消息队列知识点
RabbitMQ
消息不丢失
-
持久化
将消息保存到磁盘上,而不是只存在于内存中。这样可以避免因为服务器重启或者故障而导致消息丢失。
-
发送消息持久化
设置deliveryMode参数为2 ,确保消息到RabbitMQ服务的投递持久化模式为硬盘。 -
exchange、queue 持久化
durable = true 交换机和队列也要持久化到硬盘。
-
-
确认机制
- 生产者
可以通过事务(transaction)或者确认(confirm)模式来确保消息被正确地发送到RabbitMQ服务器。 - 消费者
可以通过应答(acknowledgement)模式来确保消息被正确地接收和处理。如果发生错误或者超时,RabbitMQ可以重新发送或者退回消息。 - 交换机退回
当消息无法从交换器路由到队列时,RabbitMQ会将消息强制返回给生产者。要实现这个功能,需要设置mandatory或者immediate参数为true,并且实现ReturnCallback接口来处理返回的消息。
- 生产者
消息重复消费
原因:因为网络波动或者其他原因导致消费者的ack消息没有成功传递给MQ。
解决方案:
- 根据业务数据库的唯一业务ID来判断是否有重复消费。
- 分布式锁或者数据库的锁。
延迟队列
超时订单、限时优惠、定时发布、供应商成本
- 死信队列+TTL实现
- 死信插件可以直接配置TTL
消息堆积
-
在消费者能力尚可的情况下增加消费者。
-
增加现有程序消费者线程池的活跃线程个数从而增加消费能力。
-
采用惰性队列使得队列扩容(惰性队列默认存储在硬盘,按需加载到内存中消费。)
- 受限于磁盘IO性能,时效性会很低。
集群模式
-
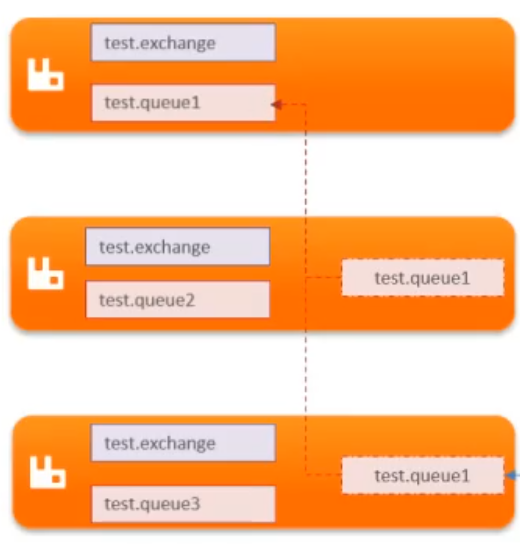
普通集群
- 共享交换机、队列元信息。
- 不同节点存储的队列消息不一样,但会存储其他节点队列的引用。
- 当节点宕机,消息会丢失。
-
镜像集群 (主从、高可用)
- 节点之间主从复制备份(交换机、队列、消息)
- 互为镜像节点
- 主节点宕机,从节点会选举为主节点。
- 主从复制存在数据丢失可能
-
仲裁队列(要求集群强一致性)(Quorum)
- 拥有镜像集群的一切特性
- 基于Raft协议,强一致性同步数据。
kafka
消息不丢失
-
消息持久化
ISR确保了除了leader其他副本也有数据写入。 -
确认机制
-
生产者发送至broker
采用异步发送+重试机制
-
broker确认
-
ack=0:集群收到即返回。
-
ack=1(默认): 集群leader(ISR的第一个)收到后返回,其他节点不管。
-
ack=all:配置的集群ISR特定个数(min.insync.relplicas配置的节点个数:建议大于等于集群节点的一半)收到才返回。
-
-
broker到消费者
消息丢失:默认为自动提交偏移量(5s一次),当消费者组发生再平衡,之前的偏移量提交可能会发生问题,导致消费丢失。
-
关闭自动提交
-
手动提交:同步提交加异步提交
try:异步 + finally:同步。
-
-
消息有序性
原因:数据根据key的不同,会落在topic的不同分区,单个分区可以保证有序,但是topic内保证不了。
解决办法:
写入到同一个分区。
- 建立topic时指定为一个分区。
- 建立很少量的分区,写入数据时key一样(根据key来选择分区)
集群高可用
-
多broker保障
保障了集群高可用 -
多副本保障
保障数据高可用
-
同步副本
ISR,开启ISR的副本,会优先被选择为leader,如果所有ISR都不可用,才会选择异步的普通副本。 -
异步副本
普通副本,异步同步leader数据,比同步集合节点要慢。
-
副本Leader的作用主要有以下几点:
- 处理读写请求:副本Leader负责接收生产者(Producer)发送的消息,并将消息写入到磁盘上。同时,副本Leader也负责响应消费者(Consumer)的读取请求,并将消息发送给消费者。
- 同步数据:副本Leader负责将自己的数据同步给其他副本Follower,以保证数据在多个副本之间的一致性。副本Leader会维护一个同步副本集合(ISR),其中包含了与自己保持同步的所有副本。
选举新的Leader:当副本Leader发生故障或者失去连接时,Kafka的Controller会触发副本Leader选举,从ISR集合中选择一个新的副本作为新的Leader(ISR顺位上位:越靠前数据同步就会越及时)。这样可以保证分区的高可用性和数据的安全性。
数据清理机制
-
数据存储
-
设计逻辑
- 提高写入性能:Kafka采用顺序写入的方式,将消息追加到数据文件的末尾。如果数据文件过大,会影响写入效率和磁盘空间利用率。通过数据分块,可以保证每个数据文件都是一个固定大小的连续空间,提高写入性能和磁盘空间利用率。
- 提高读取性能:Kafka采用内存映射的方式,将数据文件映射到内存中,加快读取速度。如果数据文件过大,会占用过多的内存资源,影响其他进程的运行。通过数据分块,可以控制每个数据文件的内存映射大小,提高读取性能和内存资源利用率。
- 提高清理效率:Kafka支持两种清理策略,一种是基于时间的清理(log.retention.hours),一种是基于大小的清理(log.retention.bytes)。当数据文件超过设定的时间或者大小时,就会被清理掉。如果数据文件过大,会导致清理操作耗时过长,影响正常的读写操作。通过数据分块,可以使得每个数据文件都是一个独立的清理单元,提高清理效率和系统稳定性。
-
文件格式
-
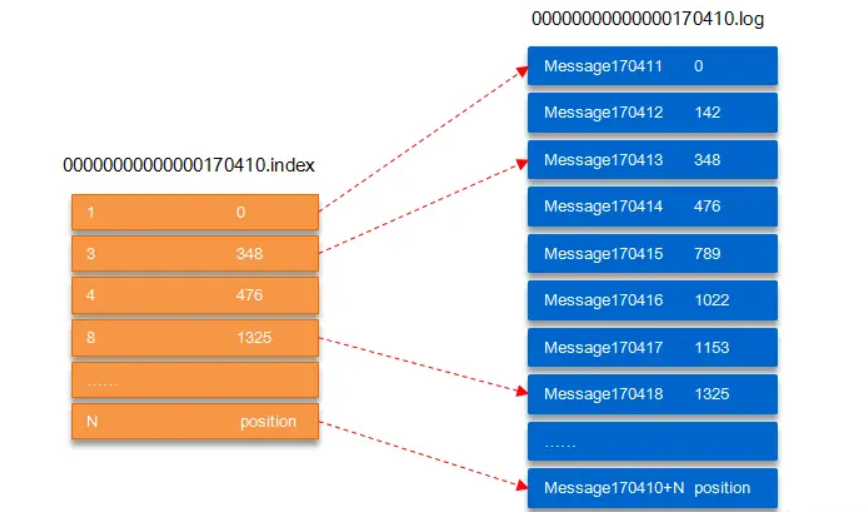
index文件:file.index (类似mysql innodb中的稀疏索引)
offset 物理偏移地址 -
segment文件:file.log
消息 物理偏移地址 -
timeindex文件
0.10.0版本之后才有可以根据时间戳定位到文件。
-
-
-
删除机制
- 时间
默认TTL周期为七天。 - 大小
默认关闭需要打开。
- 时间
高性能设计(快)
-
Producer 生产的数据持久化到 broker,采用页缓存实现顺序追加写,同时使用 mmap 加速数据写入;
当一个进程准备写入数据到磁盘上的文件时,操作系统也会先将数据写入到页缓存中,并将其标记为脏页(dirty page),即内存数据页跟磁盘数据页内容不一致的页。这样可以提高写入的速度,但也存在数据丢失的风险,比如在服务器断电或关机时。为了保证数据的一致性,操作系统会周期性地或在满足一定条件时,将脏页写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
Kafka利用了页缓存的优势,将消息记录排序后持久化到本地磁盘中,而不是随机的写入,而是不断追加到文件末尾,这样就实现了磁盘的顺序写,提高了写入的吞吐量。同时,Kafka也使用了mmap(内存映射)的技术,将文件映射到内存中,从而可以直接操作内存,而不需要通过系统调用。这样就减少了用户态和内核态的切换,提高了读写的效率。
LSM树的写机制,先写入内存然后再写入硬盘,SSTable分层设计,多次合并设计。 -
ISR
- Kafka 写入到 mmap 之后就立即 flush 然后再返回 Producer 叫同步 (sync);
- 写入 mmap 之后立即返回 Producer 不调用 flush 叫异步 (async)。
-
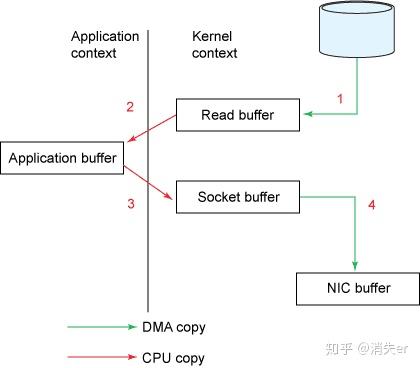
Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,直接转到 socket buffer 进行网络发送。
Tips:
- 利用了操作系统的DMA(Direct Memory Access)技术,使得硬件可以绕过CPU,直接访问系统主内存。
- mmap: Memory Mapped Files
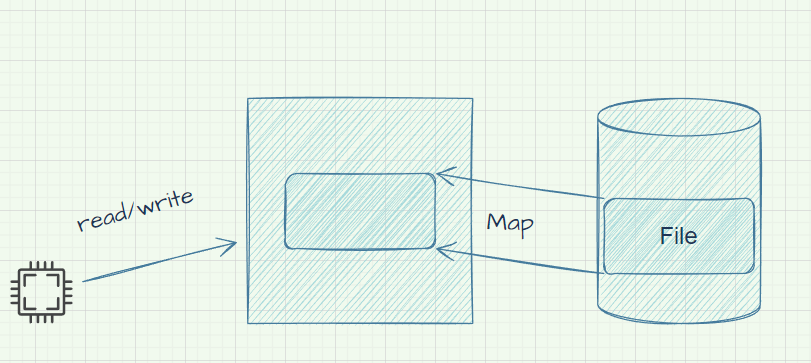
Kafka是通过使用mmap和页缓存来提高数据读写性能的(保证顺序追加写),同时还使用了零拷贝来提高网络传输性能。
各种消费
- 消费线程并发
默认的JavaConsumer是单线程,一个线程负责消费数据;另外一个心跳线程与Broker维持心跳防止链接断开。
无论是spring、kafka、spark都最好保证消费线程数和KafkaConsumer保持一对一的关系,线程数和topic的partition个数一致;
也就是说最佳的线程数和分区数是相等的,这样可以实现最大的并行度和最高的效率。
@KafkaListener (topics = "topic", concurrency = "3")
public void processMessage (String content) {
// 消息处理逻辑
}
- 消费参数
- max_pool_records_config
一次call拉取消息条数默认为500 - max_poll_interval_ms_config
一次call处理所有数据的消息间隔,如果太久就会被broker剔除,将分区分配给其他消费者,需要合理预估业务实际时间。 - auto_offset_reset_config
- latest
消费组启动之后只消费订阅的topic新进入的消息 - earliest
消费组启动之后第一次从offset:0开始消费,之后再次启动按照当前组offset继续消费,和group id 有绑定关系,区别于from-beginning(每次都从offset:0开始消费)。
- latest
- max_pool_records_config
总结
| 方面 | Kafka | RabbitMQ |
|---|---|---|
| 应用场景 | 适合处理大数据量的流式数据,比如日志分析,数据采集,事件驱动等。 | 适合实现实时的,对可靠性要求较高的消息传递,比如电商订单,支付通知,邮件发送等。 |
| 架构模型 | 基于分布式日志文件的架构,将每个主题(Topic)划分为多个分区(Partition),每个分区保存一系列有序的消息,并且可以被多个消费者(Consumer)并发访问。 | 基于经典的消息代理(Broker)架构,使用多种类型的交换器(Exchange)来路由消息到不同的队列(Queue),每个队列保存一系列有序的消息,并且可以被多个消费者并发访问。 |
| 吞吐量 | 采用批量处理和零拷贝技术,优化了数据的读写和传输性能,可以达到每秒百万级别的吞吐量。 | 采用内存或硬盘存储消息,并支持事务和确认机制,保证了数据的可靠性,但是牺牲了一部分吞吐量。 |
| 消息顺序 | 可以保证单个分区内的消息不重复,不能跨多个分区或者多个主题。 | 可以保证单个队列内的消息不重复,不能跨多个队列或者多个交换器。 |
| 消息匹配 | 不支持消息匹配和过滤功能,需要消费者自己实现匹配逻辑。 | 支持多种类型的交换器和绑定键来实现消息匹配和过滤功能,开发成本低。 |
| 消息超时 | 不支持延迟队列功能,需要自己实现中转消费者和数据库存储逻辑。 | 支持延迟队列功能,可以通过设置TTL和死信队列来实现。 |
Disrupter
JAVA Disrupter 是一个高性能的异步处理框架,它能够在无锁的情况下实现队列的并发操作。
它的核心是一个环形缓冲区(RingBuffer),它是一个数组,用于存储和传递事件(Event)。
RingBuffer 有一个序号(Sequence),用于标识每个事件的位置。生产者(Producer)和消费者(Consumer)都有自己的序号,用于跟踪 RingBuffer 中的事件。
生产者和消费者之间通过序号+栅栏来协调,避免数据的覆盖或丢失。
JAVA Disrupter 的并发写不用锁的实现方式有以下几点:
- JAVA Disrupter 使用 CAS(Compare And Swap)操作来保证多个生产者之间的数据安全,而不是使用锁。CAS 操作是一种原子操作,它可以比较并更新一个变量的值,如果变量的值没有被其他线程修改,就更新成功,否则失败。CAS 操作可以避免锁的开销,提高并发性能。
- JAVA Disrupter 使用WaitStrategy(等待策略)来控制消费者的等待方式,而不是使用锁。WaitStrategy 是一种策略模式,它定义了消费者如何等待生产者产生新的事件。不同的 WaitStrategy 有不同的性能和资源消耗,例如 BlockingWaitStrategy,SleepingWaitStrategy,YieldingWaitStrategy,BusySpinWaitStrategy 等。WaitStrategy 可以根据不同的场景和需求进行选择,以达到最佳的效果。
- YieldingWaitStrategy:如果没有可用的序列号(Sequence),则首先自旋(Spin)重试 100 次(此值可设置,默认 100 次),如果在重试过程中,存在可用的序列号,则直接返回可用的序列号。否则,如果重试指定次数以后,还是没有可用序列号,则调用 Thread.yield 方法,放弃 CPU 的使用权,让其他线程可以使用 CPU。
- JAVA Disrupter 使用缓存行(64Byte)填充(Cache Line Padding)来解决伪共享(False Sharing)问题,而不是使用锁。伪共享是一种多核 CPU 下的性能问题,它是指多个线程同时访问同一个缓存行(Cache Line)中的不同变量,导致缓存行的失效和更新,降低性能。缓存行填充是一种优化技术,它是指在变量的前后添加一些无用的变量(空的Event对象),使得每个变量都占据一个缓存行,避免多个线程的干扰,提高性能 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号