ofaReporter-子域名报告生成工具
OneforallReporter
作者:Mi2ac1e
博客:https://www.cnblogs.com/tysec/
最近一直在看Key师傅的星球,偶然发现他曾经写了一个项目,在视频中叫"
Subdscan",但是似乎在网上的项目叫"SubDRepoter",在我眼中的亮点就是:生成的HTML报告可以直接看到网站的截图,这省了我大量的时间。于是就想着锻炼一下自己,模仿着写一个出来。(而且该项目在Key师傅的Github上似乎没有了...)
由于目前子域名收集我觉得不错的项目就是Oneforall,所以省略了自己再写一个子域名收集的功能了,用Oneforall真的太香了。
基于上述,我将该项目命名为Oneforall Reporter
0x01工具概述
能够针对Oneforall的json格式的结果生成一份报告,该报告包含:网站的截图,网站的标题,网站的域名(还可以直接点击就能打开),网站的IP,网站的状态
0x02程序架构

这里有一处写错了,存储url的txt文件名应该是与json的文件名一致
0x03代码实现
你可以使用Oneforall的
--fmt json来指定Oneforall输出为JSON格式,方便工具工作
1.创建项目目录
rname=input("[input]Named your Project,Don't use any symbol such as xx.com:")
pwd=os.getcwd()
os.mkdir(pwd+'/'+rname)
os.makedirs(pwd+'/'+rname+'/'+'Screen')
print("[info]The project has been established")
此处用了getcwd来获取当前路径,之后使用mkdir来创建第一层目录
之后使用makedirs来创建第二层目录:Screen用以储存屏幕截图
2.读取JSON中的URL
为了能够多个项目一起运行,修改了之前的代码,json文件名由用户输入:
import json
json_name=input("[input]Input your json file name such as:tysec Do not include suffixes: ")
def urlwrite():
with open(json_name+'.json','r',encoding='utf-8')as fp:
json_data=json.load(fp)
# print(json_data)
for urls in json_data:
f=open(json_name+'.txt','a+')
f.write(urls['url']+'\n')
urlwrite()
print("[info]Urls has been writen")
在这里我遇到了之前没了解的内容
首先载入json使用了:
json_data=json.load(fp) 此时json_data的数据类型为:list
即这种类型:[{'url':'https://www.target.com'},{'url':'https://target.com'}]
现在需要从字典当中取出url对应的值
所以需要使用:
for urls in json_data
此时的urls类型就是字典了
即{'url':'https://www.target.com'}
于是就可以使用urls['url']来取值,最后不要忘记:每个url换行:'\n'
3.读取
读取由第二步创建的$json_name$.txt
url_list=[]
f=open(json_name+'.txt','r')
for lines in f:
url_list.append(lines)
f.close()
print("[info]url list has been loaded")
url_list_lengh=len(url_list)
4.截图功能
网站截图功能作为本项目的最关键的地方,也算是耗时不少。首先就是这个ChromeDriver.exe 我的天...简直要命,尝试了互联网上的很多方法后,终于调用成功了:我将它放在了python安装目录,即可调用
代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
def ChromeDriverNOBrowser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
"""
在我把这个ofaReporter移植到我的攻击平台的时,他出现了这样的提示:
cannot find Chrome binary
你可以指定你的Chrome安装路径:
chrome_options.binary_location = "C:\Program Files\Google\Chrome\Application\chrome.exe"
你需要自己更改一下你的Chrome安装目录
"""
driverChrome = webdriver.Chrome(options=chrome_options)
return driverChrome
driver=ChromeDriverNOBrowser()
driver.set_window_size(1920,1080)
i=0
for i in range(int(url_list_lengh)):
try:
driver.get(url_list[i])
sleep(1)
#网页截图并保存
driver.get_screenshot_as_file(rname+'/'+'Screen/'+str(i)+'.png')
print("The"+str(i)+"pictrue has been capture")
except:
print("[--Error--]")
print("[info]Screen capture has been Finished")
5.生成报告功能
我使用jinja2来完成
你可以使用:pip3 install jinja2
python生成模板部分如下:
from jinja2 import Environment, FileSystemLoader
def generate_html(body,starttime):
env = Environment(loader=FileSystemLoader('./'))
template = env.get_template('template.html')#模板文件
with open(rname+'/'+"result.html",'w+') as fout:
html_content = template.render(start_time=starttime ,
body=body,
)
fout.write(html_content)
body = []
pic = []
k=0#用来链接图片
with open(json_name+'.json', 'r', encoding='utf-8')as res:
json_data = json.load(res)
for mdata in json_data:
picpath = {'pic_path': 'Screen/' + str(k) + '.png'}
mdata.update(picpath)
result=mdata
body.append(result)
k = k + 1
generate_html(body,2021)
print("[info]Finished")
我修改了一下程序中的一个小的BUG:之前的文章中这里写的是rname 后来才发现有一些大问题,应该是json_name
在这里需要解决的就是:将图片路径也添加到字典当中,这里我使用的update来实现将pic_path添加到读取的字典当中。最后直接将result添加到body列表当中
下面是jinja2的html模板:
懒人福利,直接引用了bootstrap4
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript" src="../js/jquery-3.5.1.min.js"></script>
<script type="text/javascript" src="../js/bootstrap.min.js"></script>
<script type="text/javascript" src="../js/popper.min.js"></script>
<link rel="stylesheet" type="text/css" href="../css/bootstrap.min.css">
<link rel="stylesheet" type="text/css" href="../css/style.css">
<title>OneforallReporter</title>
</head>
<body>
<div class="container">
<h1 style="text-align: center">Auth:Mi2ac1e</h1>
<h1 style="text-align: center">Report:{{start_time}}</h1>
</div>
{% for item in body %}
<div class="container">
<div class="row">
<div class="col-md-auto">
<img src="{{item.pic_path}}" class="pic">
</div>
<div class="col-md-auto">
<p style="font-size: 30px">{{item.title}}</p>
<a href="{{item.url}}" target="_blank" style="font-size: 25px">{{item.url}}</a><br><br>
<p style="font-size: 25px">IP:{{item.ip}}</p><br>
<p style="font-size: 25px">status:{{item.status}}</p>
</div>
</div>
</div>
<br>
{% endfor%}
<p style="text-align: center">本工具想法源自Key师傅曾提到的Subdscan</p>
</body>
</html>
{{start_time}}占位符,对应python中的:
html_content = template.render(start_time=starttime , body=body)
generate_html(body,2021)
即:最终会在{{start_time}}这里生成2021(后续打算把这个time变成生成项目的时间)
之后你应该用:
{% for item in body %}开始你的body部分
诸如{{item.title}} 这种,都是从前面的mdata字典中取出来的值,其中你的占位符item.xxx的xxx应该与字典的key值保持一致。
{% endfor%}最后结束你的body部分
这里有个小细节:我把a标签添加了target="_blank"他可以使得你点击链接就可以打开一个新的标签,而不是在当前选项卡打开新的网站。
0x04运行截图

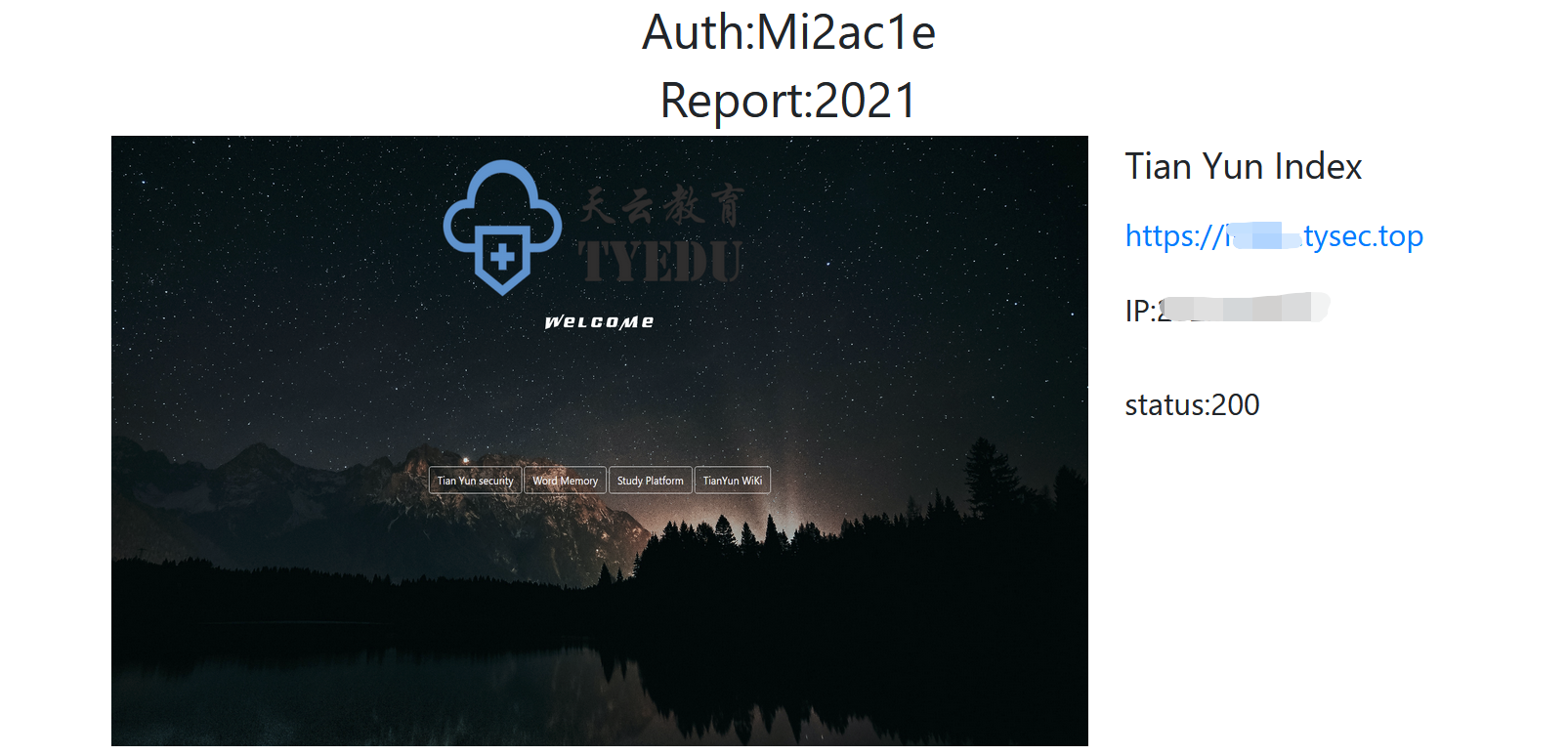
0x05不足
-
工具并没有对状态码进行筛选,404的页面,打不开的页面统统会被截图并被呈现到报告当中。
-
工具运行速度一般,有一些冗余代码
-
http,https重复截图
0x06总结与致谢
感谢Key师傅的之前某一次的分享,让我知道了这种思路并付诸实践。期间遇到了些小问题,也学习到了不少知识。当然目前的代码只能说停留在"能用,可以实现最基本的功能"当中。但优化并不是很好。下一步肯定需要优化一下代码。
0x07逻辑问题修复
1.当oneforall的报告中出现null时,程序没有对此有任何处理导致报错,这里的解决方法如下:
(json格式中为:"url":null 转化成字典则是:"url":None)
def urlwrite():
with open(json_name+'.json','r',encoding='utf-8')as fp:
json_data=json.load(fp)
print(json_data)
try:
for urls in json_data:
if(urls['url']!=None):
f=open(json_name+'.txt','a+')
f.write(urls['url']+'\n')
except:print("[Error]Something wrong")
添加了简单的判断,即如果url的取值不为None则往下进行。你应该使用None而不是'None'
2.图片错位
因为这里的图片顺序命名,导致如果出现url:Null可能会占位置,导致图片错位,于是这里使用了如下代码解决:
if (mdata['url'] != None):
picpath = {'pic_path': 'Screen/' + str(k) + '.png'}
mdata.update(picpath)
result=mdata
body.append(result)
k = k + 1
仍然是判断是否为None来确定是否进行下一步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号