
jsonRDD.map(line => {
try {
val person: JSONObject = JSONUtil.parseObj(line)
val id: Integer = person.getInt("id")
val name: String = person.getStr("name")
val age: Integer = person.getInt("age")
(id,name,age)
} catch {
case e:Exception =>{
//累加错误
errorParse.add(1)
()
}
}
}).count()
println(errorParse.value)
sc.stop()// 创建一个 Long 类型的累加器
//入门
val accum = sc.longAccumulator("My Acc")
// 创建一个 RDD
val rdd = sc.makeRDD(1 to 9)
// 对 RDD 中的每个元素进行累加操作
rdd.foreach(x => accum.add(x))
// 打印累加器的值
println(accum.value)
// 45
数据字典UDF
将特征值量化,数字化
val spark = SparkSession.builder().appName("app").getOrCreate()
import spark.implicits._
// 创建UDF函数
val udfFunc = udf((inputMap: Map[String, Int], inputKey: String) => {
inputMap.getOrElse(inputKey, 999).toDouble // 使用Map,如果找不到对应的Key,则返回默认值999,然后将结果转换为Double类型
})
// 创建你的Map
val myMap1 = Map("item1" -> 10, "item2" -> 20)
val myMap2 = Map("itemA" -> 30, "itemB" -> 40)
// 创建一个包含Key的DataFrame
val data = Seq(("item1", "itemA"),("item2", "itemB")).toDF("key1", "key2")
// 使用UDF
val result = data.withColumn("value1", udfFunc(lit(myMap1), $"key1"))
.withColumn("value2", udfFunc(lit(myMap2), $"key2"))
result.show()
Tips
lit()函数在 Spark 中用于创建字面值(Literal),即常数值。这些值可以是各种类型,包括String,Integer,Map等。 当你将 Map 直接作为一个参数传递给 UDF 时,Spark 会尝试将 Map 解析为一个 Column 对象。但是,由于 Map 实际上并不对应于 DataFrame 中的任何一个 Column,因此这会导致错误。因此,我们需要使用lit()函数将 Map 包装为一个字面值 Column,这样 Spark 才能正确地理解它。 同时,你也可以使用typedLit()函数。与lit()不同,typedLit()可以处理更复杂的数据类型,如List或Map。这款函数允许你将List,Seq,Map等复杂类型作为字面值,而lit()只能处理基本类型,如Int,String等。 总的来说,以这种方式使用lit()或typedLit()函数,可以确保我们的自定义 Map 被 Spark 正确理解,并能够成功传递给 UDF 。
日志级别
spark 3.3.0 使用的log4j2,使用mvn调试项目时,在src/main/resources的log4j2.properties配置如下内容:
log4j.rootCategory=WARN, console
在代码中设置不起作用
//不启作用是因为该类属于log4j
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
启动命令
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
并行度
假设有一个Spark作业,需要从HDFS上读取一个10GB的文本文件,然后对每一行进行分词,统计每个词出现的次数,并按照词频降序排序,最后将结果保存到HDFS上。假设集群的总CPU核数为100,HDFS的block大小为128MB,那么可以按照以下步骤估算并行度:
- 从HDFS上读取文件时,RDD的分区数为文件大小除以block大小,即10GB / 128MB = 80,所以这个stage的task数为80,这个并行度已经接近集群的总CPU核数,不需要调整。
- 对每一行进行分词时,不会改变RDD的分区数,所以这个stage的task数仍然为80,这个并行度也不需要调整。
- 统计每个词出现的次数时,会使用reduceByKey算子,这个算子会触发shuffle,产生新的RDD,其分区数由spark.default.parallelism参数决定,假设这个参数设置为200,那么这个stage的task数为200,这个并行度是集群总CPU核数的2倍,符合一般的规则,不需要调整,如果没有设置则为上游RDD分区数(有分区器和无分区器的共同决定)最大的并行度决定。
- 按照词频降序排序时,会使用sortBy算子,这个算子也会触发shuffle,产生新的RDD,其分区数仍然由spark.default.parallelism参数决定,所以这个stage的task数仍然为200,这个并行度也不需要调整。
- 将结果保存到HDFS上时,RDD的分区数不会改变,所以这个stage的task数仍然为200,这个并行度也不需要调整。
综上所述,这个Spark作业的并行度估算依据是RDD的分区数,集群的资源,spark.default.parallelism参数等,根据这些依据,可以估算出每个stage的task数,从而确定合理的并行度。
Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如资源控制器给Executor的分配的CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.sql.shuffle.partitions这个参数的默认设置是200。这个参数用于设置Spark SQL中的shuffle类算子(如join,groupBy等)产生的新RDD的分区。这个参数可以根据数据量和集群资源进行调整,以提高Spark SQL的性能。
执行计划
spark explain cost一起使用 优化Sql
假设你有一个表,叫做orders,存储了每个订单的信息,包括订单号,客户号,日期,金额等,你想要查询每个客户的总订单金额。你可以写这样的Sql语句:
select customer_id, sum(amount) as total_amount from orders group by customer_id
你可以使用explain cost模式来查看执行计划,例如:
spark.sql("select customer_id, sum(amount) as total_amount from orders group by customer_id").explain("cost")
你可能会看到类似这样的输出:
== Optimized Logical Plan == Aggregate [customer_id#0], [customer_id#0, sum(amount#1) AS total_amount#2] +- Relation[order_id#0,customer_id#1,date#2,amount#3] parquet Statistics(sizeInBytes=4.0 EiB, hints=none)
从这个输出中,你可以看到以下几点:
- Spark优化器对逻辑执行计划进行了一些优化,例如:
- 在Aggregate中,对customer_id进行了分组,对amount进行了求和,得到了total_amount,这是一个新的列。
- 在Relation中,读取了parquet格式的表orders,这是一个物理数据源。
- Spark优化器还给出了逻辑执行计划的统计信息,例如:
- sizeInBytes表示查询的输出结果的大小,这里是4.0 EiB,表示很大,可能需要更多的内存和磁盘空间。
- hints表示查询的提示信息,这里是none,表示没有使用任何提示,你可以使用hint函数来给出一些提示,例如指定分区的数量、缓存的策略等,来影响物理执行计划的生成。
根据这些信息,你可以对你的查询进行一些优化,例如:
- 如果你知道orders表的数据分布,你可以使用hint函数来指定一个更合适的分区数量,例如coalesce或repartition,来平衡数据的分布和并行度。
- 如果你知道orders表的数据特征,你可以使用索引或分区来加速查询,例如根据customer_id或date来创建索引或分区,来减少数据的扫描和过滤。
- 如果你知道orders表的数据不会经常变化,你可以使用hint函数来指定一个缓存的策略,例如cache或persist,来将数据缓存在内存或磁盘中,来提高查询的速度。
你可以使用hint函数的语法来指定一个或多个提示,例如:
select /*+ COALESCE(10), CACHE */ customer_id, sum(amount) as total_amount from orders group by customer_id
这个例子中,我们使用了两个hint,分别是COALESCE(10)和CACHE。COALESCE(10)是一种分区提示,它告诉Spark优化器将数据的分区数量减少到10个,而不是默认的200个,从而减少数据的移动和网络开销。CACHE是一种缓存提示,它告诉Spark优化器将数据缓存在内存中,而不是每次都从磁盘中读取,从而提高查询的速度。
你可以再次使用explain cost模式来查看执行计划的变化,以及统计信息的改善,
spark.sql("select /*+ COALESCE(10), CACHE */ customer_id, sum(amount) as total_amount from orders group by customer_id").explain("cost")
你可能会看到类似这样的输出:
== Optimized Logical Plan == Aggregate [customer_id#0], [customer_id#0, sum(amount#1) AS total_amount#2] +- InMemoryRelation [order_id#0, customer_id#1, date#2, amount#3], StorageLevel(disk, memory, deserialized, 1 replicas) +- Relation[order_id#0,customer_id#1,date#2,amount#3] parquet Statistics(sizeInBytes=40.0 GiB, hints=[COALESCE(10), CACHE])
从这个输出中,你可以看到以下几点:
- Spark优化器对逻辑执行计划进行了一些优化,例如:
- 在Aggregate中,对customer_id进行了分组,对amount进行了求和,得到了total_amount,这是一个新的列。
- 在InMemoryRelation中,将数据缓存在内存中,这是一个逻辑数据源。
- 在Relation中,读取了parquet格式的表orders,这是一个物理数据源。
- Spark优化器还给出了逻辑执行计划的统计信息,例如:
- sizeInBytes表示查询的输出结果的大小,这里是40.0 GiB,表示很小,因为数据的分区数量减少了,而且数据缓存在内存中。
- hints表示查询的提示信息,这里是[COALESCE(10), CACHE],表示使用了两个提示,分别是COALESCE(10)和CACHE。
这些优化方法都可以提高查询性能,可以通过再次使用explain cost模式来查看执行计划的变化,以及统计信息的改善。
Scala补充
偏函数
只对输入参数的某些值进行处理,而对其他值则不处理或抛出异常。偏函数的类型是PartialFunction[A, B],其中A是输入参数的类型,B是返回值的类型。
val greaterThan20: PartialFunction[Any, Int] = {
case i: Int if i > 20 => i
}
List(1, 45, 10, "blah", true, 25) collect greaterThan20 // List(45, 25)
柯里化函数
将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数为参数的函数。
def add(x:Int)(y:Int) = x + y
实例
LAG函数
测试数据:
user_id login_date
1001 2021-11-05
1001 2021-11-06
1001 2021-11-08
1001 2021-11-10
1001 2021-11-15
1001 2021-11-16
1001 2021-11-18
1001 2021-11-19
1002 2021-11-05
1002 2021-11-07
1002 2021-11-09
1002 2021-11-11
1002 2021-11-13
1002 2021-11-16
需求:求每个用户最大的连续登陆天数,断一天还算连续登录(两个日期的差小于或等于 2 )。
比如 11-06 号登录,最近的下一次登录是 11-08 号,两个日期的差等于 2 天,因此这两个日期之间的天数都算作连续天数,一共 3 天。
最终数据
user_id max_login_days
1001 6
1002 9
用sparksql实现
-
spark sql
-- 使用窗口函数和分组函数计算每个用户最大的连续登陆天数 -- 参考资料:[Spark SQL窗口函数]、[Spark SQL日期函数] SELECT user_id, MAX(login_days) AS max_login_days FROM ( SELECT user_id, login_date, SUM(new_group) OVER (PARTITION BY user_id ORDER BY login_date) AS group_id, COUNT(*) OVER (PARTITION BY user_id, group_id) AS login_days FROM ( SELECT user_id, login_date, CASE WHEN DATEDIFF(login_date, LAG(login_date) OVER (PARTITION BY user_id ORDER BY login_date)) <= 2 THEN 0 ELSE 1 END AS new_group FROM test_data ) t1 ) t2 GROUP BY user_id; -
spark table api
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.{col, datediff, lag, max, sum, when}
// 创建Spark会话
val spark = SparkSession.builder.appName("MaxLoginDays").getOrCreate()
// 提供的测试数据
val data = Seq(
(1001, "2021-11-05"),
(1001, "2021-11-06"),
(1001, "2021-11-08"),
(1001, "2021-11-10"),
(1001, "2021-11-15"),
(1001, "2021-11-16"),
(1001, "2021-11-18"),
(1001, "2021-11-19"),
(1002, "2021-11-05"),
(1002, "2021-11-07"),
(1002, "2021-11-09"),
(1002, "2021-11-11"),
(1002, "2021-11-13"),
(1002, "2021-11-16")
)
// 定义数据架构
val schema = Seq("user_id", "login_date")
// 创建DataFrame
val df = spark.createDataFrame(data).toDF(schema: _*)
// 定义窗口函数,按照user_id分区,按照login_date排序
val window = Window.partitionBy("user_id").orderBy("login_date")
// 使用lag函数计算当前行和上一行的日期差,判断是否为新的分组
val new_group = when(datediff(col("login_date"), lag(col("login_date"), 1).over(window)) <= 2, 0).otherwise(1)
// 使用sum函数计算每个分组的id,使用count函数计算每个分组的天数
val group_id = sum(new_group).over(window)
val login_days = count("user_id").over(window.partitionBy("user_id", "group_id"))
// 使用groupBy和max函数计算每个用户的最大连续登陆天数
val result = df.withColumn("new_group", new_group)
.withColumn("group_id", group_id)
.withColumn("login_days", login_days)
.groupBy("user_id")
.max("login_days")
.withColumnRenamed("max(login_days)", "max_login_days")
// 显示结果
result.show()
MapPartitionsWithIndex
- 用mapPartitionsWithIndex 生成手机号的彩虹表
// 导入相关的库
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import java.security.MessageDigest
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Put, Table}
import org.apache.hadoop.hbase.util.Bytes
// 创建Spark会话
val spark = SparkSession.builder.appName("RainbowTable").getOrCreate()
// 定义MD5加密函数
def md5(s: String): String = {
MessageDigest.getInstance("MD5").digest(s.getBytes).map("%02x".format(_)).mkString
}
// 定义HBase连接函数
def getHBaseConnection(): Connection = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "localhost") // 设置ZooKeeper地址
conf.set("hbase.zookeeper.property.clientPort", "2181") // 设置ZooKeeper端口
ConnectionFactory.createConnection(conf)
}
// 定义HBase写入函数
def writeToHBase(iter: Iterator[(Int, String, String)]): Unit = {
val conn = getHBaseConnection() // 获取HBase连接
val table = conn.getTable("rainbow_table") // 获取HBase表
iter.foreach { case (index, phone, md5) =>
val put = new Put(Bytes.toBytes(index)) // 创建Put对象,以分区索引为行键
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("phone"), Bytes.toBytes(phone)) // 添加手机号列
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("md5"), Bytes.toBytes(md5)) // 添加MD5列
table.put(put) // 写入HBase表
}
table.close() // 关闭HBase表
conn.close() // 关闭HBase连接
}
// 生成手机号的RDD,假设只生成130开头的手机号
val rdd = spark.sparkContext.parallelize(13000000000L to 13099999999L, 100) // 创建一个有100个分区的RDD
// 使用mapPartitionsWithIndex算子对每个分区的手机号进行MD5加密,并返回分区索引,手机号和MD5值的元组
val result = rdd.mapPartitionsWithIndex((index, iter) => iter.map(phone => (index, phone.toString, md5(phone.toString))))
// 使用foreachPartition算子对每个分区的结果写入HBase
result.foreachPartition(writeToHBase)
// 停止Spark会话
spark.stop()
ReduceByKey
val sparkConf = new SparkConf()
.setAppName("Simple Application")
.setMaster("local[1]")
val sc = new SparkContext(sparkConf)
val seqRDD = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3), ("a", 4), ("b", 1)), 2)
//分组前给每条记录值打上1的计数,便于key的个数统计
val valueOneRDD = seqRDD.mapValues(v => (v, 1))
// 分组求和 以及 累计key的个数
val byKeyRDD = valueOneRDD.reduceByKey((v1, v2) => (v1._1 + v2._1, v1._2 + v2._2))
byKeyRDD.foreach(println(_))
// 对value二次处理,算得平均值
val avgResRDD = byKeyRDD.mapValues(tp => (tp._1/tp._2).toDouble)
avgResRDD.foreach(println)
sc.stop()
(b,(3,2))
(a,(5,2))
(c,(3,1))
(b,1.0)
(a,2.0)
(c,3.0)
知识点
hadoop jar 、spark submit 与yarn交互的异同点:
- hadoop jar
- 客户端向 YARN 提交 Hadoop Jar 命令,指定程序包的路径和主类,以及输入和输出的数据路径。
- YARN 的 ResourceManager(RM)向 NodeManager(NM)通信,为该应用程序分配第一个容器、并在这个容器中运行这个应用程序对应的 ApplicationMaster(AM)。
- AM 启动后,对作业进行拆分,拆分出 Map 和 Reduce 任务,这些任务可以运行在一个或多个容器中。
- 然后 AM 向 RM 申请要运行任务的容器,并定时向 RM 发送心跳。
- 申请到容器后,AM 会去和容器对应的 NM 通信,而后将任务分发到对应的 NM 中的容器去运行。
- 容器中运行的任务会向 AM 发送心跳,汇报自身情况。
- 当程序运行完成后,AM 再向 RM 注销并释放容器资源。
- spark submit
- 客户端向 YARN 提交 spark submit 命令,指定程序包的路径和主类,以及运行模式(client 或 cluster)和其他参数。
- YARN 的 ResourceManager(RM)向 NodeManager(NM)通信,为该应用程序分配第一个容器,并在这个容器中运行这个应用程序对应的 ApplicationMaster(AM)。
- AM 启动后,根据 spark submit 命令的参数,向 RM 申请要运行 Spark driver 和 executor 的容器,并定时向 RM 发送心跳。
- client 模式:Spark driver 运行在客户端进程中,AM 只负责申请和分配 executor 的容器,Spark driver 和 executor 之间的通信不经过 AM。
- cluster 模式:Spark driver 运行在 AM 所在的容器中,AM 既负责申请和分配 executor 的容器,也负责协调和监控 Spark driver 和 executor 之间的通信。
- 申请到容器后,AM 会去和容器对应的 NM 通信,而后将 Spark driver 和 executor 分发到对应的 NM 中的容器去运行。
- 容器中运行的 Spark driver 和 executor 会向 AM 发送心跳,汇报自身情况。
- 当程序运行完成后,AM 再向 RM 注销并释放容器资源。
fit transform
- transform
底层就是map算子,针对的是当前行。 - fit
针对的是所有数据集的模型算法。
predictvs transform
在Spark MLlib库中,predict和transform两个函数都用于进行预测,但适用的情境有所不同。
predict函数:此函数主要用于对单个数据点进行预测。例如,如果你有一个已经训练好的模型,并且你希望对一个新的样本进行预测,你可以直接使用predict函数。
举例,如下面在已经训练好的线性回归模型中,输入一个特征向量进行预测:
val prediction = model.predict(Vectors.dense(Array[Double](1.0, 2.0, 3.0)))
transform函数:反之,当你有一批新的数据(如一个DataFrame)需要进行预测时,你应该使用transform函数。这个函数会批量地对DataFrame中的数据进行预测,并创建一个新的DataFrame来保存预测结果。
例如:
val predictions = model.transform(testData)
在这个例子中,model是预先训练好的模型,testData是需要进行预测的DataFrame。transform函数将会在testData的基础上添加一列预测结果。
总的来说,你可以根据你的需求选择使用predict还是transform函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号