
爬虫大作业
1.选一个自己感兴趣的主题(所有人不能雷同)。
音乐网站

2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
import requests import json import re #根据歌词id提取歌词 lrc_url = 'http://http://music.163.com/#/song?id=1775978/api/song/lyric?' + 'id=' + str(531051217) + '&lv=1&kv=1&tv=-1' lyric = requests.get(lrc_url) json_obj = lyric.text j = json.loads(json_obj) lrc = j['lrc']['lyric'] pat = re.compile(r'\[.*\]') lrc = re.sub(pat, "", lrc) lrc = lrc.strip() print(lrc)
3.对爬了的数据进行文本分析,生成词云。
abel_mask = np.array(Image.open("filepath")) text_from_file_with_apath = open('filepath').read() wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True) wl_space_split = " ".join(wordlist_after_jieba) my_wordcloud = WordCloud().generate(wl_space_split) my_wordcloud = WordCloud( background_color='white', mask = abel_mask, max_words = 200, stopwords = STOPWORDS, font_path = 'C:/Users/Windows/fonts/simkai.ttf', max_font_size =50, random_state = 30, scale=.5, ).generate(wl_space_split) image_colors = ImageColorGenerator(abel_mask) plt.imshow(my_wordcloud) plt.axis("off") plt.show()


4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
完整代码
#coding:utf-8 import requests import json import re import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS from wordcloud import WordCloud import jieba import numpy as np from PIL import Image #根据歌词id提取歌词 lrc_url = 'http://music.163.com/api/song/lyric?' + 'id=' + str(1775978) + '&lv=1&kv=1&tv=-1' lyric = requests.get(lrc_url) json_obj = lyric.text j = json.loads(json_obj) lrc = j['lrc']['lyric'] pat = re.compile(r'\[.*\]') lrc = re.sub(pat, "", lrc) lrc = lrc.strip() print(lrc) #读入背景图片 abel_mask = np.array(Image.open("filepath")) #读取要生成词云的文件 text_from_file_with_apath = open('filepath').read() #通过jieba分词进行分词并通过空格分隔 wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True) wl_space_split = " ".join(wordlist_after_jieba) my_wordcloud = WordCloud().generate(wl_space_split) my_wordcloud = WordCloud( background_color='white', # 设置背景颜色 mask = abel_mask, # 设置背景图片 max_words = 200, # 设置最大现实的字数 stopwords = STOPWORDS, # 设置停用词 font_path = 'C:/Users/Windows/fonts/simkai.ttf', max_font_size =50, random_state = 30, # 设置有多少种随机生成状态,即有多少种配色方案 scale=.5, ).generate(wl_space_split) # 根据图片生成词云颜色 image_colors = ImageColorGenerator(abel_mask) #my_wordcloud.recolor(color_func=image_colors) # 以下代码显示图片 plt.imshow(my_wordcloud) plt.axis("off") plt.show()
爬虫结果
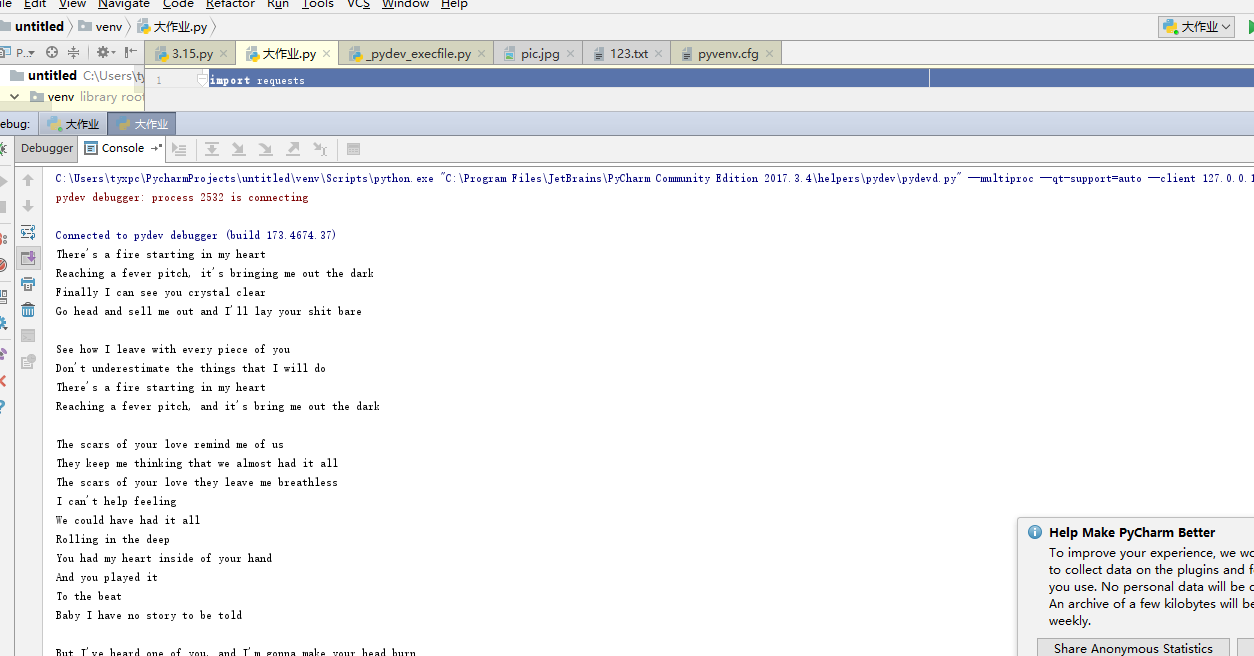
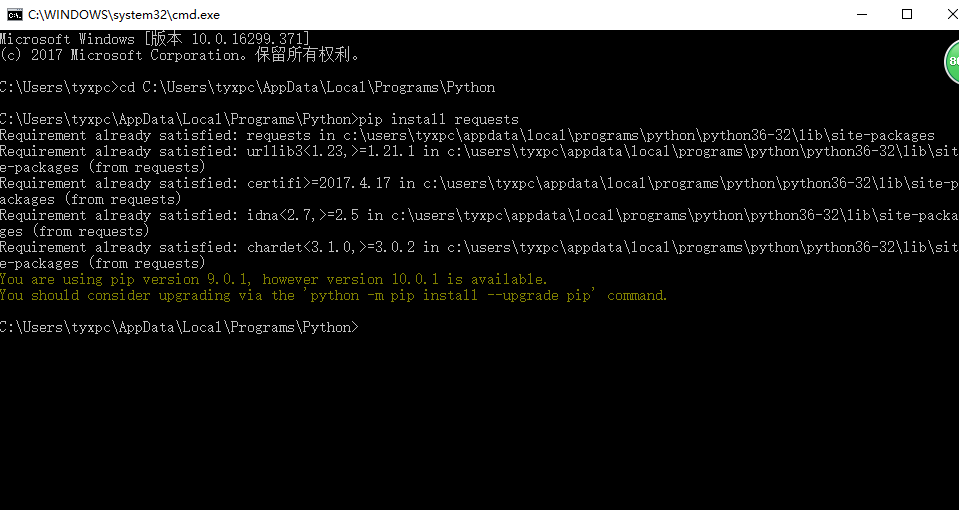
在实现的过程安装了pip 包
ModuleNotFoundError: No module named 'requests'等错误上网查询解决方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号