

第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
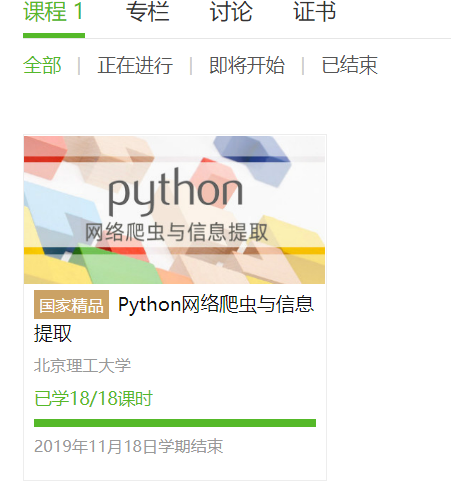
3.学习完成第0周至第4周的课程内容,并完成各周作业
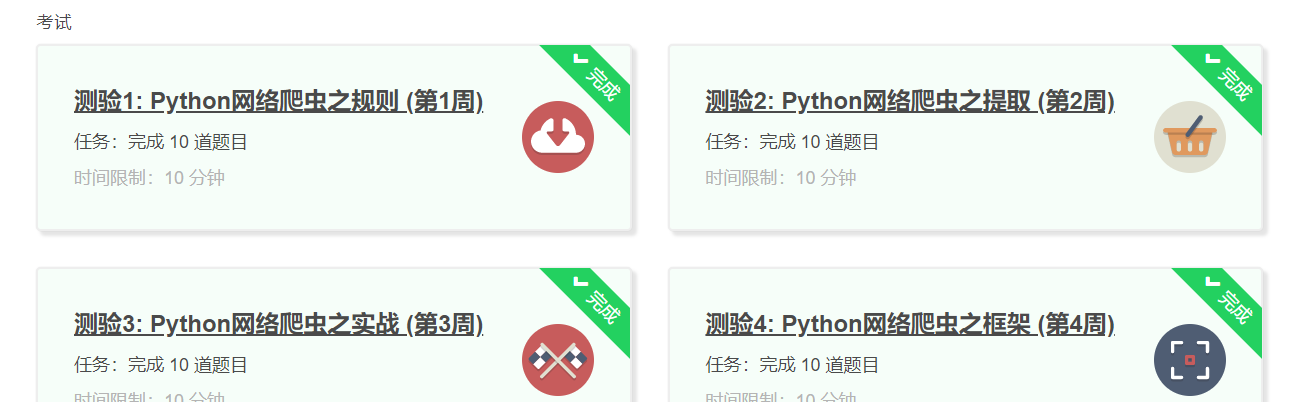
4.提供图片或网站显示的学习进度,证明学习的过程。

5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过这段时间学习python网络爬虫与信息提取,对于python的相比之前有了更多一些的了解,这门课教会了我挺多知识点,老师的讲课也很细心。通过这个课程我也知道了很多以前没有接触过的知识,了解到了什么是网络爬虫以及爬虫的作用。网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。爬虫可以作为通用搜索引擎网页收集器,做垂直搜索引擎,并且科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
第一周的时候我学习到关于requests库的7种主要方法:
1、requests.requests( )
2、requests.get()
3、requests.head( )
4、requests.post()
5、requests.put()
6、requests.patch()
7、requests.delete( )。
第二周的时候我学习到新的库—Beautiful soup库,用来格式化爬取下来的网页数据,hmtl标签树的格式化。有益于我们对爬取数据进行直观,简洁的分析。
第三周的时候我学习到了Beautiful Soup库解析器,有以下几种:
(1)bs4的HTML解析器
(2)lxml的HTML解析器
(3)lxml的XML解析器
(4)html5liblxml的解析器
第四周的时候我学习到了BeautifulSoup类的基本元素,有以下几种:
(1)Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾标签
(2)Name:标签的名字, <>...</p>的名字是'p' ,格式: <tag> . name :
(3)Attributes:标签的属性, 字典形式组织,格式: <tag>. attrs
(4)NavigableString: 标签内非属性字符串,<..</>中字符串,格式: <tag>.string
(5)Comment: 标签内字符串的注释部分, 一种特殊的Comment类型
在这几周的课程学习中,让我对网络数据爬取和网页解析的基本能力有了一个详细的梳理,从Requests自动爬取HTML页面自动网络请求提交——Robots.txt网络爬虫排除标准——Beautiful Soup解析HTML页面→Re正则表达式详解提取页面关键信息→scrapy框架。从requests库到scrapy框架的学习,让我意识到了Python的学习是一个漫长的过程,包含了许许多多的知识点,需要掌握的东西也很多,也让我感受到了爬虫在我们的日常生活中的重要性,现如今是互联网的时代,而网络爬虫已经成为自动获取互联网数据的一种主要方式,Python对于我的学习和工作都起到了很重要的作用,可以更有效率的去完成自己的工作目的,更快更好的对信息进行提取。通过这次课程的学习,我受益匪浅。获得了很多充实感,希望以后还能这样朝更好的方向前进,充实自己的知识,强化自身的能力。

