谈谈JUC之CopyOnWriteArrayList
本博客系列是学习并发编程过程中的记录总结。由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅。
本篇博客介绍CopyOnWriteArrayList类,读完本博客你将会了解:
- CopyOnWriteArrayList的实现原理(写时复制);
- CopyOnWriteArrayList的使用场景;
我们知道ArrayList是线程不安全的。JDK1.5之前,要实现线程安全的List,我们可以
- 使用Vector类
- 使用
Collections.synchronizedList返回一个同步代理类; - 自己实现ArrayList的子类,并进行同步/加锁。
前两种的方式都相当与加了一把‘全局锁’,所得粒度过大,性能较差。第3种方式,需要自己实现,复杂度较高。
JDK1.5时,随着J.U.C引入了一个新的集合工具类——CopyOnWriteArrayList:

CopyOnWriteArrayList是ArrayList的线程安全变体,其中所有可变操作( add 、 set等)都是通过制作底层数组的新副本来实现的。这是一种“写时复制”的思想。通俗的理解就是当我们需要修改(增/删/改)列表中的元素时,不直接进行修改,而是先将列表Copy,然后在新的副本上进行修改,修改完成之后,再将引用从原列表指向新列表。
CopyOnWriteArrayList的实现原理
源码分析:
CopyOnWriteArrayList的字段很简单:
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
/**
* 排它锁, 用于同步修改操作
*/
final transient ReentrantLock lock = new ReentrantLock();
/**
* 内部数组
*/
private transient volatile Object[] array;
其中,lock仅仅再进行修改操作时进行同步,array就是内部实际保存数据的数组。
构造器定义
/**1.空参构造器:
* 创建一个空数组
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
/**
* 2.根据已有集合创建
*/
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
if (c.getClass() != ArrayList.class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
/**
* 3.根据已有数组创建
*Throws: NullPointerException – if the specified array is null
*/
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
核心方法
查询——get
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
可以看到,get方法并没有加锁,直接返回了内部数组对应索引位置的值:array[index]
添加——add
/**
*将指定元素附加到此列表的末尾
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray(); // getArray()获得旧数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); // 复制并创建新数组
newElements[len] = e; // 将元素插入到新数组末尾
setArray(newElements); // 内部array引用指向新数组
return true;
} finally {
lock.unlock();
}
}
add方法首先会进行加锁,保证只有一个线程能进行修改;然后会创建一个新数组(大小为n+1),并将原数组的值复制到新数组,新元素插入到新数组的最后;最后,将字段array指向新数组。
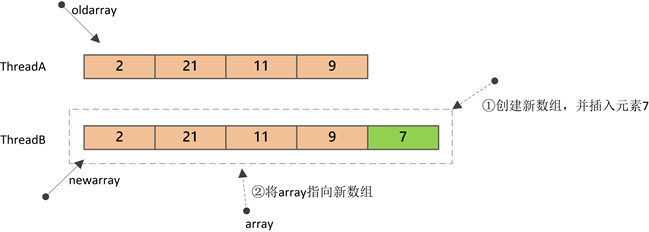
上图中,ThreadB对Array的修改由于是在新数组上进行的,所以并不会对ThreadA的读操作产生影响。
删除——remove
/**
*移除此列表中指定位置的元素。将任何后续元素向左移动(从它们的索引中减去 1)。返回从列表中删除的元素
*抛出:IndexOutOfBoundsException
*/
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index); // 获取旧数组中的元素, 用于返回
int numMoved = len - index - 1; // 需要移动多少个元素
if (numMoved == 0) // index位置刚好是最后一个元素时,直接不复制它就ok了。
setArray(Arrays.copyOf(elements, len - 1));
else {
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index, numMoved);//两次copy时把index位置隔开。
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
其它统计方法
public int size() {
return getArray().length;
}
public boolean isEmpty() {
return size() == 0;
}
迭代
CopyOnWriteArrayList对元素进行迭代时,仅仅返回一个当前内部数组的快照,也就是说,如果此时有其它线程正在修改元素,并不会在迭代中反映出来,因为修改都是在新数组中进行的。
// 1. 返回的迭代器是COWIterator
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
// 2. 迭代器的成员属性
private final Object[] snapshot;
private int cursor;
// 3. 迭代器的构造方法
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
// 4. 迭代器的方法...
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
//.... 可以发现的是,迭代器所有的操作都基于snapshot数组,而snapshot就是传递进来的array数组
到这里,我们应该就可以想明白了!CopyOnWriteArrayList在使用迭代器遍历的时候,操作的都是原数组!而其他线程对其修改后会生成一个新的数组,所以并不影响之前数组的遍历。这正是他的一个特点具有fail-safe ( 安全失败 )机制,也就是说这种遍历基于容器的一个克隆,也就是对容器内容的修改不影响遍历,即不会抛出CurrentModifyException;
三、总结
CopyOnWriteArrayList的思想和实现整体上还是比较简单,它适用于处理“读多写少”的并发场景。通过上述对CopyOnWriteArrayList的分析,读者也应该可以发现该类存在的一些问题:
1. 内存的使用
由于CopyOnWriteArrayList使用了“写时复制”,所以在进行写操作的时候,内存里会同时存在两个array数组,如果数组内存占用的太大,那么可能会造成频繁GC,所以CopyOnWriteArrayList并不适合大数据量的场景。
2. 数据一致性
CopyOnWriteArrayList只能保证数据的最终一致性,不能保证数据的实时一致性——读操作读到的数据只是一份快照。所以如果希望写入的数据可以立刻被读到,那CopyOnWriteArrayList并不适合。
其他网友的总结:
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
CopyOnWriteArrayList中add/remove等写方法是需要加锁的,目的是为了避免Copy出N个副本出来,导致并发写。
CopyOnWriteArrayList中的读方法是没有加锁的。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,当然,这里读到的数据可能不是最新的。因为写时复制的思想是通过延时更新的策略来实现数据的最终一致性的,并非强一致性。
所以CopyOnWrite容器是一种读写分离的思想,读和写不同的容器。而Vector在读写的时候使用同一个容器,读写互斥,同时只能做一件事儿。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号