java集合框架学习总结
(文章为自己学习的总结)
前言:熟悉数据结构相关知识可以更好学习集合框架!!!
我感觉学习一个框架或者其它技术,通过先了解它的大致结构,熟悉它都有哪几部分,将会更快的上手,以一种一览众山小的姿态,从整体学习入手,将会对以后的学习将事半功倍。👍👍👍
学习中大家多多参照Java文档和深入源码学习,更有感觉!!!
java在线文档
首先 java集合框架在ava.util包下。当然还有一些线程安全的集合框架在java.util.concurrent包下,本章节暂不介绍,以后在并发编程章节介绍。

Java集合框架主要包括Collection和Map两种类型。
Collection和Map均为两种集合类型的顶级接口。
集合是什么?
一句话:集合就是存放对象的容器。
集合使用
我们学习集合就是学习在什么样的需求下用什么集合。
比如需要线程安全的时候,我们选用线程安全的集合。
比如CopyOnWriteArrayList和CopyOnWriteArraySet
经常进行查询操作的时候,我们选用查询快的集合比如ArrayList。
需要咱们干的就是这个。
Collection& Map类
Collection类图
上大图!!!
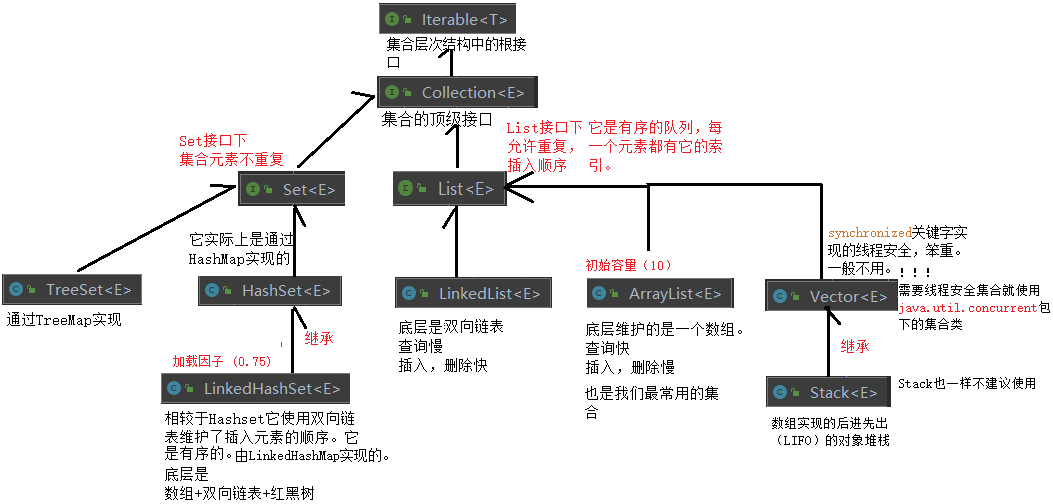
其中Collection又有3种子类型,分别是List、Set、Queue。
Map中存储的主要是键值对映射。
1.Collection 接口下的(单列集合)
1.1List 接口常见实现类
- ArrayList :底层维护了一个数组, 随机访问, 没有同步, 线程不安全
- LinkedList : List和Deque接口的双向链表实现。没有同步, 线程不安全
- Vector :也是维护一个数组,它给几乎所有public方法都加上了synchronized关键字,所以是线程安全的。
关于Vector和Stack的弃用
ArrayList特点分析
它里面实际维护了一个数组缓冲区
transient Object[] elementData;
transient:不可持久化的,不可序列化的。
ArrayList 的容量就是这个数组缓冲区的长度。当添加第一个元素时开始扩容。
第一次扩容为10(默认数组大小)。以后如果容量不够,就扩容为数组的1.5倍。
看一下扩容源码:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//右移运算符等价于除以2
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 扩容1.5倍还是不够,那么直接用minCapacity(最小需要的数组长度)
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
1.2Set 接口常见实现类
插入元素不可重复,hashCode()&&equals()两者判断同时为真则为相同元素。
按照具体需求可以重写。
-
HashSet :元素无序且唯一,效率高,但线程不安全,可存储一个null。使用hash表(数组)存储元素。底层为HashMap实现,就是插入的元素为key,value有一个默认值。
-
LinkedHashSet :在HashSet的基础上加入双向链表保证了元素顺序。底层为LinkedHashMap实现。
-
TreeSet :TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。
TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向
TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过
CompareTo方法比较没有返回0。
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是负数,则表明obj1小于obj2。如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0。
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法。
异同点
1.ArrayList和LinkedList
(1)ArrayList是实现了基于动态数组的数据结构,LinkedList基于双向链表的数据结构。
(2)对于随机访问get和set,ArrayList绝对优于LinkedList,因为LinkedList要移动指针。
(3)对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
2.Map接口下的(双列集合 key:value形式)
Map类图
再上图!!!
2.1List 接口常见实现类
Map接口有四个比较重要的实现类,分别是HashMap、LinkedHashMap、TreeMap和Hashtable.
- HashMap :最常用的Map。也是面试的重点!!!
先看特点:
HashMap小结
- Map接口的常用实现类:HashMap、Hashtable和Properties.
- HashMap是 Map 接口使用频率最高的实现类。
- HashMap,是以 key-val对的方式来存储数据(HashMapSNode类型)[案例Entry
- key 不能重复,但是值可以重复,允许使用null键和null值。
- 如果添加相同的key,则会覆盖原来的key-val ,等同于修改.(key不会替换,val会替换
- 与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的.
- HashMap没有实现同步,因此是线程不安全的
jdk1.8的HashMap 实现
和hashmap一样,jdk 1.8中ConcurrentHashmap采用的底层数据结构为数组+链表+红黑树的形式。数组可以扩容,链表可以转化为红黑树。

什么时候扩容?
第一种情况
- 默认的数组长度
DEFAULT _INITIAL_ CAPACITY=16,默认的负载因子DEFAULT LOAD FACTOR=0.75;
当键值对数量超过16 * 0.75 = 12时,就会触发扩容导致数组长度变为16 * 2 = 32。那么下一次当键值对数量超过32 * 0.75 = 24就扩容到32 * 2 = 64了。
第二种情况
- 当一条链表中元素个数超过默认设定(8个),但数组的大小还未超过64的时候,便将数组进行扩容,如果数组的大小>=64则将链表转化成红黑树。
什么时候链表转化为红黑树?
链表中的元素个数也就是键值对数量>=默认设定(8个)并且数组大小已经>=64时,将链表转化为红黑树。
LinkedHashMap
有两点:
- LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
- LinkedHashMap的基本实现思想就是----多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解。
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。
LinkedHashMap支持两种顺序插入顺序 访问顺序
1.插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
2.访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
从下图也可以看出在HashMap的基础加入用于维护顺序的双向链表。

HashMap与LinkedHashMap的两种遍历方法
package com.zry.map;
import java.util.*;
/**
* @author zry
* @ClassName MapMethod.java
* @Description TODO
* @createTime 2022年01月12日
*/
public class MapMethod {
/**
* 默认负载因子 (.75) 在时间和空间成本之间提供了良好的折衷。 较高的值会减少空间开销,
* 但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put )。
* 在设置其初始容量时,应考虑映射中的预期条目数及其负载因子,
* 以尽量减少重新哈希操作的次数。 如果初始容量大于最大条目数除以负载因子,则不会发生重新哈希操作。
*/
@SuppressWarnings("all")
public static void main(String[] args) {
HashMap map = new HashMap<>();
map.put("1", "kkk");
map.put("2", "kkk");
map.put("3", "jjj");
// 为了便利方便,作者将 map中的key,value又放到 EntrySet,
// EntrySet集合仅仅指向了map中table数组元素Node
//
//获取迭代器便利
Set set1 = map.entrySet();
Iterator iterator = set1.iterator();
while (iterator.hasNext()) {
//table数组元素Node<K,V> 实现了 Map.Entry接口
//Entry接口中定义了许多我们需要的方法。
//所以我们向下转型Object->Map.Entry。
Map.Entry entry = (Map.Entry) iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
entry.setValue("你好");//将所有的value替换成“你好”
}
//使用增强for便利Map(本质还是迭代器)
LinkedHashMap linkedMap =new LinkedHashMap<>();
linkedMap.putAll(map);
Set set2 = linkedMap.entrySet();
for (Object o : set2) {
Map.Entry node = (Map.Entry) o;
System.out.println(node);
System.out.println(node.getKey() + ":" + node.getValue());
}
}
}
TreeMap
在Map集合框架中,除了HashMap以外,TreeMap也是我们工作中常用到的集合对象之一。
与HashMap相比,TreeMap是一个能比较元素大小的Map集合,会对传入的key进行了大小排序。其中,可以使用元素的自然顺序,也可以使用集合中自定义的比较器来进行排序;
不同于HashMap的哈希映射,TreeMap底层实现了树形结构,至于具体形态,你可以简单的理解为一颗倒过来的树---根在上--叶在下。如果用计算机术语来说的话,TreeMap实现了红黑树的结构,形成了一颗二叉树。
TreeMap具有如下特点:
-
不允许出现重复的key;
-
可以插入null键,null值;
-
可以对元素进行排序;
-
无序集合(插入和遍历顺序不一致);
Hashtable
可以看作线程安全的HashMap。
HashTable的基本介绍
- 存放的元素是键值对:即 K-V
- hashtable的键和值都不能为null,否则会抛出NullPointerException
- hashTable使用方法基本上和HashMap一样
- hashTable是线程安全的(synchronized), hashMap是线程不安全的
简单说明一下Hashtable的底层
1。底层有数组 HashtagLe$Entry[]初始化大小为11
2。临界值threshold 8 = 11 *0.75
HashTable的应用案例
下面的代码是否正确,如果错误,为什么?
HashTableExercise.javaHashtable table = new Hashtable()://ok
table.put("john",100);//ok
table.put(null,100);/异常
table.put("john", null);//异常
table.put("lucy", 100);//ok
table.put("lic",100);//ok
table.put(lic",88);//替换value
System.out.println(table);
它给几乎所有public方法都加上了synchronized关键字,这也导致它的性能问题。
所以不建议使用。
Vector和HashTable被弃用后,它们被ArrayList和HashMap代替,但它们不是线程安全的,所以Collections工具类中提供了相应的包装方法把它们包装成线程安全的集合。
异同点
1.HashSet、LinkedHashSet比较
Set接口
Set不允许包含相同的元素,如果试图把两个相同元素加入同一个集合中,add方法返回false。
Set判断两个对象相同不是使用==运算符,而是根据equals方法。也就是说,只要两个对象用equals方法比较返回true,Set就不会接受这两个对象。
HashSet
HashSet有以下特点:
-> 不能保证元素的排列顺序,顺序有可能发生变化。
-> 不是同步的。
-> 集合元素可以是null,但只能放入一个null。
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值也相等。
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
3.HashMap、LinkedHashMap、TreeMap比较
HashMap
hashMap是最常用的Map,根据键的HashCode值存储数据,可以根据键直接获取它的值,具有很快的访问速度,遍历时候的顺序是完全随机的。HashMap只允许一个键为Null,允许多个值为Null。
特性: 完全随机
优点: 随机访问,取值速度快
缺点: 多个线程同时写HashMap可能导致数据不一致,如果需要同步,使用Collection的synchronizedMap方法或者使用ConcurrentHashMap
LinkedHashMap
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,与HashMap的随机遍历不同,在用Iterator遍历的时候,先得到的记录肯定是先插入的,类似于python中的OrderedDict。
遍历速度会比HashMap慢,不过有一种情况例外: 当HashMap的容量很大,实际数据很少时 , 因为HashMap的遍历速度和它的容量有关,而LinkedHashMap只跟实际数据量有关。
TreeMap
TreeMap实现SortMap接口,能够将它保存的记录按键排序,默认是按键的升序排列,也可以指定排序的比较器,遍历TreeMap的时候,得到的记录是按照键排过序的。
根据数据选择Map
一般情况下,我们用的最多的是HashMap,在Map中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列。
总结-开发中如何选择集舍实现类(记住)
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行选择,分析如下:
1)先判断存储的类型(一组对象[单列]或一组键值对[双列])
**2) 一组对象[单列]:Collection接口
- **允许重复:List**
增删多:LinkedList [底层维护了一个双向链表]
改查多:ArrayList [底层维护Object类型的可变数组]
- **不允许重复: Set**
无序: HashSet [底层是HashMap,维护了一个哈希表即(数组+链表+红黑树
排序: TreeSet [插入和取出顺序一致:LinkedHashSet,维护数组+双向链表
- 一组键值对[双列]:Map
键无序: HashMap [底层是:哈希表jdk7:数组+链表,jdk8:数组+链表+红黑树]
键排序:TreeMap
键插入和取出顺序一致: LinkedHashMap
读取文件Properties
Java hashCode()和equals()方法。
在Map中比较Key值,使用的hashCode()值和equals()方法,它们同时为真,Key值才算相等。
equals()方法用于确定两个Java对象的相等性。
当我们有一个自定义类时,我们需要重写equals()方法并提供一个实现,以便它可以用来找到它的两个实例之间的相等性。 通过Java规范,equals()和hashCode()之间有一个契约。 它说,“如果两个对象相等,即obj1.equals(obj2)为true,那么obj1.hashCode()和obj2.hashCode()必须返回相同的整数”。
无论何时我们选择重写equals(),我们都必须重写hashCode()方法。 hashCode()用于计算位置存储区和key。
Iterator和ListIterator区别
我们在使用List,Set的时候,为了实现对其数据的遍历,我们经常使用到了Iterator(迭代器)。
使用迭代器,你不需要干涉其遍历的过程,只需要每次取出一个你想要的数据进行处理就可以了。
但是在使用的时候也是有不同的。List和Set都有iterator()来取得其迭代器
对List来说,你也可以通过listIterator()取得其迭代器,两种迭代器在有些时候是不能通用的,
Iterator和ListIterator主要区别在以下方面:
(1)ListIterator有add()方法,可以向List中添加对象,而Iterator不能
(2)ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
(3)ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
(4)都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改。
因为ListIterator的这些功能,可以实现对LinkedList等List数据结构的操作。其实,数组对象也可以用迭代器来实现。
Collection 和 Collections区别
(1) java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
(2) java.util.Collections 是一个包装类(工具类/帮助类)。它包含有各种有关集合操作的静 态多态方法。此类不能实例化,就像一个工具类,用于对集合中元素进行排序、搜索以及线程安全等各种操作,服务于Java的Collection框架。
代码示例:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollections {
public static void main(String args[]) {
//注意List是实现Collection接口的
List list = new ArrayList();
double array[] = { 112, 111, 23, 456, 231 };
for (int i = 0; i < array.length; i++) {
list.add(new Double(array[i]));
}
Collections.sort(list);
for (int i = 0; i < array.length; i++) {
System.out.println(list.get(i));
}
// 结果:23.0 111.0 112.0 231.0 456.0
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号