字符串常见操作
String的底层结构
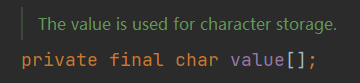
而在jdk8中,String的底层是用的字符数组。jdk9里面做了更改,节约String占用的内存。一个char占用两个字节,而程序中绝大多数String只有Latin-1字符,这些Latin-1字符只需要1个字节就够了。

一个final的字节数组,同时有一个coder用于对value中的字节进行编码的编码标识符。主要是LATIN1和UTF-16。如果发现字符串中只有Latin1字符就只需要给每个字符分配一个字节。
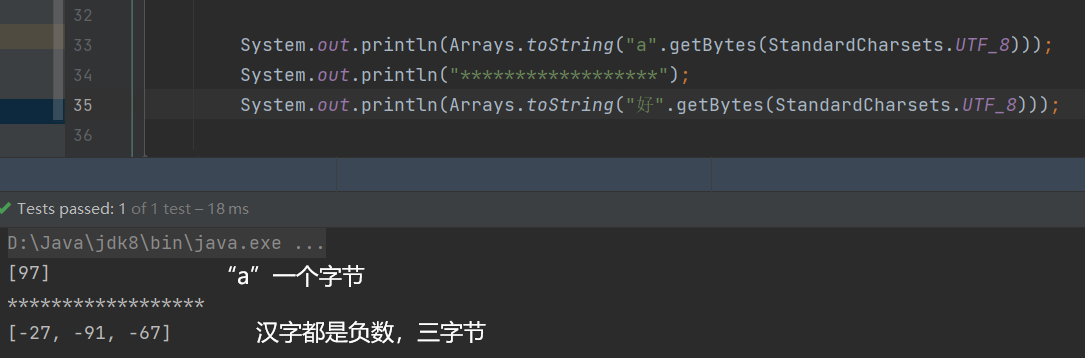
为什么没有用UTF-8,因为UTF-8是不定长的,比如字母只有一个字节,汉字有三个字节,而String像数组一样可以charAt随机访问。
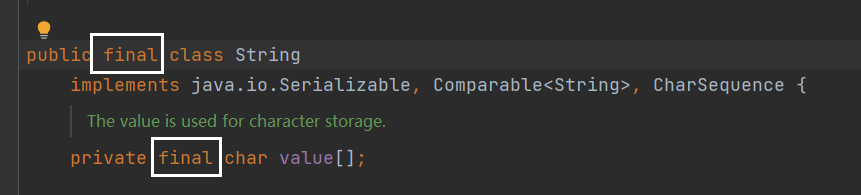
这些都不是重点,重点在于 final 修饰了底层的value
String的 不可变 性
网上关于String不可变性很多帖子,我就记录一下我的理解吧
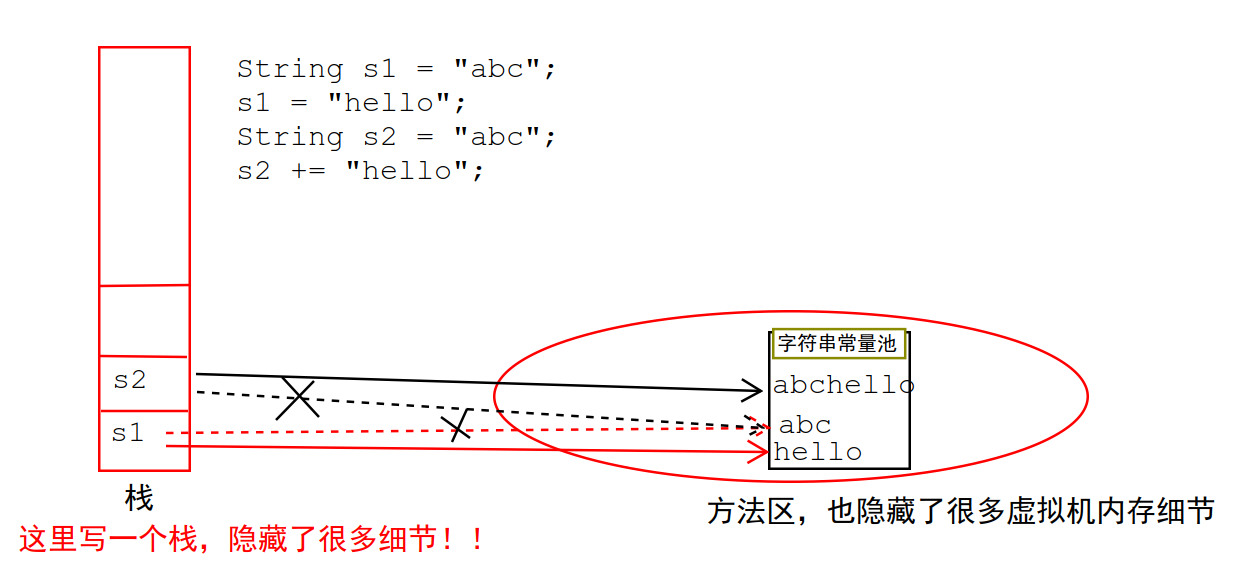
1、重新给字符串 赋值 或者 拼接,会重新开辟内存空间,而不是改变原来的value
2、还有String的replace()方法替换的时候也是重新开辟内存空间放新的字符串,而不是对原有的字符串修改。
JVM的一些概念和小调整
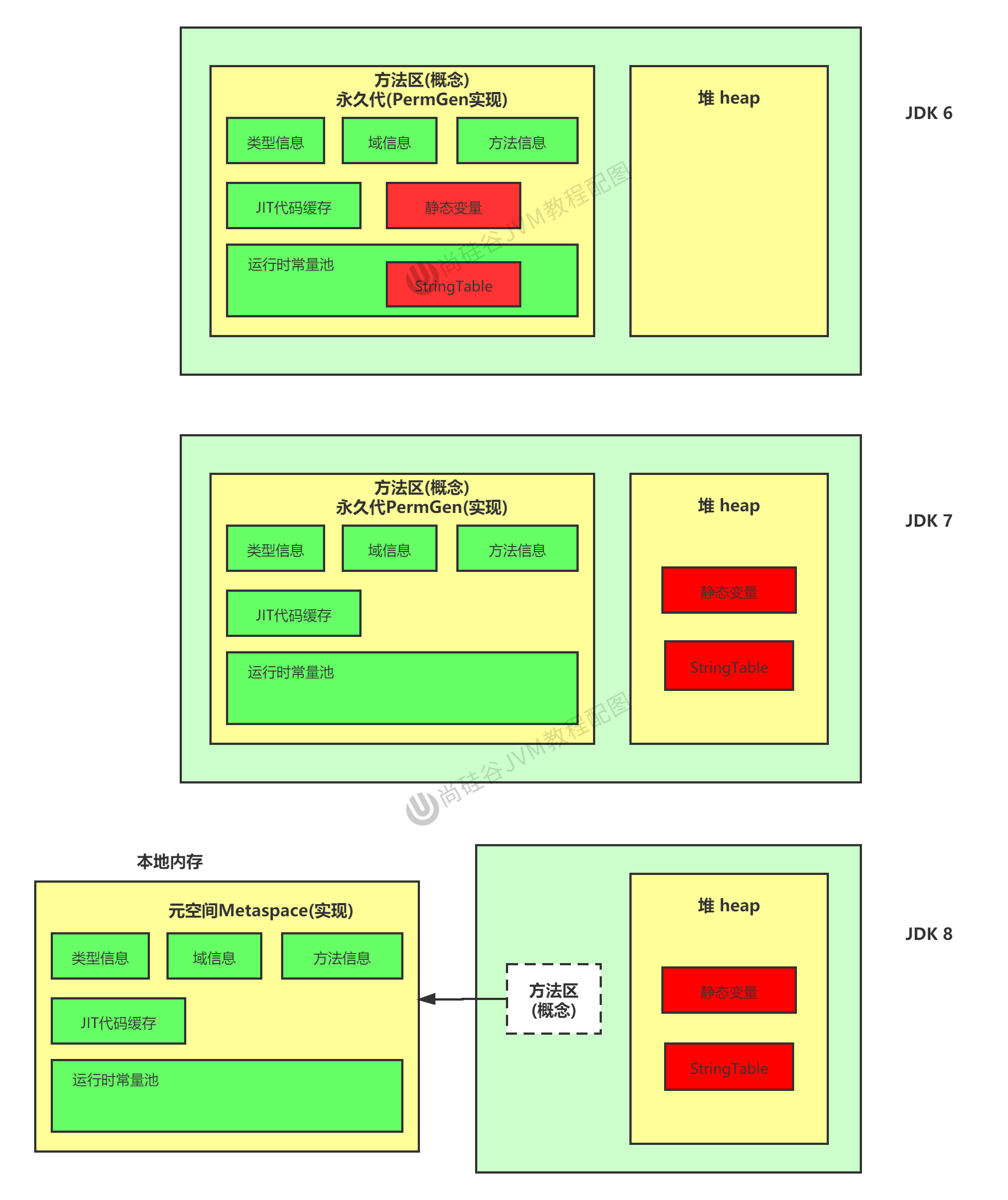
永久代、元空间
jdk6里面的方法区可以理解为永久代,放在堆空间中。对永久代设置大小很难,同时对永久代调优很难。jdk7将永久代也就是方法区中的静态变量和字符串常量池从永久代中独立出来在堆中,jdk8中将永久代取消改成元空间,放在物理机内存中,而字符串常量池和静态变量还是放在堆中。
 ——取自 哔哩哔哩 尚硅谷 宋鸿康老师的JVM课程(康师傅真的很细!!)
——取自 哔哩哔哩 尚硅谷 宋鸿康老师的JVM课程(康师傅真的很细!!)
字符串常量池
String的字符串常量池底层就是一个Hashtable,jdk6中这个表长度是固定的1009,随着常量池中字符串增多,Hash冲突严重,导致链表的长度变得越来越长。判断池中是否有字符串的效率下降的很快。jdk7及以后默认长度是60013,长度可以设置。
jdk6字符串常量池放在永久代,7及以后从永久代独立放在堆中。
为什么要调整到堆中?
因为放在永久代中,只有在full gc的时候才会对字符串常量池做回收,效率不高,而开发中,有大量的字符串被创建。
常见操作的原理
几个重要方法
StringBuilder中的toString方法——new了个String对象。
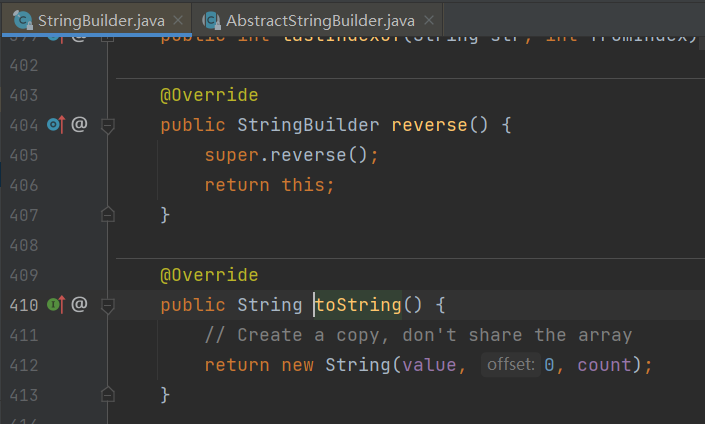
new String(" abc ")—— String的构造器
该方法会创建两个对象,一个在常量池中的abc,一个是new出来在堆中的对象。
string.intern()方法
jdk6:返回字符串常量池中这个字符串的地址,如果常量池中没有这个字符串就在池中创建这个字符串再返回池中字符串的地址。
jdk7、8:返回字符串常量池中这个字符串的地址,如果池中没有这个字符串,就在常量池中创建一个指针指向堆中这个字符串,返回池中指针的地址。(这也是字符串常量池放入堆中的好处)
字符串的拼接
常量和常量
拼接结果就在常量池中,并且是编译器优化。

编译后查看.class文件中会发现
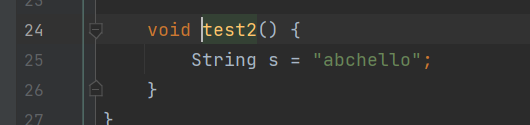
有变量
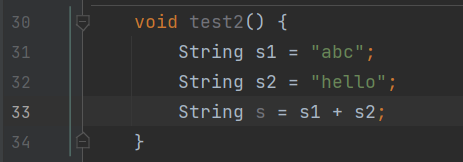
编译后查看.class文件

使用jclasslib查看:
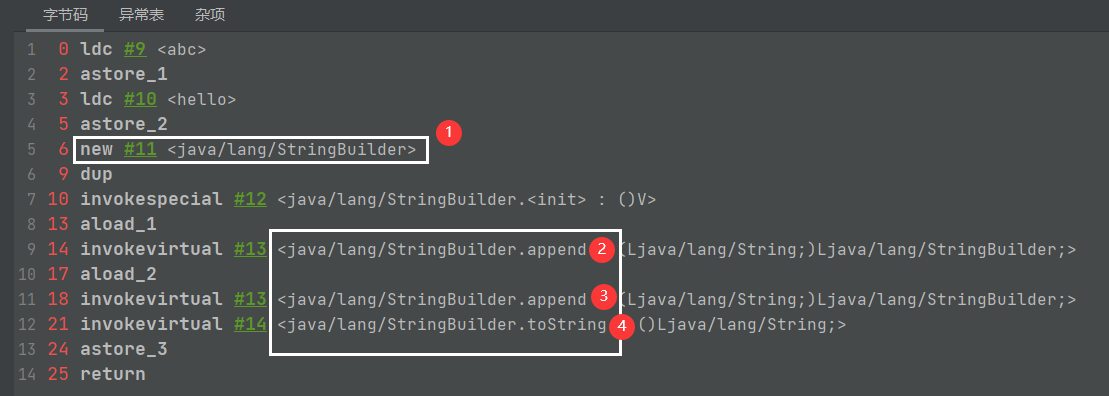
有变量参与的字符串拼接远离是StringBuilder的append方法,最后调用toString方法返回一个String。但是这里的toString方法底层的new String和平常的new String不太一样,他只产生new的对象放在堆中,不会在常量池中产生对象。
本文来自博客园,作者:长寿奉孝,转载请注明原文链接:https://www.cnblogs.com/tyt0o0/p/16753784.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix